|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Лекция 15-16. Видеосистема
Технология графических карт Современные трехмерные ускорители работают с так называемой полигональной графикой, то есть любой объект представляется как набор плоских многоугольников (Практически всегда эти многоугольники рано (еще в драйверах) или поздно (в видеокарте) разбиваются на простейшие треугольники. На то есть много причин — удобство работы, ограниченные возможности оборудования, но главная — большинству алгоритмов закраски изображения нужно, чтобы полигоны были плоскими, то есть чтобы все их вершины лежали в одной плоскости. А для треугольников это требование выполняется автоматически). Объект задается вершинами, определяющими ключевые точки, и полигонами, которые образованы линиями, соединяющими вершины. Цвет на полигоны накладывается по специальным алгоритмам — как правило, с использованием заранее нарисованных плоских изображений — текстур. Процесс этот называется закраской. А задача 3D-акселератора сводится к тому, чтобы за заданный промежуток времени нарисовать и закрасить как можно больше полигонов (в новейших играх на экране одновременно присутствуют несколько сотен тысяч треугольников, формирующих сцену). Для отображения треугольников используется математический аппарат так называемых однородных координат. Не вдаваясь в подробности — требуется один раз рассчитать пару матриц 4x4 (матрицы преобразования и проектирования), после чего расчет положения любой точки трехмерной сцены на плоском экране сведется к умножению вектора исходных координат на эти матрицы — всего-то 32 умножений, 24 сложений и 3 деления! У современного процессора на эти операции уйдет 20–40 тактов (За один такт можно выполнить сразу несколько операций), а если задействовать векторные операции (например, SSE/2, которые позволяют работать с векторами длины 4), то и вовсе хватит 8–10 тактов (для сравнения: одно обращение к оперативной памяти занимает от 100 до 350 тактов процессора). Это, конечно, без учета «накладных расходов», но все же очевидно, что процессор с рабочей частотой под 3 ГГц запросто может просчитать за секунду координаты десятка миллионов точек — очень много даже по меркам современных игр (в оперативной памяти эти точки займут не меньше 60–120 Мбайт). К сожалению, картинка из одних лишь вершин (и даже вершин, соединенных ребрами) удовлетворит далеко не всех пользователей. Но именно с нее все и начиналось.
Проекция геометрической модели сферы, приближаемой по большим кругам 32-угольниками. В ней — тысячи граней и примерно столько же вершин. Картинки 4 и 6 рассчитаны чисто геометрическими методами (сортировка треугольников), без привлечения ресурсов 3D-ускорителя и использования Z-буфера. 200 тысяч треугольников, образующих график, процессор AMD Athlon XP 2500+ обсчитывает со скоростью около 3–5 fps без каких-либо оптимизаций. Итак, изобразить «геометрию» сцены не составляет особого труда — акселератор для этого не нужен. Трудности начинаются, когда мы хотим сцену закрасить. Если на проекции полигонов просто-напросто наложить один тон, на экране получится что-то совершенно невразумительное. Если же присвоить каждому полигону свой цвет (и при этом, например, учесть освещенность объекта), то мы увидим (Здесь есть еще «проблема удаления невидимых поверхностей» — когда нужно определить, какой из перекрывающихся полигонов к нам «ближе» (и потому должен рисоваться поверх собрата). Существуют чисто геометрические подходы к ее решению (например, тайловый подход, tiling), но чаще всего эту стадию совмещают с закраской (техника буфера глубины, Z-buffer)) уже нормальный объемный объект. И хотя таким способом можно получать очень красивые изображения, это все же не то, чего мы хотим добиться . Радикально решает проблему использование текстур — картинок, «натянутых» на полигоны. К сожалению, в этом случае для каждой точки экрана, попавшей в треугольник сцены, нужно найти текстурные координаты (а это не слишком быстрый процесс) и провести так называемую выборку из текстуры — вычислить цвет текстуры в полученной точке. Последняя задача не так проста, как кажется: чаще всего расчетная точка получается не целочисленной и попадает «между пикселами» изображения. В итоге расчеты получаются гораздо более трудоемкими, нежели «прямолинейное» геометрическое преобразование, да и выполнять их приходится чаще — в полигон может попасть не одна сотня точек, и для каждой из них может потребоваться не одна текстура. На экране может присутствовать всего сотня треугольников, но, чтобы обеспечить жалкий десяток кадров в секунду в разрешении 1024x768, графическому процессору все равно придется рассчитывать как минимум 7–8 миллионов точек в секунду! Вдобавок текстуры зачастую являются очень большими изображениями и, в отличие от ограниченного набора геометрической информации, в кэш-память процессора не помещаются, вынуждая его непрерывно обращаться к не столь быстрой оперативной памяти. Таким образом, закраска становится «бутылочным горлышком» при отрисовке сцены, и именно для аппаратного ускорения соответствующих операций были созданы первые 3D-акселераторы. Методы фильтрации Вычисление цвета точки, попавшей «между» известными точками текстуры, называется фильтрацией. Если используется простейший способ — выбрать ближайшую к расчетной точку текстуры, — фильтрация не нужна. Если считается взвешенное среднее арифметическое четырех ближайших «соседей» точки, это билинейная фильтрация. Самый «продвинутый» способ фильтрации — анизотропная (неоднородная по разным направлениям), в которой учитываются и «физические размеры» пиксела, то есть считается не просто проекция центра пиксела экрана на текстуру, а пиксела целиком. Чем выше «кратность» анизотропной фильтрации, тем проекция точнее. Использование простых способов фильтрации приводит к тому, что текстуры в определенных ситуациях «размываются», теряют четкость. И напротив, чем качественнее фильтрация, тем более четко прорисовываются объекты. А вот трилинейная фильтрация — это немного другое. Дело в том, что для оптимизации текстурной