|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
В Discriminant Analysis
Рассмотрим процедуру решения практической задачи методом дискриминантного анализа в системе STATISTICA. Разберем принцип проведения дискриминантного анализа (точнее, формирование обучающих выборок) на основе данных представленных в файле example.sta. В файле содержатся данные по 20 сельскохозяйственным предприятиям, которые были выбраны и отнесены к соответствующим группам экспертным способом. Показатели-аргументы, участвующие в классификации, следующие: X1 – прибыль (тыс. р.); X2 – валовая продукция на 1 работника, занятого в сельском хозяйстве (тыс. р.); X3 – валовая продукция на 1 га сельхозугодий (тыс. р.); X4 – производство молока на 1 га сельхозугодий (кг); X5 – производство мяса на 1 га сельхозугодий (кг); X6 – выручка от реализации продукции на 1 работника (тыс. р.); X7 – выручка на 1 га сельхозугодий(тыс. р.).
Рис. 5.1. Файл example.sta · Из переключателя модулей STATISTICA откройте модуль Discriminant Analysis(Дискриминантный Анализ).Высветите название и нажмите кнопку Switch to (Переключиться в). · На экране появится стартовая панель модуля Stepwise Discriminant Function Analysis (Пошаговый анализ дискриминантных функций) (рис. 5.2), в котором кнопка Variables позволяет выбрать Grouping(Группируемую переменную)и Independent(Независимые переменные). Codes for grouping variable (Коды для групп переменной) указывают количество анализируемых групп объектов. Missing data (пропущенные переменные)позволяет выбрать построчное удаление переменных из списка, либо заменить их на средние значения. Open Data – открывает файл с данными. Можно указать условия выбора наблюдений из базы данных – кнопку Select Cases и веса переменных, выбрав их из списка – кнопку W. Выберем кнопку Open Data и загрузим в систему файл example.sta.
Рис. 5.2
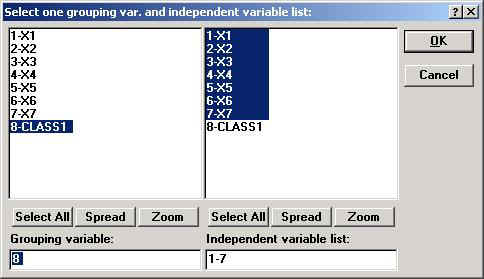
· При нажатии кнопки Variablesоткрывается диалоговое окно выбора переменных (рис. 5.3).
Рис. 5.3 В левой части выбирается группирующие переменные, в правой – переменные. Имена переменных в левой и правой части не должны пересекаться. В данном примере в качестве группирующей переменной выбрана переменная CLASS1, а в качестве группирующих переменных X1–X7. Select All (Выделить все) выделяет все переменные, Spread (Подробности) – для просмотра длинного имени, Zoom (Информация о переменной) позволяет просмотреть информацию о переменной: ее имя, формат числового значения, описательные статистики: номер в группе, среднее значение, статистическое отклонение. Нажав кнопку Variables выберем в качестве группирующей (Grouping) переменную CLASS1, а в качестве независимых переменных (Independent) – X1 – X7. После соответствующего выбора и нажатия OK окно Stepwise Discriminant Function Analysis должно быть представлено так, как показано на рис. 5.4.
Рис. 5.4
После нажатия кнопки OK откроется диалоговое окно Model Difinition (Определение модели) (рис. 5.5).
Рис. 5.5
В диалоговом окне Model Definitionпредложен выбор методавыборазначимых переменных. Method может быть задан Standfrt (Стандартный), Forward stepwise (Пошаговый с включением) и Backward stepwise (Пошаговый с исключением).Кнопка Review Correlations, stats, and graphs for groups (Корреляции, статистики и графики для групп)позволяет получить описательные статистики для выбранных переменных. Диалоговое окно Descriptive Statistics (Описательные статистики)позволяет получить: Pooled within-groups covariances & correlations(объединенные внутригрупповые ковариации и корреляции); Total covariances & correlations(полные ковариации и корреляции), Graph(графики корреляционных функций для всех переменных), Means & number of cases(средние значения для каждой переменной); Box & wh(диаграммы размаха как для всех переменных, так и для отдельно выбранных); Standart deviations(стандартные отклонения переменных в каждой группе); Categjrized histogram (by group)(категоризованные гистограммы по группам для каждой переменной); Box & whisker plot (by group)(диаграммы размаха по группам –категоризованную диаграмму рассеяния (по группам)); Categorized scatterplot (by group)(для двух любых переменных); Categorized normal probability plot (by group)(категоризованный нормальный график для любой переменной по группам). Выберем в качестве метода (Method) – Standardи нажмем OK. В ходе вычислений системой получены результаты, которые представлены в окне Discriminant Function Analisis Results(Результаты анализа дискриминантных функций) (рис. 5.6). После выбора метода модели и задания или просмотра необходимых параметров, нажав OK в диалоговом окне Model Difinition (Определение модели)получим результаты дискриминантных функций.
Рис. 5.6
Поиск по сайту: |