|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Формалізація та перероблення якісної інформації.Нечіткі множини
Якісний аналіз – один з важливих і визначальних етапів системного аналізу, це: збирання, систематизація, формалізація та переробка якісної інформації. Типові ситуації: - попереднє вивчення складного процесу та формування мети дослідження; - вибір найбільш важливих ефектів та характеристик (показників) процесу; - аналіз експериментальних даних з точки зору відповідності реальному процесу; - оцінка функціонування складних систем; - прийняття рішень в умовах невизначеності та в нечітко визначених ситуаціях і .д. Якісна інформація виражається за допомогою звичайної мови, але має нечіткий, наближений характер. Для використання комп’ютерних технологій необхідно співставити словесним термінам кількісні оцінки для формалізації даних та використання математичних методів обробки. Якісний етап системного аналізу має два аспекти – смисловий та математичний. Смисловий – збирання, оцінка достовірності, систематизація та формалізація інформації. Часто якісна інформація, її достовірність суттєво залежить від психічних та фізіологічних можливостей людини. В свідомості людини формується концептуальна модель як уявлення про стан та особливості об’єкта досліджень. Формалізація якісної інформації базується на експери-ментальних даних, які дозволяють співставити нечіткі уявлення та числові множини. В загальному випадку залучаються експерти, а в самому простому вважають, що множина Х складається з двох елементів {0,1}, наприклад “хороша” чи “погана” продукція. Так же технологічні параметри – “високий”, “низький” і т.д., але кожному з них відповідає своє числове значення. Математичний аспект якісного аналіза полягає в відображенні якісних уявлень в математичні об’єкти. Наприклад, коли об’єкт характеризується двома координатами стану Х1 і Х2, то можна прогнозувати величину Х2 при фіксованих значеннях Х1, а саме: “Якщо зміна величини Х1 велика, то зміна величини Х2 значна, в противному випадку Х2 змінюється мало”. Терміни “велике”, “значне”, “слабке” потрібно формалізувати. Технологічні параметри ТК та підсистем складають групи: - вимірювані автоматично (температура, тиск, рівень, інш.). Людина-оператор може на основі цих параметрів прогнозувати зміни параметрів в неконтрольованих точках, використовуючи нечітку інформацію; - параметри, які описуються словесними (нечіткими) термінами, а для їх переводу в числовий вид приймає участь людина – експерт (наприклад, якість продукції як інтегральна оцінка). Передбачається, що формалізація якісної інформації базується на існуванні відповідності між нечітко визначеними характеристиками та математичними об’єктами. Для першої групи параметрів це очевидно, величині параметра ставиться у відповідність числова координата в становленим початком координат та мірою, а величина параметра може описуватись словесно. Для параметрів першого типу елемент хiÎX – конкретні величини (наприклад температура). Кількісною характеристикою хiÎX є елементи uj ÎU. Множина U – діапазон зміни параметрів хiÎX. При словесному описуванні парі (хi, uj) ставиться у відповідність нечіткий термін qk ÎQ (Q – множина нечітких термінів). Нечіткі терміни, це – “високий”, дуже “високий”, “низький”, “далеко”, “близько”… На вибір цих термінів значний вплив справляє вибір опорної (реперної) точки – як правило для номінального режиму. При класичному підході до управління не приймаються до уваги такі фактори як неясність, невизначеність, нечіткість чи неточність, а саме вони є головними в реальному житті, для складних систем. Теорія нечітких множин Л.Заде дала схему розв’язання проблем, в яких суб’єктивна думка чи оцінка відіграють суттєву роль при оцінці фактів неясності і невизначеності. В 1965 р. американським математиком Л.