выборки, как правило, применяется техника мип-текстурирования — когда для близкорасположенных объектов используется большая и подробная текстура, а для удаленных — ее упрощенные копии. Это хорошо заметно на гоночных симуляторах — четкая полоса дорожной разметки по мере удаления от гонщика расплывается и в конце концов исчезает. Чтобы не было видно резких скачков от одного мип-уровня к другому, на переходах («не близко и не далеко») ускоритель считает линейную комбинацию цветов, вычисленных по «ближним» и по «дальним» текстурам, — это и называют трилинейной (Когда разрабатывалась эта техника, основной фильтрацией была билинейная. Вот фильтрацию с использованием мип-уровней и назвали «трилинейной» — билинейной по текстуре и линейной по текстурам. Даже потом, когда появилась анизотропная фильтрация, для некоторых ускорителей можно было либо использовать ее без трилинейной, либо использовать трилинейную, но с обязательной билинейной фильтрацией. Сегодня, конечно, таких проблем уже нет — «трилинейка» и «анизотропка» прекрасно уживаются вместе) фильтрацией. Эволюция ускорителей Взгляните еще разок на рис. 5. Вам не кажется, что это изображение выглядит неестественно? Наша сфера ничем не освещена. Попробуем исправить это упущение чисто геометрическими методами — посчитаем освещенность каждого полигона (рис. 7). Прибавилось естественности или нет, сказать трудно, поскольку плоские грани объекта стали чересчур рельефными. Можно, конечно, увеличить число полигонов в 16 раз (рис. 8). Однако целесообразнее прибегнуть к другому приему — рассчитывать освещенность объекта в его вершинах и интерполировать ее на внутренние точки граней (метод Гуро, Gouraud method). Это и быстрее, и картинка получается лучше (рис. 9). Именно такой подход лег в основу «ускорителей с фиксированным конвейером», а проще говоря — видеокарт «поколения DirectX 7». Первые ускорители рассчитывать освещенность не умели, что, впрочем, отнюдь не мешало разработчикам создавать вполне реалистичные игры, даже с тенями. Игровой движок сам заблаговременно рассчитывал освещенность объектов и создавал соответствующие текстуры освещения (light maps) — то есть ускоритель рисовал уже просчитанные блики света. Для статического освещения (и неподвижных объектов) — неплохой вариант, но вот для динамики — немножко не то: представьте себе монстра, одинаково хорошо видного и в темных, и в светлых уголках комнаты. Поэтому все современные игры освещение (хотя бы частично) рассчитывают на лету. Чтобы снизить нагрузку на центральный процессор, 3D-ускорители (по мере роста производительности и сложности) получили аппаратный блок геометрических вычислений — так называемый Hardware Transform & Lightning (T&L), рис. 10.
Внутреннее устройство 3D-ускорителя Как же видеокарта реализует графический конвейер? Взглянем на рисунок. Сердце графического процессора (Graphics Processing Unit, GPU) — один или несколько так называемых пиксельных конвейеров (pipelines), которые, собственно, и заняты операциями закраски. В идеале задача одного конвейера — за один такт закрасить одну точку. Но поскольку сделать это за такой короткий промежуток времени невозможно (Хотите грубо оценить «реальную частоту», с которой выполняются команды в процессоре, — поделите тактовую частоту на число стадий в его конвейере. То есть 2400/12 ~ 200 МГц — лучший результат AMD, 3600/20~180 МГц — у Intel. 150–200 МГц — на таких частотах работали бы сегодняшние процессоры, если б не конвейеризация), блок закраски выполняют в виде «конвейера» — разбивают большую задачу на несколько маленьких, выполняющихся поочередно. Реально один пиксел обрабатывается довольно долго — порой даже десятки и сотни тактов GPU, зато одновременно конвейер обрабатывает пропорционально большее количество пикселов — над первым выполняется первая операция конвейера, над вторым — вторая и т. д. По мере выполнения операций пикселы переходят на следующие стадии конвейера; каждый такт один пиксел оказывается полностью обработанным и «сходит» с конвейера, а взамен на первую стадию поступает новый пиксел. В отличие от обычного процессора, у графических это особых проблем не вызывает — все операции над пикселами независимы друг от друга. А чтобы еще повысить производительность, ставят несколько конвейеров. N конвейеров закрасят за такт N пикселов — таким образом, предельно достижимая скорость закраски экрана составляет NхF пикселов в секунду (где F — частота, на которой работает ядро GPU). Частота современных чипов — от 200 до 500 МГц, число конвейеров — от 1 до 16, так что даже простой GPU обрабатывает сотни миллионов точек в секунду, ну а мощные ускорители способы перерабатывать миллиарды пикселов. Это в десятки раз превосходит возможности даже самых производительных универсальных CPU. Значительная часть вычислений пиксельного конвейера всегда связана с использованием одной или нескольких текстур (и, соответственно, с выполнением далеко не быстрой выборки из них). Поэтому выделяют специальные текстурные блоки (Texture Module Unit, TMU), единственная задача которых — осуществлять выборку из текстур. На каждом конвейере одинаковое число TMU — от одного до четырех, и каждый такт эти модули (естественно, тоже с использованием конвейера) в пределе способны произвести одну выборку. И если на конвейере, например, всего один TMU, а для проведения вычислений над точкой нужно две текстуры (что, как правило, в реальных играх и происходит), то текстурные модули будут выдавать вдвое меньше данных, чем способен обработать конвейер, — в итоге пикселы будут сходить с конвейера не каждый такт, а в лучшем случае каждый второй такт — скорость закраски упадет вдвое. Поэтому число TMU на конвейер является вторым по важности (после числа конвейеров) параметром графического ядра. Параметр (число конвейеров) x (TMU на конвейер) называется формулой графического процессора. Помимо конвейеров закраски и текстурных блоков в GPU обязательно имеется графическая память. Как правило (за исключением большинства интегрированных решений), это несколько микросхем DRAM, распаянных на плате