|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Регистры отладки и тестирования. 7 страница⇐ ПредыдущаяСтр 14 из 14
После перехода от микроархитектуры Net Burst к архитектуре Intel Core семейство чипсетов от Intel претерпело существенные изменения. Место на новых материнских платах заняла серия под кодовым именем Broadwater, которая в 2006 г. состояла из четырёх моделей: Intel Q965, Q963, G965 и Р965. Эти чипсеты полностью поддерживали процессоры Core 2 Duo и работали на частоте системной шины FSB 1066 МГц. Высокопроизводительный чипсет предыдущего поколения 975Х (кодовое имя Glenwood) также использовался для двухъядерных процессоров и сменился в конце 2007 г. с выходом чипсета Х38. Еще более ранний чипсет 945GC используется в компьютерах с процессором Intel Atom. Появившееся позже семейство чипсетов Bearlake (Intel X38, P35, G35, G33, Q35, Q33) пришло на смену предыдущего поколения микросхем и предназначалось для высокопроизводительных систем с процессорами, произведёнными по 45-нм техпроцессу. В них реализована поддержка «старых» 65-нм процессов, а также четырехъядерных микропроцессоров Core 2 Quard. Процессоры Pentium 4, Pentium D, Celeron D не поддерживаются этими чипсетами. В дополнение к поддержке памяти DDR2-800 это семейство логики позволяет работать с более технологичным типом памяти DDR3-1066, 1333, который отличается пониженным энергопотреблением и лучшим быстродействием. Семейство чипсетов (Intel Х58, Р55, Н55, Н57) предназначено для системной организации компьютеров на базе процессоров с микроархитектурой Nehalem. Чипсет Intel Х58 имеет вполне привычную архитектуру (см. рис. 5.3) и состоит из двух мостов, соединённых шиной DMI с пропускной способностью 2 Гбайт/сек (Gb/s). На место северного моста MCH (Memory Controller Hub) пришел новый чип с непривычным, но более логичным названием IOH (Input/Output Hub), ведь южные мосты уже давно называют ICH (Input/Output Controller Hub). В случае с Х58 место южного моста заслуженно занимает ICH10R. Связь с процессором поддерживается за счёт интерфейса QPI с пропускной способностью 25,6 Gb/s. Северный мост IOH целиком отдан под контроллер шины PCI Express 2.0 (36 линий). Трехканальный контроллер памяти удалён из чипсета в процессор и DDR3 (DDR2 не поддерживается), соединяется напрямую с процессорной шиной со скоростью 8,5 Gb/s. Этим во многом объясняется переход от сокета LGA775 к новому LGA1366 (процессоры Intel Core i7 на ядре Bloomfield). С выходом пятой серии чипсетов произошла «небольшая революция». Появилась возможность создания массивов видеокарт, как того, так и другого производителя, на одной материнской плате (технологии SLI, Cross Fire). Для этого необходима либо дополнительно установленная микросхема nForce 200, либо специальная функция в BIOS материнской платы.