Заде була запропонована теорія нечітких або розмитих множин, яка отримала назву нечіткої логіки. Ця теорія дала схему розв’язання проблем, в яких суб’єктивні думки або оцінка відіграють суттєву роль при оцінці фактів неясності або невизначеності. Автор теорії нечітких множин стверджував: “…при зростанні складності точні твердження втрачають значущість, а значущі твердження втрачають точність”. В технічній літературі нечітка логіка отримала назву від терміну “Fuzzy-Logic” (Фуцці-логіка). Теорія нечітких множин пройшла шлях від розробки формальних засобів представлення погано визначених понять, які використовуються людиною, та апарату для їх обробки до моделювання наближених міркувань, які використовуються людиною в повсякденній діяльності, та до створення комп’ютерів з нечіткою логікою. Перевага підходу нечіткої логіки перед класичними методами, при описуванні систем управління полягає в тому, що при цьому можна не використовувати аналітичних залежностей. В багатьох випадках достатньо лише професійного опису того, як процесом керує досвідчений оператор (без залучення математичних, хімічних і т.д. залежностей). Нечітка логіка – перша теорія, яка оперує неточними та не зовсім ясними поняттями. Передбачається, що в більшості випадків ситуація оцінюється приблизно, а не точно. Цей підхід появився об’єктивно тому, що при ускладненні систем зменшується можливість робити точні та значущі твердження відносно поведінки системи і наступає межа, за якою точність та значущість стають взаємновиключаючими характеристиками. Тоді вводяться спеціальні позначення (мітки), які визначають більш-менш нечіткі поняття. U – універсальна множина (довільний набір об’єктів чи математичних конструкцій); A – кінцева підмножина U з елементами U1, U2, … Un Тоді:
де Якщо всі
тоді А – розмита множина В розмитій логіці значення істинності може бути розмитою підмножиною будь-якої впорядкованої множини. Практично це розмита підмножина на інтервалі [0,1], тобто точка цього інтервалу. Лінгвістичні критерії істинності – “правильно”, “не зовсім правильно” можна інтерпретувати як мітки розмитих множин. Це відповідає природній мові, в якій більшість предикатів розмиті, а не чіткі. Тоді виникають модифікатори предикатів (“дуже”, “більш-менш”, “цілком” і т.д.), які відіграють важливу роль в генеруванні значень логічних змінних: “дуже високий”, “більш-менш важливий ”і.т.д. В класичних логічних системах є два квантори: існування та загальності. В розмитій логіці додатково до них використовуються квантори “декілька”, “головним чином”, “майже завжди”, “часто”… В розмитій логіці розмитий квантор інтерпретується як розмите число чи розмита пропорція Приклад: ріст людини. Для поняття “високий” визначено функції залежності:
-0,2 0 1,2 1,4 1,6 1,7 1,8 1,9 2 2,1 2,2 м
Рис.4.1. Розмита множина при визначенні росту
Лінгвістична змінна – це така змінна, яка задається на кількісній шкалі і приймає значення у вигляді слів та словоутворень природної мови. Окреме значення лінгвістичної змінної або лінгвістичне значення називається термом і задається за допомогою функції належності тобто кожному терму відповідає нечітка множина. Значення лінгвістичної змінної (ЛЗ) описується нечіткими змінними. Лінгвістичні змінні (ЛЗ) використовуються для якісного словесного опису кількісної величини. Будь-яка ЛЗ та всі її значення зв’язані з конкрет-ною кількісною шкалою (базовою шкалою). Приклад базової шкали для оцінки степені руйнування об’єкта:
незначне помірне сильно катастрофічне
Масштаб шкали може бути довільним. Для віку: Т(вік)={молодий, старий, дуже молодий, більш-менш молодий…} Кожний елемент (терм) цієї множини може виражатись через розмиту множину, наприклад:
m молодий не дуже молодий більш-менш старий
дуже
30 60 вік
Рис.4.2. Функції належності
Значення лінгвістичних змінних можуть задаватись не лише базовою шкалою, а й функцією. Наприклад, функції належності допустимих лінгвістичних термів можна задати функцією: a та константа в чисельнику залежить від характеру лінгвістичної змінної. Так для значення “високий” функція має вигляд:
а “досить високий”: “майже високий”: “середній”: “досить низький”: Для управління на базі нечіткої логіки (фуцці-управління) характерним є безпосереднє застосування експертних знань, які формуються якісно, для генерування необхідних впливів на об’єкт. Знання щодо взаємодії з процесом за цією методикою подаються у формі правил виду: ЯКЩО (початкова ситуація), ТО (відповідна реакція) Така логічна конструкція відповідає природній поведінці людини в конкретній ситації, наприклад: ЯКЩО (температура висока), ТО (зменшити дещо подачу пари) Або: ЯКЩО (температура висока) ТА (швидкість зростання температури значна), ТО (припинити подачу пари). Використовуючи функції належності, можна записати такі вирази: М=m1|х1+ m2|х2+…, (4.6) де М – сукупність об’єктів, які належать основній множині Х; Х- об’єкти множини М. Цей вираз – не алгебраїчна сума, а лише визначає, що елементи Хі відносяться до множини М з функціями належності mі. Це може бути формою запису математичної моделі в нечіткому середовищі. Можна записати також: М=|( х1,m1), (х2,m2)…, (хі,mі) | (4.7) По аналогії із звичайними множинами в нечіткій логіці формуються основні операції над множинами А та В - множина логічного об’єднання С=А U В (АБО): μс(х)=max (μА(х), (μВ(х)); (4.8) - множина логічного перетину (ТА) С=А ∩ В: μс(х)=min (μА(х), (μВ(х)); (4.9) - множина логічного доповнення (НІ)
μс(х)=1-μА(х); (4.10) Головною операцією нечіткої логіки є процедура нечіткого висновку, за допомогою якої з нечітких умов отримують наближені рішення (розв’язки). Процедура нечіткого висновку заснована на операції логічного слідування (імплікації), яка використовується в традиційній математичній логіці. Імплікація дозволяє формалізувати знання експерта за формою “якщо А, то В”, де: А – передумова, В – висновок. Стосовно нечіткого управління Х –базова множина значень х регульованої змінної (координати). Тоді Х- базова множина х, А – множина значень х; U – базова множина значень управлінь u, В –множина значень u. В залежності від способу отримання логічних висновків з нечітких правил можуть бути різні регулятори. Для промислового використання частіше використовується алгоритм нечіткого регулятора Мамдані, коли регятор формує чітке однозначне управління за допомогою процедури дефазифікації. Початковими даними для такого алгоритму є:
- висновок n правил В1, В2... Вn з відповідними функціями належності; - конкретні значення х В результаті необхідно отримати управління U - за допомогою основних операцій визначають значення істинності передумов n правил µА1(х - враховується, що у відповідності з основним правилом логічного висновку істинність висновку В не може перевищувати істинність передумови А, тому µВ(U) обмежується зверху на рівні µА(х µВ х Î А µВ
- здійснюється агрегування кількох правил “ЯКЩО...ТО...” шляхом максимізації функцій належності всіх об’єднуваних правил. В результаті функція належності управляючого діяння буде: µВp (y)=max{µBj (U)}, j Î (1,n); (4.13) - здійснюють процедуру дефазифікації для знаходження конкретного значення управління. Серед різних методів найбільш розповсюдженим є метод центра ваги, коли у Таким чином дефадзифікація – процедура генерування управлінь. Це управління на виході фуцці-контролера (нечіткого регулятора) отримують як нечітку множину в формі функцій належності. Метод центра ваги передбачає, що управління обчислюється як значення абcциси центра ваги площини, яка утворена функцією належності та віссю абцис.
Функції належності Вибір виду функцій належності та їх параметрів значною мірою визначається досвідом, інтуїцією та іншими суб’єктивними факторами, в тому числі особою, яка приймає рішення – (ОПР). Тут саме і виникають нові невизначеності суб’єктивного характеру. Приклади. -
  функції степенів належності твердження “величина х мала” функції степенів належності твердження “величина х мала”  , (4.15) , (4.15)
а х 0
   