ускорителя, и специальный высокопроизводительный контроллер памяти, интегрированный непосредственно в GPU. Причем для того, чтобы обеспечить графический процессор необходимым объемом данных (вспоминаем про сотни миллионов точек в секунду и про то, что для расчета каждой нужно хотя бы 2–4, а лучше 8–16 байт информации из текстуры), требуется очень быстрая память. К счастью, в данном случае можно, грубо говоря, поставить очень много микросхем памяти, работающих независимо, благодаря чему за один такт будет считываться 64, 128 или даже 256 бит информации (8, 16 и 32 байта соответственно). Число это называется шириной интерфейса памяти (от него, а не от частоты в первую очередь зависит производительность подсистемы памяти, так что внимательно следите за пометками «64-bit» мелким шрифтом в прайс-листах на видеокарты). Да и частота работы оперативной памяти на графических платах явно выше — тут 600–1000 МГц не являются чем-то уникальным (на десктопах частоты сейчас составляют 400–533 МГц). Причем отчасти благодаря тому, что требования к надежности памяти здесь гораздо ниже: даже если и будет ошибка где-то там в 12321-м пикселе текстуры, разве ее кто-то заметит? Впрочем, любой современный акселератор может напрямую работать со специально отведенной ему системной оперативной памятью, поэтому без локальной графической памяти в принципе можно и обойтись. К слову, игр, в которых текстуры одной сцены превышали бы 64–128 Мбайт, — единицы, так что большой объем видеопамяти большинству ускорителей не нужен. С другой стороны, довольно часто нужное количество микросхем памяти (а значит, и ширину интерфейса) просто не набрать, не набрав в итоге большого объема локальной памяти. Но ориентироваться только на объем видеопамяти при покупке все же не стоит. Помимо текстур в памяти хранится разнообразная геометрическая информация и некоторые буферы, используемые акселератором в работе. Важнейший из них — фрейм-буфер (frame buffer), куда складываются обработанные пикселы и где хранятся полностью готовые картинки. Специальный буфер нужен потому, что вывод и формирование картинки не зависят друг от друга — монитор ждать окончания расчета очередного пиксела не будет, ему нужно непрерывно получать видеосигнал. Для этого используется специальный цифроаналовый преобразователь RAMDAC (RAM Digital-to-Analog Convertor — ЦАП памяти), который непрерывно читает фрейм-буфер и формирует сигнал, передаваемый через дополнительные схемы на выход видеокарты. Аналогично могут формироваться цифровые или телевизионные выходные сигналы. У современных GPU — несколько RAMDAC, позволяющих одновременно и независимо выводить видеосигналы на несколько устройств. Наконец, последняя ключевая составляющая GPU — процессор геометрических вычислений. Центральному процессору просчитать необходимые сотни точек и векторов для работы ускорителя обычно не составляет проблемы — большинство интегрированных графических решений (и даже Intel Graphics Media Accelerator 900 в чипсете i915G) этого блока вообще не имеют. Но наличие GPU позволяет существенно облегчить жизнь CPU и разгрузить графическую шину. Шейдеры Шейдер — короткая программа, позволяющая программировать графический ускоритель. На практике шейдер — некая хитрая последовательность машинных кодов, которую разработчик, как правило, описывает на специальной разновидности ассемблера (Nvidia, правда, уже давно предлагает C-компилятор шейдеров — Cg, а в недавно вышедший DirectX 9.0c Microsoft включила стандартный High-Level Shader Language (HLSL)). Упомянутый bump mapping требует программирования формулы закраски каждого пиксела поверхности. Это — пример пиксельного шейдера (рис. 14). Персонажи Doom 3 построены, мягко говоря, из умеренного числа полигонов, но в качестве High Detail при поддержке ускорителем шейдеров этого совершенно не ощущаешь.
В объекте [11] порядка 30 тысяч вершин и полигонов — безумная расточительность по меркам 3D-графики, зато красиво. Простой прием — считать, что у любого треугольника есть видимая и невидимая грани — позволяет отбросить около половины треугольников [12]. Никогда не пробовали проходить сквозь стены в компьютерных играх? Только что пройденная стенка снаружи невидима. Но даже 30 тысяч полигонов без текстур впечатления не производят [13]. И графическая память предназначена в первую очередь для их хранения. Пиксельные шейдеры помогают имитировать криволинейные поверхности и отражение света от них даже на «угловатой», казалось бы, модели [14]. Парочка текстур — diffuse и bump, да чуток шейдеров — и перед нами весьма правдоподобный аппарат [15]. Шейдеры тут — рельеф корпуса и колец объектива и блики от металла. Без них — явно хуже [16]. Начнем мы все же с более «понятного» — с вершинных шейдеров (vertex shader), представляющих собой естественное развитие идей «геометрического сопроцессора» T&L. Если последний аппаратно ускоряет некоторые геометрические преобразования, то почему бы не расширить его возможности и не поручить ему более широкий класс задач — скажем, заставить самостоятельно, без подсказок CPU, шевелить траву и листья деревьев в сцене? Или детализировать на лету близкие объекты и огрублять дальние? Программа для блока геометрических преобразований и называется вершинным шейдером. Они незаменимы, например, для имитации развевающейся на ветру одежды или волос персонажа, мимики, переливов меха и прочих «тонкостей» геометрии. Попутно программист получает полный контроль над механизмами T&L и может использовать вершинные шейдеры для расчета специфической геометрической информации, которую потом будут использовать пиксельные шейдеры (рис. 15). Как это происходит на практике? Разработчик пишет относительно небольшую программу и указывает, что ее следует использовать для таких-то и таких-то вершин треугольников. Для каждого кадра ускоритель эту программу исполняет — и в результате, например, листочек на дереве поворачивается на определенный угол и уже в таком виде отображается на экране. Это один из способов использования вершинного шейдера. Другой вариант: программа изменяет текстурные