Рис. 5.3. Схема чипсета Intel Х58 Южный мост ICH10R поддерживает подключение до 6 устройств PCI Express x1, до 12 портов USB 2.0, а также отвечает за взаимодействие с контроллерами накопителей и встроенными аудио- и сетевыми адаптерами. Чипсет Intel Р55 Express связывают с наиболее радикальными изменениями фирменной компьютерной платформы, сделанными с начала 90-х годов – момента вывода на рынок шины PCI. Новый чипсет, поддерживающий разъем LGA1156, состоит всего из одной микросхемы (см. рис.5.4) – южного моста, который связан с процессором посредством шины DMI с пиковой пропускной способностью 2Gb/s. Сокет LGA1156 используется для процессоров Intel Core i7/i5 на ядрах Lynnfield и Clarkdale. Интегрированный в процессор контроллер памяти стал двухканальным, а контроллер PCI Express 2.0 перенесен в процессор, что позволило удешевить чипсет, поскольку дорогостоящий интерфейс QPI для связи процессора и северного моста чипсета более не требуется, как, собственно, и сам северный мост. Южный мост чипсета поддерживает до 8 слотов PCI Express 2.0 x1 и позволяет использовать одновременно две графические платы, обеспечивает работу 6 портов SATA с поддержкой RAID-массивов (уровней 0, 1, 5, 10) и фирменной технологии Intel Matrix Storage, имеет встроенный аудио-кодак High Definition Audio, до 14 портов USB 2.0 и сетевой контроллер. Чипсеты Intel H55 и H57 Express названы «интегрированными» потому, что графический процессор встроен в центральный процессор, аналогично тому, как контроллер памяти (в Bloomfield) и контроллер PCI Express для графики (в Lynnfield) были интегрированы ранее. Эти чипсеты с урезанной функциональностью очень близки между собой и Н57 из этой пары безусловно старший, а Н55 – младший чипсет в семействе. Однако если сравнить их возможности с Р55, выяснится, что максимально похож на него именно Н57, имея всего 2 отличия, как раз и обусловленных реализацией видеосистемы. Отличия Н57 от Р55 оказались минимальны (см. рис. 5.5). Сохранилась архитектура (одна микросхема без разделения на северный и южный мосты – это как раз южный мост) осталась без изменений вся традиционная «периферийная» функциональность. Первое отличие состоит в реализации у Н57 специализированного интерфейса FDI, по которому процессор пересылает сформированную картинку экрана (будь то десктоп Windows с окнами приложений, полноэкранная демонстрация фильма или 3D-игры), а задача чипсета – предварительно сконфигурировав устройства отображения, обеспечить своевременный вывод этой картинки на (нужный) экран (Intel HD Graphics поддерживает до двух мониторов).
Рис.5.4. Схема чипсета Intel Р55 Express Здесь Intel применяет тот же подход, который сегметировал (разделял) чипсеты прежней архитектуры: топовый чипсет (Intel X58) реализует 2 полноскоростных интерфейса для внешней графики, решение среднего уровня (Intel P55) реализует один, но разбиваемый на два с половинной скоростью, а младшие и интегрированные продукты линейки (Н57, Н55) – один полноскоростной, без возможности задействовать пару видеокарт. Вполне очевидно, что чипсет данной архитектуры никак не может повлиять на поддержку или отсутствие поддержки двух графических интерфейсов. Просто при стартовом конфигурировании системы материнская плата на Н57 или Н55 «не обнаруживает» вариантов организовать работу пары портов PCI Express 2.0, а плате на Р55 в аналогичной ситуации это удаётся сделать. Технологии SLI и Cross Fire, позволяющие объединять вычислительные ресурсы двух видеокарт, доступны в системах на базе Р55, но не в системах на базе Н55/Н57.
Рис.5.5. Схема чипсета Intel H57 Express 5.3.2. Системная организация на базе чипсета AMD В качестве примера рассмотрим структуру чипсета AMD 890GX (см. рис. 5.6). Чипсет представляет собой классический набор из двух микросхем. Северный мост 890GX соединяется с процессорным сокетом AM3 через шину Hyper Transport 3.0 (с пропускной способностью 20,6 Gb/s) и с южным мостом SB850 через шину PCI Express x4, которая теперь называется «A-Link Express III» и имеет пропускную способность 2 Gb/s. Северный мост поддерживает шину PCI Express 2.0 x16, которая может быть разбита на две шины (PCI-E x8+x8) для Cross Fire и поддерживает 6 линий PCI-E 2.0 x1 для дополнительных слотов на материнской плате. Интегрированная графика, встроенная в северный мост 890 GX, использует ядро RV620, которое работает на тактовой частоте 700 МГц.
