|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Класс SIMD: один поток команд, несколько потоков данных
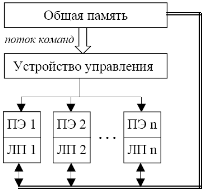
К классу SIMD относятся матричные БЦВМ. Упрощенная структура матричной ЦВМ показана на рис.5.
Рис.5. Матричная ЦВМ: ПЭ – процессорный элемент, ЛП – локальная память
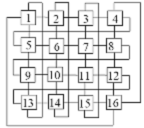
Особенностью структуры является то, что общее устройство управления определяет всем n процессорным элементам (ПЭ) одинаковые команды для каждого этапа вычисления программы. Все процессоры одновременно выполняют одну и ту же операцию — каждый из них над своими данными, которые хранятся в локальной памяти (ЛП) каждого из процессоров. К УУ предъявляются высокие требования по быстродействию, так как необходимо обеспечить непрерывность потока команд, выбираемых из основной оперативной памяти. Команды переходов выполняются непосредственно УУ с учетом состояния ПЭ на момент завершения предыдущей команды. По своей структуре ПЭ однородны и представляют собой арифметико-логические устройства, обладающие достаточно высоким быстродействием. Блоки управления отдельными ПЭ содержат средства для дешифрации команд, управления их реализацией, формирования признаков результатов операций и обращения к локальной памяти ПЭ. При выполнении потока команд отдельные ПЭ могут пропустить и не выполнить некоторые из них, если на входе ПЭ нет соответствующих данных. Как правило, матричные вычислительные системы представляют собой квадратную решетку, в узлах которой размещаются ПЭ. Каждый ПЭ в данной решетке связан с четырьмя соседними (рис.6).
Рис.6. Решетчатая структура ЦВМ
Номинальное быстродействие матричной БЦВМ при полной загрузке всех ПЭ пропорционально их количеству n: Vн = n·V1 где V1 — быстродействие отдельного ПЭ. Реальное быстродействие всегда меньше номинального из-за простоев ПЭ, которые вызваны: - несоответствием числа распараллеливаемых операций на различных этапах вычислений числу процессорных элементов; - ожиданием всеми ПЭ выполнения подготовительных операций в УУ, таких, как завершение одной задачи и инициирование новой, управление вычислительным процессом и т.д. К классу SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма – конвейерной организации машины. При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы. К классу SIMD также относятся ассоциативные ЦВМ. В них доступ к данным осуществляется не по адресу, а по ассоциативному признаку.
Поиск по сайту: |
 или
или