координаты вершины — и в итоге, скажем, уголки губ героини слегка поднимаются — персонаж улыбается. Настройке поддаются практически все параметры, связанные с обработкой вершин, — помимо уже названных геометрических и текстурных координат можно задавать цвет вершины, ее размеры, «фактор тумана». Все это хорошо, скажет читатель, но чем версии шейдеров отличаются друг от друга? Вообще говоря, вершинный шейдер даже первой версии может быть довольно сложной многострочной программой — благо объем геометрических вычислений при рендеринге относительно невелик и не слишком сказывается на общей производительности. Шейдеры первой версии (1.0 и 1.1) — это «сугубо прямолинейные» программы, в которых не допускаются никакие переходы (тем более — условные, тем более — циклы), а 29 соответствующих ассемблерных инструкций либо «вспомогательные» (описывающие версию шейдера, используемые им константы и пр.), либо «арифметические» — типа вычисления скалярного или векторного произведения четырехмерных векторов, логарифма, синуса и экспоненты. Шейдеры второй версии допускают (со значительными ограничениями) условные переходы и циклы, а также позволяют организовывать функции (можно реализовать практически любой алгоритм). Шейдеры третьей версии не накладывают почти никаких ограничений, позволяют использовать в вычислениях текстуры и создавать «свои» свойства для вершин — по сути дела, превращают вершинный блок GPU в полноценный процессор. Шейдер может быть написан на специальном ассемблере или скомпилирован с высокоуровневого языка специальным компилятором. Впрочем, подробнее о вершинных шейдерах и последних веяниях мы расскажем как-нибудь в другой раз. А теперь переключимся на главных героев современных видеокарт — пиксельные шейдеры. Поскольку, во-первых, именно результаты их применения сразу же бросаются в глаза, а во-вторых, заменить их нечем. Вершинные шейдеры всего лишь разгружают центральный процессор, и их вполне могут имитировать драйверы, заменяя геометрический блок стандартным CPU, а вот пиксельный шейдер, определяющий функционирование «фундаментальных блоков» ускорителя, конечно, сымитировать нельзя. Поэтому, говоря о шейдерах и их версиях, как правило, имеют в виду именно пиксельные шейдеры. Пиксельные шейдеры — это рельефные стены и естественное освещение (в том числе — динамическое и от многих источников света), рябь на воде и блики света на металлических и стеклянных поверхностях, очень реалистично выглядящие криволинейные поверхности и разнообразные спецэффекты… Всего не перечислить! Пожалуй, за самым наглядным и очевидным применением шейдеров (водная гладь) можно отослать к красивейшей игре Far Cry, а за наиболее комплексным (сложнейшая система освещения) — к Doom 3. Конечно, многое из перечисленного можно реализовать другими техниками, но… получается это, как правило, не столь красиво, а главное, дается гораздо труднее. С вычислительной точки зрения пиксельный шейдер обычно задает модель расчета освещения отдельно взятой точки изображения — скажем, «продвинутый вариант» модели Фонга. Например, в модели Гуро, используемой видеокартами «поколения DirectX 7», практически невозможно задать «металлический» компонент освещения в формуле Фонга — возникающие при этом «блики» на поверхности объекта по размерам существенно меньше полигона. Но, опять же, только освещением дело не ограничивается: с помощью пиксельных шейдеров можно также автоматически генерировать текстуры (стилизацию под дерево, или под воду, или блики на дне ручья, отбрасываемые рябью на его поверхности). Причем — текстуры, изменяющиеся во времени и не теряющие детализации даже при приближении к ним (На хранение больших текстур нужно много памяти, работа с ними — большая нагрузка на ускоритель, так что порой проще вычислить что-то, чем хранить). Или создавать оптические эффекты — дрожащий воздух, неровное стекло… вариантов много. Правда, пиксельный шейдер не столько вычисляет, сколько изменяет некий предварительно вычисленный стандартными способами цвет, поэтому даже при отсутствии поддержки пиксельных шейдеров акселератор все-таки сможет что-то изобразить. Поскольку нагрузка на блоки закраски гораздо выше, а самих блоков, как правило, больше, то ограничения на программу здесь гораздо жестче, чем в случае вершинных шейдеров. Помимо арифметических инструкций присутствуют и специализированные «текстурные», осуществляющие выборки цвета и арифметические вычисления с данными текстур. Различия между версиями пиксельных шейдеров примерно того же порядка, как между вершинными шейдерами. Пиксельный шейдер версии 1.0 — не более восьми арифметических инструкций и не более четырех текстурных. Шейдер 1.4 — это те же восемь арифметических, но уже шесть текстурных инструкций. Никаких условных переходов, естественно, нет и в помине. Впрочем, для создания правдоподобных металлических или, скажем, неровных поверхностей этого вполне достаточно. Главная особенность шейдеров второй версии — поддержка чисел с плавающей точкой. В задачах освещения это очень важно: динамического диапазона стандартного 8-битного цвета для передачи всего богатства оттенков может и не хватить. Ну а в пиксельные шейдеры третьей версии включена поддержка условных переходов — для задания формул освещения функция почти бесполезная, но позволяющая в некоторых случаях оптимизировать производительность шейдера (например, не проводить вычислений над заведомо бесперспективными пикселами). Модель освещения Фонга Опишем основную модель вычисления освещения, составляющую «фундаментальную основу» любой современной 3D-графики. Итак, у нас есть некоторая поверхность, освещенная светом (см. рис.). По Фонгу, цвет участка поверхности считается раздельно по каждому из цветовых каналов (красному, синему и зеленому) и складывается из трех компонентов: фонового освещения, имитирующего естественный рассеянный свет помещения, а также одинакового для всех точек поверхности диффузного отражения (рассеянного света, отраженного от поверхности) и зеркального отражения (имитирующего направленное отражение). Разберемся с каждым из слагаемых.