Рис. 5.6. Схема чипсета AMD 890 GX
6. Многопроцессорные и многомашинные вычислительные системы 6.1. Архитектуры вычислительных систем Точно также, как однопроцессорные компьютеры представлены по классификации М. Флина архитектурами с одним потоком данных SISD и множеством потоков данных SIMD, так и многопроцессорные системы могут быть представлены двумя базовыми типами архитектур в зависимости от параллелизма данных: · MISD (Multiple Instruction Single Data) – множество потоков команд – один поток данных; · MIMD (Multiple Instruction Multiple Data) – множество потоков команд – множество потоков данных. Класс MISD долгое время пустовал, поскольку не существовало практических примеров реализации систем, в которых одни и те же данные обрабатываются большим числом параллельных процессов. В дальнейшем для MISD нашлась адекватная организация вычислительной системы – распределённая мультипроцессорная система с общими данными. Наиболее простая и самая распространённая система этого класса – обычная локальная сеть персональных компьютеров, работающая с единой базой данных, когда много процессоров обрабатывают один поток данных. Впрочем, тут есть одна тонкость. Как только в такой сети все пользователи переключаются на обработку собственных данных, недоступных для других абонентов сети, MISD-система превращается в систему с множеством потоков команд и множеством потоков данных, соответствующую MIMD-архитектуре. Так как только MIMD-архитектура включает все уровни параллелизма от конвейера операций до независимых заданий и программ, то любая вычислительная система этого класса в частных приложениях может выступать как SISD и SIMD-система. Например, если многопроцессорный комплекс выполняет одну единственную программу без каких-либо признаков векторного параллелизма данных, то в этом конкретном случае он функционирует как обычный SISD-компьютер, и весь его потенциал остается невостребованным. Таким образом, употребляя термин «MIMD», надо иметь в виду не только много процессоров, но и множество вычислительных процессов, одновременно выполняемых в системе. Другая классификация многопроцессорных вычислительных систем (МВС), основана на разделении МВС по двум критериям: способу построения памяти (общая или распределенная) и способу передачи информации. Основные типы машин представлены в табл. 6.1. Здесь приняты следующие обозначения: Р – элементарный процессор, М – элемент памяти, К – коммутатор, С – кэш-память. Параллельная вычислительная система с общей памятью и шинной организацией обмена (машина 1) позволяет каждому процессору системы «видеть», как решается задача в целом, а не только те части, над которыми он работает. Общая шина, связанная с памятью, вызывает серьёзные проблемы для обеспечения высокой пропускной способности каналов обмена. Одним из способов обойти эту ситуацию является использование кэш-памяти (машина 2). В этом случае возникает проблема когерентности (адекватности) содержимого кэш-памяти и основной памяти. Другим способом повышения производительности систем является отказ от общей памяти (машина 3). Идеальной машиной является вычислительная система, у которой каждый процессор имеет прямые каналы связи с другими процессорами, но в этом случае требуется чрезвычайно большой объём оборудования для организации межпроцессорных обменов. Определенный компромисс представляет сеть с фиксированной топологией, в которой каждый процессор соединен с некоторым подмножеством процессоров системы (машины 4, 5, 6). Если процессорам, не имеющим непосредственного канала обмена, необходимо взаимодействовать, они передают сообщения через промежуточные процессоры. Одно из преимуществ такого подхода – не ограничивается рост числа процессоров в системе. Недостаток – требуется оптимизация прикладных программ, чтобы обеспечить выполнение параллельных процессов, для которых необходимо активное воздействие на соседние процессоры. Наиболее интересным вариантом для перспективных параллельных вычислительных комплексов является сочетание достоинства архитектур с распределенной памятью и каналами межпроцессорного обмена. Один из возможных методов построения таких комбинированных архитектур – конфигурация с коммутацией, когда процессор имеет локальную память, а соединяются процессоры между собой с помощью коммутатора (машина 9). Коммутатор может оказаться весьма полезным для группы процессоров с распределяемой памятью (машина 8). Данная конфигурация похожа на машину с общей памятью (машина 7), но здесь исключены проблемы пропускной способности шины. Таблица 6.1 Основные типы машин
MIMD-системы по способу взаимодействия процессоров (рис. 6.1) делятся на системы с сильной и слабой связью. Системы с сильной связью (иногда их называют «истинными» мультипроцессорами) основаны на объединении процессоров на общем поле оперативной памяти. Системы со слабой связью представляются многопроцессорными и многомашинными системами с распределенной памятью. Разница организации MIMD-систем с сильной и слабой связью проявляется при обработке приложений, отличающихся интенсивностью обменов между процессами.
