|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Экспериментальные модели недетерминированных объектов
Разброс выходных величин при эксперименте вызывается такими факторами, как: 1. Систематические погрешности (дрейф нуля, влияние температуры, влажности). 2. Пороговое действие неучтенных факторов (то есть, то нет). 3. Отклонение случайного характера (случайные помехи, шумы). Систематические погрешности устраняются путем увеличения числа опытов, изменением их порядка чередования. Порогово-дискретный фактор устраняется путем сглаживания экспериментально полученных зависимостей по способу скользящего среднего. Для каждого значения аргумента вычисляются сглаженные значения функции по формулам: – для х1 – для х2 Сложнее бороться со случайными помехами. Обычно в прямоугольных координатах строятся экспериментально полученные зависимости, искаженные помехами. По их виду (линейная, нелинейная, возрастающая, убывающая) задаются уравнения регрессии. Затем, как обычно, по методу наименьших квадратов и частных производных определяются его коэффициенты и оценивается адекватность модели объекту. Так как экспериментальные значения параметров получены со случайными погрешностями, то и сами модели, их коэффициенты являются случайными величинами. Чем меньше разброс параметров во время эксперимента, тем выше достоверность модели. В соответствии с теорией вероятности, при стремлении числа опытов к бесконечности, интервал между измерениями стремится к нулю, а достоверность – к единице. Следовательно, планирование эксперимента для идентификации недетерминированного объекта должно определять объем и число повторений экспериментов, при которых будет обеспечена заданная достоверность модели. Задачи эти решаются с применением аппарата теории вероятности и математической статистики, корреляционного и регрессивного анализов, где численной мерой объективной возможности наступления какого-то события является вероятность. Она определяется теоретически как отношение возможного числа событий с интересующим нас исходом m к общему числу возможных событий M: Рсоб = т / М . (3.12) Ни m, ни М в общем случае неизвестны. Поэтому вероятность определяется экспериментально и называется статистической вероятностью: P = n / N , где n – число опытов, где наблюдался интересующий нас результат; N – общее число проведенных опытов. При N → ∞ разность Рсоб – P стремится к нулю (теорема Бернулли). События бывают: – достоверные Р = 1; – невозможные Р = 0; – случайные 0 < Р < 1; – совместные (одновременные); – несовместные; – зависимые – появление одного меняет вероятность появления другого. – независимые. Основные правила наступления простых независимых событий: 1. Вероятность совместного наступления нескольких простых независимых событий равна произведению вероятностей наступления каждого из них:
2. Вероятность наступления одного из нескольких несовместных событий равна сумме вероятностей наступления каждого из них:
Случайные события, кроме вероятности, характеризуются временем tк, в течение которого происходило k событий. При изменении случайной величины очевидно изменение и вероятности ее наступления. Связь случайной величины с вероятностью ее появления математически описывается законами распределения случайных величин. Эти законы определяются по результатам статистической обработки экспериментальных данных и зависят от характера объекта. Законы распределения представляются в виде интегральной F(x) или дифференциальной f(x) функций распределения. Первая определяет вероятность того, что случайная величина не превышает некоторого фиксированного значения, то есть находится в интервале ( - ∞, в):
вторая – связана с первой дифференциалом вида:
то есть она определяет скорость или плотность изменения вероятности при изменении случайной величины х. И наоборот функция – F(x) связана с f(x) c помощью интеграла:
Вероятность нахождения случайной величины х в интервале а – в определяется как интеграл с пределами от а до в:
то есть вероятность нахождения х в интервале а – в определяется площадью под графиком f(x) от х = а до х = в. Рассмотрим некоторые из законов распределения случайных величин рис. 3.2.