Диффузное отражение (diffuse) соответствует отражению света от неровной поверхности. Подобная поверхность рассеивает падающий на нее свет практически равномерно по всем направлениям — с какой стороны на нее не гляди, выглядеть будет одинаково. Однако, в отличие от фонового освещения, диффузное отражение учитывает направление на источник света. Точнее, согласно закону Ламберта, яркость участка поверхности определяется только вертикальным компонентом падающего света, или, в математической форме, Id = kd(l,n)Ld. Здесь Ld — яркость источника света, kd — коэффициент отражения, l — вектор направления на источник света, n — вектор нормали (перпендикуляр к поверхности). Иногда учитывают квадратичное убывание яркости при удалении источника света от поверхности: это дает дополнительный коэффициент (a+bd+cd2)-1, где d — расстояние до источника света; a, b, c — эмпирически подбираемые (для большей естественности) коэффициенты. Без диффузного отражения изобразить хоть какое-то освещение невозможно. Но изюминка кроется в Просуммировав, получим стандартную модель Фонга: I = (a+bd+cd2)-1(kd Ld (l,n) + ks Ls (r,v)a) + kaLa. Ее хватает для любых практических применений. Для расчетов, конечно, формула слишком сложна, и ее так или иначе упрощают или сводят расчет для всей поверхности к расчету по небольшому набору точек и интерполяции цвета поверхности на их основе (модель Гуро). Практика Впрочем, довольно теории — ведь как известно, лучше один раз увидеть, чем сто раз К сожалению, подобрать другие наглядные примеры в Far Cry трудно, так что от этой красочной и яркой игры мы вынужденно перемещаемся к куда более технически «навороченному» темному и мрачному Doom 3. В журнале этого не передать, но поверьте на слово: лица персонажей ну просто как живые (рис. 20). А ведь треугольников в их моделях — очень и очень умеренное количество (рис. 21). Анимация лиц — вершинные шейдеры, естественно выглядящая кожа и одежда персонажей вкупе с динамическим освещением — пиксельные шейдеры. Достаточно выключить работу основных пиксельных шейдеров (бамп-мэппинг и зеркальное отражение в модели Фонга), как от очарования игры не остается и следа (рис. 22). Еще нагляднее это видно на примере интерьеров Doom 3: без пиксельных шейдеров (рис. 25) и с включенными шейдерами (рис. 26); см. также рис. 23, 24. И это — только «живые», «повседневные» примеры. А ведь еще есть разнообразные спецэффекты и постпроцессинг картинки: дрожание горячего воздуха, троящееся изображение в глазах персонажа (рис. 27) и пр. Возможности, предоставляемые шейдерами, практически безграничны. По сути дела, современная графическая плата — универсальный мини-компьютер для проведения графических вычислений и «запрограммировать» на нем можно все, что хочешь, — точно так же, как на обычном компьютере можно написать программу, реализующую любой, сколь угодно сложный алгоритм.
Несколько слов в заключение. У полигональной графики «есть еще порох в пороховницах», и перспективы перехода на принципиально новые технологии построения трехмерного изображения (рэйтрейсинг, о котором — следующая статья) после просмотра хита уровня Doom 3 становятся совершенно неочевидными — особенно учитывая несопоставимый разрыв в трудоемкости построения картинок в первом и втором случаях. Современный ускоритель без поддержки шейдеров, каким бы быстрым он ни был, неполноценен, и достичь пресловутого кинематографического качества без их использования невозможно. Совсем уж «полный реализм» ему, конечно, не по плечу: слишком многое строится не на физических моделях, а на некоторых приближениях, дающих не правильную, а «правдоподобную» картинку, — но уровень киношных спецэффектов вполне достижим. Видимо, в ближайшем будущем поддержку шейдеров версии 3.0 получат все без исключения видеокарты, однако принципиального развития («шейдеров 4.0») ждать от них, похоже, не стоит. Разумеется, что-нибудь «новое и продвинутое» производители изобретут, но все действительно принципиальное в GPU уровня GeForce 6xxx уже реализовано.
Основные термины GPU Начнем с уже известного вам GPU (или как его предпочитает называть одна из лидирующих компаний-производителей — VPU — Video Processing Unit). За этой аббревиатурой скрывается специализированный чип — основа (или ядро) современной видеокарты. Его возможности определяют, к какому поколению будет отнесена плата. Главная задача GPU — выполнение инструкций, формирующих изображение. Это может быть как простейшая команда — например, «нарисовать точку в заданных координатах», так и сложные геометрические преобразования какого-либо объекта текущей сцены. Хотя некоторые из функций может брать на себя центральный процессор компьютера (что ему и приходится делать, если видеокарта слабенькая), справляться с этим ему очень тяжело. Сила видеочипа — в его специализированности. Видеопамять Видеопамять — в том или ином объеме имеется на всех нынешних видеокартах (оптимальный объем на сегодняшний день — 128 Мбайт). Она эксклюзивно используется GPU для хранения как можно большего числа данных, необходимых ему для обработки сцены. Если ее не хватает, используется системная память, но это заметно тормозит работу компьютера. Сейчас на рынке безоговорочно доминирует DDR SDRAM. Варианты на более прогрессивной, но и гораздо более дорогой DDR II еще редки, а платы с установленной морально устаревшей SDR уже редки. Об экзотических типах и говорить нечего. Таким образом, стоит обращать внимание только на рабочую частоту памяти. Оптимум, впрочем, нужно искать в связке GPU+память — в каждом конкретном случае он разный. Интерфейс Интерфейс (шина, протокол). Этот параметр определяет (только в данном случае, так как термины используются очень широко), каким способом видеокарта общается с остальной системой. Два основных варианта — AGP 4x или AGP 8x (современные карты на шине PCI — большая редкость). Цифры означают коэффициент, на который нужно умножить пропускную способность первого варианта шины AGP. Соответственно, можете сделать вывод о том, что быстрее. Пиковая пропускная способность интерфейса 8х, равная 2,1 Гбайт/с, более соответствует пропускным способностям между другими узлами системы. Но сбалансированность подразумевает не количественную гармонию, а качественную. То есть ни один элемент не должен резко снижать общей