6.2. Сильносвязанные многопроцессорные системы В архитектурах многопроцессорных сильносвязанных систем можно отметить две важнейшие характеристики: симметричность (равноправность) всех процессоров системы и распределениевсеми процессорами общего поля оперативной памяти. В таких системах, как правило, число процессоров невелико (не больше 16) и управляет ими централизованная операционная система. Процессоры обмениваются информацией через общую оперативную память. При этом возникают задержки из-за межпроцессорных конфликтов. При создании больших мультипроцессорных ЭВМ (мэйнфреймов, суперЭВМ) предпринимаются огромные усилия по увеличению пропускной способности оперативной памяти (перекрестная коммутация, многоблочная и многовходовая оперативная память и т. д.). В результате аппаратные затраты возрастают чуть ли не в квадратичной зависимости, а производительность системы упорно «не желает» увеличиваться пропорционально числу процессоров. То, что могут себе позволить дорогостоящие и сложные мэйнфреймы и суперкомпьютеры, не годится для компактных многопроцессорных серверов.
Для простой и «дешевой» поддержки многопроцессорной организации была предложена архитектура SMP – мультипроцессирование с разделением памяти, предполагающая объединение процессоров на общей шине оперативной памяти. За аппаратную простоту реализации средств SMP приходится расплачиваться процессорным временем ожидания в очереди к шине оперативной памяти. В большинстве случаев пользователи готовы добавить в сервер один или более процессоров (но редко – более четырёх) в надежде увеличить производительность системы. Стоимость этой операции ничтожна по сравнению со стоимостью всего сервера, а результат чаще всего оправдывает ожидания пользователя. Пропускную способность памяти в таких системах можно значительно увеличить путём применения больших многоуровневых кэшей. При этом кэши могут содержать как разделяемые, так и частные данные. Частные данные – это данные, которые используются одним процессором, в то время как разделяемые данные используются многими процессорами, по существу обеспечивая обмен между ними. Если кэшируются разделяемые данные, то они реплицируются и могут содержаться в нескольких кэшах. Кроме сокращения задержки доступа и требуемой полосы пропускания, такая репликация данных способствует также общему сокращению количества обменов. Однако кэширование разделяемых данных вызывает новую проблему: когерентность кэш-памяти. Эта проблема возникает из-за того, что значение элемента данных в памяти, используемое двумя разными процессорами, доступно этим процессорам только через их индивидуальные кэши. На рис. 6.2 показан простой пример, иллюстрирующий эту проблему, где А¢ и В¢ – кэшированные копии элементов А и В в основной памяти. Когерентное (адекватное) состояние кэша и основной памяти, когда А¢ = А & В¢ = B, изображено на рис. 6.2, а. Во втором случае (рис. 6.2, б) предполагается использование кэш-памяти с обратной записью, когда ЦП записывает значение 550 в ячейку А¢. В результате А¢ содержит новое значение, а в основной памяти осталось старое значение 100. При попытке вывода А из памяти будет получено старое значение. В третьем случае (рис. 6.2, в) подсистема ввода-вывода вводит в ячейку памяти В новое значение 440, а в кэш-памяти осталось старое значение В.
Рис. 6.2. Кэш и память когерентны A¢ = A & B¢ = B (a), кэш и память
Основное преимущество SMP – относительная простота программирования. В ситуации, когда все процессоры имеют одинаково быстрый доступ к общей памяти, вопрос о том, какой из процессоров какие вычисления будет выполнять, не столь принципиален, и значительная часть вычислительных алгоритмов, разработанных для последовательных компьютеров, может быть ускорена с помощью распараллеливающих и векторизирующих трансляторов.
