|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Схемы восстановления вычислительного процессаСтр 1 из 5Следующая ⇒
Схемы отказоустойчивых вычислительных машин.
Эта глава имеет две основные цели, первой целью является изучение вычислительных систем, использующих для восстановления схемы с дополнительными свободными модулями. Вторая цель - предложить новый способ восстановления вычислительного процесса в дублированной BM, использующий два дополнительных вычислительных модуля. Назовем такие схемы плюс — двухмодульными отказоустойчивыми вычислительными системами.
Схемы восстановления вычислительного процесса
Известно, что отказ может рассматриваться как перманентный сбой, поэтому здесь мы рассматриваем схему восстановления вычислительного процесса при возникновении сбоя, кроме того, изучение показало, что сбои в вычислительной системе происходят в 10–30 раз чаще, чем отказы [52, 57]. Для сокращения времени восстановления после сбоя в системе применяются различные схемы восстановления вычислительного процесса. Вместе с давно используемыми схемами, такими, как схемы с повторным счетом (Playback Scheme) и трехкратным резервированием задач (TMR-схема) в настоящее время используется ряд схем, основанных на двукратном резервировании задач. Применение таких схем связано с повышающейся важностью таких параметров системы как стоимость, размер, вес, потребляемая мощность. Растущий интерес к схемам с дублированием вычислительного процесса привел к появлению целого ряда работ, в которых исследуются их производительности и надежности [50, 51, 56, 57,64]. В данном разделе приводятся описания наиболее распространенных схем восстановления, предлагается новая схема восстановления вычислительного процесса на основе дублирования вычислительных модулей и определяется место схем с дублированием среди них.
Будем считать, что вычислительная система представляет собой множество вычислительных модулей (ВМ), в каждом из которых кроме центрального процессора имеются оперативная память и один или несколько соединительных интерфейсов, предназначенных для объединения ВМ в сеть. Система предназначена для выполнения некоторого набора задач. Задачи размещаются в системе определенным образом, при этом допускается возможность размещения нескольких задач на одном ВМ. Для достижения высокой надежности функционирования системы в состав ее операционной системы вводятся средства, позволяющие автоматически восстанавливать вычислительный процесс после значительной части возможных сбоев и ошибок в ее работе. В качестве основного метода обнаружения сбоев при выполнении вычислительного процесса используется многократное резервирование задач с последующим сравнением состояний ВМ, выполняющих копии одной и той же задачи. Сравнение производится в контрольных точках – некоторых точках процесса, в которых сохраняются промежуточные результаты вычислений, и к которым можно вернуться (передать им управление) в случае ошибки [7, 13]. Если состояния копий задачи в контрольной точке совпадают, новая контрольная точка считается корректной. В противном случае инициализируется восстановление вычислительного процесса. Для уменьшения количества сравниваемой информации может применяться сигнатура контрольной точки, см. главу 1. При дальнейших рассуждениях предполагается, что ошибочные модули всегда будут вырабатывать различные контрольные точки. Необходимо заметить, что это допущение не влияет на оценку производительности системы и должно рассматриваться только при исследовании ее надежности.
Сразу хотелось бы отметить, что существующие методы оценки производительности отказоустойчивых схем предполагают, что дополнительные модули, используемые схемами с дублированием вычислительного процесса для восстановления при возникновении сбоя, должны быть все время доступны. Но в реальной системе дополнительные модули могут использоваться совместно с некоторыми парами ВМ, т.е. могут быть недоступны. И поэтому, эти методы анализа не учитывают последствия возможных конфликтов, которые могут провоцировать одновременное требование ресурсов, когда они ограничены. В связи с вышесказанным результаты методов анализа, представленные в этом разделе можно считать неполными, и мы называем их «результатами в безконфликтных ситуациях».
В описании отказоустойчивых схем используются следующие символы:
рис. 2.1. Используемые обозначения
Пусть
Поиск по сайту: |

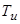 - время решения задачи, и пусть задача выполняется с n контрольными точками. Тогда:
- время решения задачи, и пусть задача выполняется с n контрольными точками. Тогда: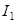 ,
, 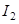 ,…,
,…,  ,
,  ,…,
,…, 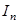 - интервалы между контрольными точками;
- интервалы между контрольными точками;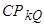 (check point) - контрольная точка, сформированная модулем Q в конце интервала
(check point) - контрольная точка, сформированная модулем Q в конце интервала 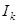 ;
;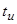 - время полезных вычислений между двумя последовательными контрольными точками;
- время полезных вычислений между двумя последовательными контрольными точками;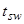 - время, требуемое для инициализации повторного счета в схеме с повторным счетом;
- время, требуемое для инициализации повторного счета в схеме с повторным счетом;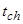 - время, требуемое для сравнения и сохранения контрольных точек;
- время, требуемое для сравнения и сохранения контрольных точек; ;
;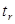 - время возврата двух и более ВM в последнее корректное состояние;
- время возврата двух и более ВM в последнее корректное состояние;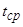 - время, требуемое для возврата в последнее корректное состояние одного из процессорных модулей;
- время, требуемое для возврата в последнее корректное состояние одного из процессорных модулей;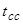 - время сравнения состояния свободного модуля с состоянием основных ВM;
- время сравнения состояния свободного модуля с состоянием основных ВM; - время, затраченное на инициализацию повтора;
- время, затраченное на инициализацию повтора; - время простоя.
- время простоя.