производительности. А на данный момент режим 4х еще не стал узким местом. Даже переход в 2х почти не сказывается на результатах. Объясняется все достаточно просто. Наиболее требовательны к скорости элементами трафика между видеокартой и остальной системой текстуры. Однако локальной памяти на борту современного ускорителя с лихвой хватает на размещение не только текстур, но и кадровых, Z- и stencil-буферов. А потому, предварительно загрузив все необходимое себе «под бочок», видеокарта редко испытывает потребность в дозагрузке чего-нибудь очень уж объемного. Новые рубежи производительности откроются лишь при возникновении необходимости часто обращаться к системной памяти. Отсюда следует вывод, что выиграют от перехода к 8х по большей части интегрированные графические решения, делящие память с остальными узлами. Да и в этом случае неэффективность механизма SMA (share memory architecture — архитектура совместного использования памяти) не позволит полностью загрузить шину с новым протоколом. Отдельный вопрос — совместимость разных версий шины видеокарты и материнской платы. Если рассматривать пару AGP 4x/AGP 8x, то проблем теоретически возникать не должно, независимо от того, какое из устройств какую версию поддерживает (разумеется, пара будет работать в режиме 4х). Но, например, Radeon 9700 Pro не дружит с ранними наборами системной логики (когда новая шина еще была в диковинку и делались лишь первые попытки ее воплощения в кремнии) от VIA и SiS — при активации режима AGP 8х на видеокарте и материнской плате периодически возникают сбои. В принципе, в большинстве подобных случаев проблема решается обновлением драйверов или перепрошивкой BIOS. В крайнем случае, можно принудительно выставить режим AGP 4x. А вот владельцам древних материнских плат, поддерживающих только AGP 1х или AGP 2х, чтобы установить современную видеокарту с протоколом 4x или 8x, придется подумать о замене устаревшего оборудования. Впрочем, такая системная плата вряд ли поддерживает достаточно производительный процессор, чтобы стала заметна выгода от более мощного ускорителя. Похожая ситуация — при попытке установить старую видеокарту в современные материнские платы: многие из них поддерживают режим AGP 1х, но не работают с устаревшими трехвольтными картами. FPS FPS (Frames Per Second). Одно из основных понятий при тестировании. Означает всего лишь число кадров, выводимых видеокартой в секунду. Z-буфер Z-буфер. Поскольку Z в системе координат обозначает глубину, то его также называют буфером глубины. Служит для определения объектов сцены (или их частей), которые будут отображены в текущем кадре (или не будут, если заслоняются некоей поверхностью). Fillrate Fillrate (скорость заполнения) — показывает, с какой скоростью чип может нарисовать картинку. В наших тестах скорость измеряется в текселах (пикселах, на которые наложена текстура) в секунду. Текстура Текстура — изображение, которое накладывается («приклеивается») на предметы трехмерной сцены. Это позволяет во многих случаях как упростить обработку сцены, так и повысить ее реалистичность. Простейший пример: зачем вырисовывать каждый кирпичик в стене, если можно создать сразу большую голую стену и «натянуть» на нее изображение кирпичной кладки. Поколение Поколение видеокарты определяется по тому, какую версию API DirectX (Application Program Interface — программный интерфейс приложения — условно говоря, язык программирования) аппаратно поддерживает GPU. Ныне на рынке представлены DX7-, DX8- и DX9-чипы. Но один из крупнейших производителей чипов предпочитает относить свою продукцию к поколению DX9+ из-за превышения ею базовых спецификаций Microsoft. Наиболее интересными технологиями в двух последних версиях стали вершинные и пиксельные шейдеры. Если в игре используется функция из набора DX9, а ваша видеокарта принадлежит к поколению DX7, то эффект либо будет создаваться с помощью выполнения нескольких старых функций (что, как правило, значительно медленнее), либо (что более вероятно) будет отключен. Простые и понятные рекомендации по выбору дать пока невозможно. Читайте дальше, и вы сами сможете определить, что лучше отвечает вашим потребностям. Полноэкранное сглаживание (антиалиасинг). Полноэкранное сглаживание (антиалиасинг). Возьмите матрицу, например 5х3 клеток. Попробуйте нарисовать в ней диагональ, закрашивая только ячейки целиком. Уверен, у вас получилась ломаная линия, лишь пародирующая прямую. Экран монитора тоже состоит из отдельных «клеток» — пикселов. Конечно, их значительно больше. Как правило, используются разрешения от 800х600 до 1600х1200. Но даже такого количества зачастую не хватает для построения идеальной линии, если она не строго вертикальна или горизонтальна (то есть не совпадает со столбцом или строкой пикселов). Чтобы избавиться от эффекта лестницы, применяются алгоритмы сглаживания. Они позволяют заметно улучшить качество картинки, но требуют от карты внушительной производительности. Чаще всего используется так называемое четырехкратное полноэкранное сглаживание. Суперсэмплинг (SSAA), мультисэмплинг (MSAA) и Quincunx — наиболее распространенные методы полноэкранного сглаживания. Самым требовательным к производительности, но и самым качественным является суперсэмплинг. При его применении происходит рендеринг кадра в более высоком разрешении (зависит от режима; например, при разрешении 800х600 и четырехкратном SSAA разрешение промежуточной картинки составит 1600х1200). При окончательном формировании цвета сглаженного пиксела учитываются цвета соседних пикселов, принадлежащих большому изображению. Мультисэмплинг для определения цвета сглаженного пиксела использует не один увеличенный кадр, а несколько идентичных, но как бы «сдвинутых» друг относительно друга, что позволяет оптимизировать расчеты. К сожалению, этот алгоритм не умеет обрабатывать полупрозрачные текстуры.
Quincunx — дальнейшее развитие метода. Сэмплы (рендерится всего два одинаковых изображения) сдвигаются так, что пикселы выстраиваются в шахматном порядке. В результате для определения цвета итогового изображения используются значения самого пиксела и четырех «сдвинутых» соседей. Это дает возможность получить качество, приближенное к четырехкратному антиалиасингу, при потерях производительности, примерно соответствующих двукратному MSAA.