.
     
m(х)= а1 а2 - функції степенів належності твердження “величина х велика”
а
μ
х α α+1/к
- функція степенів належності твердження “величина |х| мала”
m(х)= х -α α Те ж, “величина |х| велика”
х -α α Функція степенів належності може задаватись: - самостійно дослідником, на основі власного досвіду; - в простому випадку; - із залученням експертів, обробкою іх оцінок – для складних та відповідальних випадків. Важливість використання логіко-лінгвістичних змінних обумовлена причинами: - не всі критерії оптимізації можуть задаватись кількісно; - між рядом параметрів, які впливають на функціонування АТК, не вдається встановити точних кількісних залежностей; - процес оптимізації в АТК – багатокроковий, а зміст кожного кроку не завжди можна визначити однозначно; - існуючі способи опису самих АТК (їх структури) та процесів в них – дають громіздкі залежності, їх важко або неможливо використовувати; - в змінюваних умовах зовнішнього середовища та властивостей АТК утруднюються процеси адаптації, тим більше, що окремі підсистеми мають активну природу, тобто є людино-машинними. Процедури завдання дослідником функції належності в нечітких підмножинах: - визначається діапазон зміни величини параметра х Î Х з множини Ω; - знаходять відображення φ: Ω→U, де U Î [0,1]. В якості φ може бути використане будь-яке перетворення, зокрема лінійне; - величина параметра х Î Х описується словесно множиною термінів Q, наприклад QΔ= {високий, дуже високий, не високий, низький, дуже низький і.т.д.}. Потрібно, щоб в Q були відсутні терміни – синоніми, в противному випадку проводять їх класифікацію у відповідності з термінологією, яка існує в цій галузі (температура 1200 в цукровій промисловості – висока, в металургії – дуже низька); -
- функції належності μj(U), j=1, (2n+1), встановлюють відповідність Q→U з точністю до якісних відмінностей первинних термінів та прийнятих операцій над нечіткими множинами; - термін “норма”, тобто q0 Î Q і u0 Î U визначає і форму функції μ(U), а також вимагає виконання таких асимптотичних властивостей: lim μ(U)=a; lim(U)=b (4.22) U→0 U→1 a, b – постійні для даного терміна.
0,5
U Uа U0 Ub 1
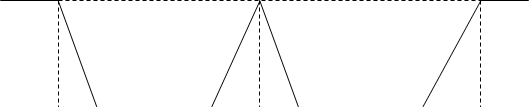
Рис.4.3. Функція степені належності μ(U), яка формалізує термін «високий»
U0 – опорний елемент U0 Î U, який відповідає поняттю “норма”. Як правило – це 0,5 ( μ(U0)=0,5). Звичайно, тут є значний суб’єктивізм відносно вибору U0 Умова lim μ(U)=0 означає, що елементи U‹ U0 в меншій степені U→0 можна віднести до терміну “високий”, чим U0. Умова lim μ(U)=1 показує, що для U › U0 степінь належності до U→1 терміну “високий” зростає. Нечітка множина, яка формується, вважається нормальною при sup μ(U)=1 (4.23) u Î U Враховуючи асимптотичні властивості функції μ(U), дослідник може встановити інтервали [0,Ua] та [Ub,1], на яких функція задається чітко класифікацією μ(U)= Найскладніше задати μ(U) при U Î[ Ua, Ub]. На цьому інтервалі для будь-якого U Î[ Ua, Ub] дослідник задає μ(U) в залежності від різниці (U-U0) з урахуванням знаку. Приймається, що функція μ(U) є монотонною, а розриви можуть бути за умови, що в процесах трапляються “катастрофи”, тобто система стає нестійкою. Для визначення функцій степені належності експертами рекомендуються такі процедури: 1.Виділення точки u1 Î U на універсальній шкалі, яка, за думкою експерта, точно відповідає нечіткій множині. В цьому випадку μ(U1)=1. Це розглядається на випадок, коли для формалізації термінів приймаються три елементи Ui(і=1,3) універсальної множини U. Для зменшення психологічного навантаження на експерта кількість термінів необхідно зменшувати. На рис. – спосіб завдання функцій належності, за допомогою яких формалізуються поняття “низький”, “середній”, “дуже високий”.
μ(
u u u
U1 U3 U2 U1 U3 U2 U1 μ1 – “низький” μ2 – “середній” μ3 – “дуже високий”
2.Знаходження на універсальній шкалі зліва та справа від U1 точок, які, на думку експерта, не можна відносити до цього терміну. Це точки U2 та U3, для яких μ(U2)= μ(U3)=0. 3. Графічна побудова функцій за обраними точками при умові лінійної апроксимації. 4. Виділення підмножини U1 ≤ U, на якій визначена формалізація терміну, U1=[ U2 ,U3]. Часом точки U2, U3 можуть відноситись в нескінченність. Це – один з найбільш простих способів. При управлінні технологічними установками діапазон зміни кожного параметра задається відрізком (технологічні параметри – нечіткі підмножини деяких універсальних множин) хі=[aimin, аіmax]; уі=[bjmin, djmax] кожен з відрізків розбивають на інтервали, наприклад: aimin=ai1 ‹ a i2 ‹...‹ aik= аіmax Значення величини параметра, яке знаходиться в одному з інтервалів, словесно характеризують термінами “малий”, “середній”, “великий”. Тоді функція належності в нечітких підмножинах, які формалізують прийняті терміни, описують залежністю: μ(хі)=exp(-Qi| xi - aip1|) (4.25) Q – постійна величина, яка знаходиться при ідентифікації функції належності: аір1=(аіr+ аіr+1)/2
Приклад
Поиск по сайту: |
 ,
,
 , - кінцева множина впорядкованих пар;
, - кінцева множина впорядкованих пар; - міра членства, функція належності, яка показує степінь належності елемента цій множині.
- міра членства, функція належності, яка показує степінь належності елемента цій множині. {0, 1}, тобто дорівнюють 0 чи 1, то це звичай-на (чітка) множина. Якщо
{0, 1}, тобто дорівнюють 0 чи 1, то це звичай-на (чітка) множина. Якщо  не належить множині;
не належить множині; U;
U; - визначає степінь належності
- визначає степінь належності 