F(x) 1 f(x) 3
0 а в с х 0 а б с х А) б) Рис. 3.2. Графики распределения F(x) (а) и f(x) (б)
1 – кривая равномерного закона распределения случайной непрерывной величины; 2 – кривая экспоненциального закона распределения случайной непрерывной величины; 3 – кривая нормального закона распределения случайной непрерывной величины. Функции на рис. 3.2 описываются следующими уравнениями: – функция F(x): F1(x < a) = 0, F1 (a < x <в) = (х – а) / (в – а), F1 (x > в) = 1, F2 (x) = 1 – е – 2х, F3 (x) = Здесь с – точка на оси x, соответствующая перегибу характеристики F(x), параметр σ зависит от остроты характеристики f(x); – функция f(x): f1(x < a) = 0, f1 (a < x < в) = 1 / (в – а), f1 (x > в) = 0, f2 (x) = λ е – λ х, f3 (x) = Законы распределения кроме F(x) и f(x) характеризуются следующими численными характеристиками случайных величин, по которым можно судить о том или ином законе распределения: 1. Математическое ожидание М(х) – величина вокруг, которой группируется большинство случайных значений, то есть это усредненные по вероятности значения случайной величины: – для дискретной величины – для непрерывной величины Пределы изменения х могут быть ограничены, исходя из допустимых значений параметра х (например, от а до в). 2. Мода М0(х) – наиболее вероятное значение случайной величины: х = М0 при f(x) = мах. 3. Медиана МЕ(х) – величина, для которой справедливо равенство Р(х < МЕ ) = Р(х > МЕ ), то есть значение х, делящее площадь f(x) пополам. 4. Отклонение: δ(х) = xi – М(х). 5. Дисперсия: σ 2(х) = М(х)×(xi – М(х))2. 6. Среднеквадратическое отклонение:
7. Моменты случайной величины: а) начальный νq = М(хq); в) центральный μq = М(х)×(xi – М(х)) q. При q = 1 начальный момент равен математическому ожиданию, при q = = 2 центральный момент равен дисперсии. 8. Коэффициент асимметрии: γ3 = μ3 / σ 3(х). 9. Коэффициент эксцесса: γ4 = μ4 / σ 4(х). Численные характеристики случайных величин некоторым образом используются при обработке данных эксперимента и анализе законов распределения. Аналогичные понятия применяются к случайным величинам, подчиняющимся многомерным законам распределения. Связь между случайными переменными устанавливается с помощью методов корреляционного анализа. Сущность корреляционного анализа заключается в установлении статистической связи между случайными переменными и количественной оценкой ее тесноты. Самый распространенный способ оценки тесноты статистической связи между переменными это определение корреляционного коэффициента:
Здесь
где п – общее число опытов; nx i – число опытов, в которых x = xi. Аналогично определяется σ(у). При линейной зависимости у от х корреляционный коэффициент максимальный и равен 1 при у = а0 + а1х или “-1” при у = а0 – а1х. Чем меньше статистическая связь между у и х тем меньше r. При полной независимости у от х r = 0. При изменении у значение х не меняется или принимает симметричные значения относительно М(у), то есть числитель в выражении r равен нулю. Так как экспериментальные данные у и х являются случайными величинами, то и рассчитанный коэффициент корреляции r является случайной величиной. Значимость r проверяется путем сравнения расчетной величины критерия Н,
с данными таблицы критерия Н, вид которой представлен ниже:
Например, определили с помощью 10 опытов, что r = 0,7, вычислили Н = 2,1. По таблице Н определяем, что с вероятностью (достоверностью) более чем Р= 0,95 (погрешность менее 5%) можно принять гипотезу о линейной зависимости у от х. Когда установлена связь двух переменных, их теснота и достоверность (вероятность связи), приступают к получению модели объекта в виде уравнения регрессии требуемой достоверности. На каждом интервале xi = ± ∆x по данным эксперимента вычисляется
Поиск по сайту: |
 ;
; и т.д.
и т.д. (3.13)
(3.13) (3.14)
(3.14) , (3.15)
, (3.15) , (3.16)
, (3.16) .
. ,
,
 2
2 .
. .
. ;
; .
. .
. .
.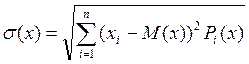 , Рi(x) = nx i / n,
, Рi(x) = nx i / n, ,
, . В результате получают точки линии регрессии y на x и при необходимости выполняют сглаживание этой линии. Далее выполняются действия аналогичные действиям по получению моделей детерминированных объектов, только с многократным повторением каждого опыта, с вычислением математического ожидания, дисперсии, с проверкой их достоверности и однородности по различным критериям.
. В результате получают точки линии регрессии y на x и при необходимости выполняют сглаживание этой линии. Далее выполняются действия аналогичные действиям по получению моделей детерминированных объектов, только с многократным повторением каждого опыта, с вычислением математического ожидания, дисперсии, с проверкой их достоверности и однородности по различным критериям.