Анизотропная фильтрация. Действие этого алгоритма трудно объяснить «на пальцах». Необходимость в нем возникает из-за простого, в сущности, геометрического процесса: при изменении угла наклона поверхности к «видимой плоскости» (формируемой матрице кадра) площадь проекции уменьшается. Соответственно, отображаются не все исходные пикселы, что приводит к ухудшению качества картинки. Анизотропная фильтрация призвана вернуть (и возвращает) изображению четкость. Эта функция тоже весьма прожорлива, и результаты, показанные видеокартой в режиме анизотропной фильтрации, являются одним из важных показателей производительности mainstream- и high-end-моделей. Экранное разрешение Экранное разрешение — количество пикселов по горизонтали и вертикали, отображаемое на экране. Разрешение можно менять программно. Поскольку его физический размер фиксирован, то увеличение числа отображаемых пикселов приводит к уменьшению видимого размера деталей изображения. Таким образом, чем меньше диагональ монитора, тем меньшее разрешение рекомендуется использовать. В свою очередь, чем больше пикселов, тем большие усилия необходимо приложить чипу, чтобы сформировать картинку. Поэтому для определения класса видеокарт используются максимальные разрешения. Вершинные шейдеры Вершинные шейдеры (vertex shaders, VS) — специальные программы, с помощью которых быстро и эффективно можно манипулировать геометрией трехмерной сцены (относительно неплохо эмулируются центральным процессором). Очень перспективная функция, к сожалению, пока редко используемая в играх. DX8-поколение видеокарт поддерживает вершинные шейдеры версии 1.1, DX9 — 2.0 и 2.0+. Основные отличия версий отражены в табл. 1. Как видите, в каждой следующей версии программистам предоставляется все больше свободы при работе с вершинными шейдерами. Здесь надо особо отметить появление во второй версии возможности управления потоком команд, а в ее улучшенном варианте — динамическое управление. Благодаря этому можно сказать, что блок обработки шейдеров, поддерживающих VS 2+, достоин называться процессором. Чем динамический переход отличается от заранее прописанного статического? Тем, что переход можно осуществить, исходя из неких данных, полученных в этом же шейдере ранее. Для реализации тех же действий в R300 придется разбить один большой шейдер как минимум на два и передавать данные из первого во второй. Это довольно неудобно для разработчиков программных продуктов. Причем можно представить ситуацию, когда сложность разбиения заставит отказаться от применения некоего эффекта. А это уже неприятно для нас, пользователей. Хотя возможности VS 2+, очевидно, шире, чем у VS 2, не стоит забывать, что они поддерживаются лишь одним производителем. Создавая софт, разработчики должны побеспокоиться о его совместимости с максимальным числом аппаратных средств, дабы охватить как можно больший круг пользователей. А поскольку код, использующий по максимуму способности VS 2+, не совместим с VS 2, то и вероятность появления заметного количества программ, заточенных под них, невелика. К тому же обратная ситуация вполне допустима — код VS 2 будет корректно обработан чипом, поддерживающим VS 2+. Пиксельные шейдеры Пиксельные шейдеры (pixel shaders, PS) на первый взгляд очень похожи на вершинные. Тем не менее эти программы создают эффекты, обрабатывая не геометрию, а изображение. Различия в спецификациях пиксельных шейдеров приведены в табл. 2. Собственно говоря, здесь ситуация та же, что и с вершинными шейдерами. Таким же будет и вывод о практической ценности этих усовершенствований.
Нормы для мониторов
Поиск по сайту: |







 Точнее, для каждой вершины указываются некоторые ее плоские текстурные координаты в двухмерном (Еще бывают одномерные, трехмерные и даже четырех-пятимерные текстуры — иногда с ними удобнее работать. Последние, правда, используются крайне редко) изображении-текстуре. Если нужно посчитать цвет конкретной точки полигона, мы смотрим на ее расположение относительно трех остальных точек треугольника и ищем аналогичную по расположению относительно «текстурных» вершин точку в текстуре. Ее цвет и будет цветом нашей точки.
Точнее, для каждой вершины указываются некоторые ее плоские текстурные координаты в двухмерном (Еще бывают одномерные, трехмерные и даже четырех-пятимерные текстуры — иногда с ними удобнее работать. Последние, правда, используются крайне редко) изображении-текстуре. Если нужно посчитать цвет конкретной точки полигона, мы смотрим на ее расположение относительно трех остальных точек треугольника и ищем аналогичную по расположению относительно «текстурных» вершин точку в текстуре. Ее цвет и будет цветом нашей точки.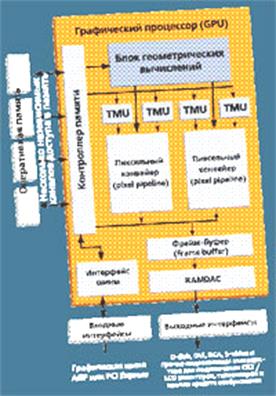 Впрочем, даже освещенные объекты оставались неестественно плоскими и гладкими — все-таки интерполяция. И тем более — интерполяция по довольно большим полигонам не в состоянии передать реалистичную фактуру поверхности, особенно с близкого расстояния. Да что фактура! Стоит внимательно рассмотреть любой мало-мальски сложный объект, как сразу станет заметна «прямолинейность» образующих полигоны линий. Тупик полигональной графики? Отнюдь! Конечно, объект, который мы изображаем, набран из трех десятков прямоугольничков, однако можно немножко «схитрить» с моделью освещения. Эта модель (см. врезку в конце статьи) практически всегда использует так называемый вектор нормали к поверхности, то есть вектор, перпендикулярный к поверхности в данной точке. Например, для сферы векторы нормалей — это векторы единичной длины, направленные диаметрально противоположно направлению на центр сферы. И освещение объекта зависит, как правило, не от его формы, а от направления вектора нормали. Казалось бы, крошечная выбоинка или выступ в полигоне (практически незаметные смещения по расстоянию, но очень заметные по нормалям и из-за неоднородности отражения света в разных направлениях), — а мы эти изъяны поверхности тут же замечаем. Читатель наверняка уже догадался, к чему я клоню. Задав еще одну текстуру специального вида (определяющую нормали) и модифицировав алгоритм расчета цвета точки, мы можем, не усложняя геометрическую модель, радикально улучшить ее внешний вид (рис. 10). Подобные техники называются bump mapping; впервые они появились у Matrox (Environment Bump Mapping), а затем и у Nvidia (DOT3). Роднит их то, что в общем случае для полноценной реализации они требуют программирования пиксельных конвейеров — перехода от интерполяции и выборки из текстур к заданию своей формулы для расчета цвета каждого пиксела объекта (а не только вершин). Таким образом, мы подходим к идее шейдеров.
