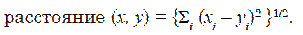|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Дифференциальная характеристика особенностей эмоционально-нравственной сферы личности на поздних этапах онтогенеза
Общая задача, которую мы решали на завершающем этапе исследования, состояла в том, чтобы организовать наблюдаемые данные в наглядные структуры, то есть развернуть таксономии. С этой целью мы провели статистическую работу по группировке испытуемых на незаданные группы. Таким образом, мы конкретизировали задачу в следующей формулировке: имеется многомерное психологическое описание выборки испытуемых и требуется осуществить их разделение на однородные группы, то есть такое разделение (дифференциацию), при котором в составе выделенных групп оказались бы испытуемые, похожие по психологическим характеристикам. Такая постановка задачи группировки испытуемых соответствует прогнозируемым в психологическом исследовании представлениям о типе личности. Для решения этой задачи используются методы автоматической классификации, которые разработаны для анализа структуры взаимного расположения испытуемых в пространстве измеряемых признаков. Они позволяют производить объективную классификацию испытуемых по большому набору признаков. Если представить каждого испытуемого в виде точки в многомерном пространстве признаков, то естественно предположить, что геометрическая близость точек в этом пространстве указывает на похожесть соответствующих испытуемых. Под структурой множества испытуемых в этом случае понимается взаимное расположение этих скоплений, их размеры и число испытуемых в каждом скоплении. В результате разбиения множества испытуемых на типы, соответствующие скоплениям похожих испытуемых, получается описание распределения испытуемых в терминах выделенных типов. В этом случае каждый испытуемый характеризуется уже не исходным набором признаков, а принадлежностью к тому или иному типу. Для классификации на дифференцированные группы используется несколько математических моделей, относящихся к кластерному анализу, основными среди которых являются: а) построение иерархической кластерной структуры, дающей наглядную картину группировки испытуемых; б) метод K-means, преимуществом которого является возможность задавать степень близости групп, испытуемых внутри группы, число самих групп и прочие характеристики модели, причем в больших вариантах, чем при обычной кластеризации. В нашем исследовании мы применили последовательно обе эти модели кластеризации данных испытуемых. В условиях неопределенного количества типов наиболее адекватной процедурой является построение иерархической структуры. На рис. 2 представлен график, полученный с помощью математической модели расчетов евклидового расстояния полученных данных, относящихся к каждому из опрошенных нами в ходе тестирования пожилых респондентов. Евклидово расстояние является геометрическим расстоянием в многомерном пространстве и вычисляется следующим образом:
Математическое обеспечение всей работы по кластерному анализу осуществлялось с применением компьютерной программы «STATISTICA». Как показали результаты иерархической кластеризации, представленные на рис. 2, данные большинства испытуемых в целом достаточно гомогенны, и существенных различий для большинства не обнаружилось, о чем свидетельствует плавнокаскадная структура графика и отсутствие отчетливо выделенных узлов (в которых и формируется кластер). При изучении графика установлено не более трех неявных узловидных образования, что и послужило основой для выдвижения гипотезы относительно числа кластеров (по наблюдениям). При этом мы констатировали, что в предполагаемых кластерах существует много схожих аспектов.
Рис. 2. Вертикальная древовидная диаграмма результатов кластеризации данных
В дальнейшей обработке мы использовали метод кластеризации К-средних, который позволил образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода К-средних, который строит ровно К различных кластеров, расположенных на возможно больших расстояниях друг от друга. В таблице 12 представлены общие статистические характеристики полученных кластеров.
Таблица 12
Поиск по сайту: |