 0
0


 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0





 немає
немає (Ui)
(Ui)



 1,0
1,0

 молодий старий
молодий старий
 0,5
0,5
 , (4.1)
, (4.1) , (4.2)
, (4.2) , (4.3)
, (4.3) , (4.4)
, (4.4) ,
, , (4.5)
, (4.5) - антецеденти n правил А11,12... А1n, А22...А2n, Аn2...Аnn, які відповідають функціям належності μ і зв’язані логічними операціями кон’юкції (∩), диз’юкції (U) чи інверсії ( );
- антецеденти n правил А11,12... А1n, А22...А2n, Аn2...Аnn, які відповідають функціям належності μ і зв’язані логічними операціями кон’юкції (∩), диз’юкції (U) чи інверсії ( ); , х
, х  ... х
... х 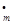 вхідних змінних х1, х2...хm.
вхідних змінних х1, х2...хm. , для чого:
, для чого: (U)=min{µАn(х
(U)=min{µАn(х  , (4.14)
, (4.14)


 (4.17)
(4.17)


 μ
μ  (4.18)
(4.18) х
х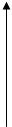




 (4.19)
(4.19)



 μ
μ (4.20)
(4.20)

 m(х)=
m(х)=  (4.21)
(4.21) на множині Q вводиться термін q0 Î Q – “норма”, а відносно нього симетрично визначається терміном qк Î Q, к=1,n та протилежні ім за смислом qe Î Q, e=1,n;
на множині Q вводиться термін q0 Î Q – “норма”, а відносно нього симетрично визначається терміном qк Î Q, к=1,n та протилежні ім за смислом qe Î Q, e=1,n;





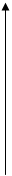 μ(U)
μ(U) 1
1 (4.24)
(4.24)



 )
exp(-
)
exp(-  )
exp(-
)
exp(-  )
)
 )
...| y1 - 483,75|
...| y1 - 487,5|
)
...| y1 - 483,75|
...| y1 - 487,5|