Впрочем, даже освещенные объекты оставались неестественно плоскими и гладкими — все-таки интерполяция. И тем более — интерполяция по довольно большим полигонам не в состоянии передать реалистичную фактуру поверхности, особенно с близкого расстояния. Да что фактура! Стоит внимательно рассмотреть любой мало-мальски сложный объект, как сразу станет заметна «прямолинейность» образующих полигоны линий. Тупик полигональной графики? Отнюдь! Конечно, объект, который мы изображаем, набран из трех десятков прямоугольничков, однако можно немножко «схитрить» с моделью освещения. Эта модель (см. врезку в конце статьи) практически всегда использует так называемый вектор нормали к поверхности, то есть вектор, перпендикулярный к поверхности в данной точке. Например, для сферы векторы нормалей — это векторы единичной длины, направленные диаметрально противоположно направлению на центр сферы. И освещение объекта зависит, как правило, не от его формы, а от направления вектора нормали. Казалось бы, крошечная выбоинка или выступ в полигоне (практически незаметные смещения по расстоянию, но очень заметные по нормалям и из-за неоднородности отражения света в разных направлениях), — а мы эти изъяны поверхности тут же замечаем. Читатель наверняка уже догадался, к чему я клоню. Задав еще одну текстуру специального вида (определяющую нормали) и модифицировав алгоритм расчета цвета точки, мы можем, не усложняя геометрическую модель, радикально улучшить ее внешний вид (рис. 10). Подобные техники называются bump mapping; впервые они появились у Matrox (Environment Bump Mapping), а затем и у Nvidia (DOT3). Роднит их то, что в общем случае для полноценной реализации они требуют программирования пиксельных конвейеров — перехода от интерполяции и выборки из текстур к заданию своей формулы для расчета цвета каждого пиксела объекта (а не только вершин). Таким образом, мы подходим к идее шейдеров.





 Фоновое освещение (ambient) рассчитывается по формуле Ia = kaLa. Теоретически в сцене оно имитирует рассеянный свет, не имеющий конкретного источника. Поскольку центра и направления у него нет, то оно совершенно одинаково для всех точек поверхности. La в формуле — яркость этого света, ka — коэффициент светового отражения, показывающий, какая часть энергии отражается объектом (чем коэффициент меньше, тем объект темнее). На практике фоновое освещение используется для того, чтобы подсветить излишне темные участки.
Фоновое освещение (ambient) рассчитывается по формуле Ia = kaLa. Теоретически в сцене оно имитирует рассеянный свет, не имеющий конкретного источника. Поскольку центра и направления у него нет, то оно совершенно одинаково для всех точек поверхности. La в формуле — яркость этого света, ka — коэффициент светового отражения, показывающий, какая часть энергии отражается объектом (чем коэффициент меньше, тем объект темнее). На практике фоновое освещение используется для того, чтобы подсветить излишне темные участки.
 последнем компоненте — зеркальном (specular) отражении, учитывающем не только направление на источник света, но и местоположение наблюдателя. Зеркальное отражение, как и следует из названия, концентрируется вдоль одного конкретного направления. Например: пусть r — «вектор отражения», лежащий в той же плоскости, что n и l, и образующий с n тот же угол, что и l, но только лежащий «по другую сторону» от n. Проще говоря, r — вектор, соответствующий «школьному» закону «угол падения равен углу отражения». Тогда полагают, что доля отраженной в сторону наблюдателя энергии пропорциональна (r,v)a, где a — «зеркальный коэффициент» отражения; v — вектор, направленный из точки на наблюдателя. Итого: Is= ks(r,v)a)Ls.
последнем компоненте — зеркальном (specular) отражении, учитывающем не только направление на источник света, но и местоположение наблюдателя. Зеркальное отражение, как и следует из названия, концентрируется вдоль одного конкретного направления. Например: пусть r — «вектор отражения», лежащий в той же плоскости, что n и l, и образующий с n тот же угол, что и l, но только лежащий «по другую сторону» от n. Проще говоря, r — вектор, соответствующий «школьному» закону «угол падения равен углу отражения». Тогда полагают, что доля отраженной в сторону наблюдателя энергии пропорциональна (r,v)a, где a — «зеркальный коэффициент» отражения; v — вектор, направленный из точки на наблюдателя. Итого: Is= ks(r,v)a)Ls. услышать. Благо в этом году вышло немало прекрасных иллюстраций к тому, что может сотворить художник, воспользовавшись техническими средствами новых ускорителей. Вот как выглядит самое начало Far Cry при полном отсутствии шейдеров (рис. 17), с пиксельными шейдерами версии 1.4 (рис. 18) и версии 2.0 (рис. 19). В данном случае пиксельные шейдеры — в первую очередь реалистичное изображение воды, во вторую — отдельные эффекты освещения.
услышать. Благо в этом году вышло немало прекрасных иллюстраций к тому, что может сотворить художник, воспользовавшись техническими средствами новых ускорителей. Вот как выглядит самое начало Far Cry при полном отсутствии шейдеров (рис. 17), с пиксельными шейдерами версии 1.4 (рис. 18) и версии 2.0 (рис. 19). В данном случае пиксельные шейдеры — в первую очередь реалистичное изображение воды, во вторую — отдельные эффекты освещения.