6.3. Слабосвязанные многопроцессорные системы Существует несколько способов построения крупномасштабных систем с распределённой памятью. 1. Многомашинные системы. В таких системах отдельные компьютеры объединяются либо с помощью сетевых средств, либо с помощью общей внешней памяти (обычно – дисковые накопители большой емкости). 2. Системы с массовым параллелизмом МРР (Massively Parallel Processor). Идея построения систем этого класса тривиальна: берутся серийные микропроцессоры, снабжаются каждый своей локальной памятью, соединяются посредством некоторой коммуникационной среды, например сетью. Системы с массовым параллелизмом могут содержать десятки, сотни и тысячи процессоров, объединённых коммутационными сетями самой различной формы – от простейшей двумерной решетки до гиперкуба. Достоинства такой архитектуры: во-первых, она использует стандартные микропроцессоры; во-вторых, если требуется высокая терафлопсная производительность, то можно добавить в систему необходимое количество процессоров; в-третьих, если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию. Однако есть и решающий «минус», сводящий многие «плюсы» на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов иногда просто невозможно. 3. Кластерные системы. Данное направление, строго говоря, не является самостоятельным, а скорее представляет собой комбинацию из архитектур SMP и МРР. Из нескольких стандартных микропроцессоров и общей для них памяти формируется вычислительный узел (обычно по архитектуре SMP). Для достижения требуемой вычислительной мощности узлы объединяются высокоскоростными каналами. Эффективность распараллеливания процессов во многих случаях сильно зависит от топологии соединения процессорных узлов. Идеальной является топология, в которой любой узел мог бы напрямую связаться с любым другим узлом. Однако в кластерных системах это технически трудно реализуемо. Обычно процессорные узлы в современных кластерных системах образуют или двумерную решетку или гиперкуб. Для синхронизации параллельно выполняющихся в узлах процессов необходим обмен сообщениями, которые должны доходить из любого узла системы в любой другой узел. При этом важной характеристикой является максимальное расстояние между узлами. Если сравнивать по этому параметру двумерную решетку и гиперкуб, то при увеличении числа узлов топология гиперкуба является более выгодной. Время передачи информации от узла к узлу зависит от стартовой задержки и скорости передачи. Прогресс в производительности процессоров гораздо больше, чем в пропускной способности каналов связи. За время передачи процессорные узлы успевают выполнить большое количество команд. Поэтому инфраструктура каналов связи является одной из главных компонент кластерной или МРР-системы. Благодаря маштабируемости, именно кластерные системы являются сегодня лидерами по достигнутой производительности. СПИСОК ЛИТЕРАТУРЫ 1. Пятибратов А. П., Гудыно Л. П., Кириченко А. А. Вычислительные системы, сети и телекоммуникации. Учебник / Под ред. А. П. Пятибратова. 2-ое изд. – М.: Финансы и статистика, 2004. 2. Архитектура компьютера. 4-е изд. / Э. Таненбаум. – СПб.: Питер, 2003. 3. Хамахер К., Вранешич З., Заки С. Организация ЭВМ. 5-е изд. Изд. «Питер», 2003. 4. Орлов С., Цилькер Б. Организация ЭВМ и стсем. Учебник для ВУЗов. Изд. «Питер», 2004. 5. Асмаков С.В., Пахомов С.О. Железо 2008. Компьютер Пресс рекомендует. – СПб.: Питер, 2008. 6. Чередов А. Д. Организация ЭВМ и систем. Учеб. пособие. – 2-е изд. – Изд. ТПУ, 2005. Интернет-ресурсы 7. Официальный сайт компании Intel, США. – http:// www.intel.com 8. Официальный сайт компании AMD, США. – http:// www.amd.com 9. Официальный сайт компании HP, США. – http:// www.hp.com 10. Официальный сайт компании IBM, США. – http:// www.ibm.com 11. Cайт информационных технологий. – http:// www.ixbt.com 12. Cайт высоких технологий IT-индустрии. – http://citforum.ru
Учебное издание
ЧЕРЕДОВ Андрей Дмитриевич
Поиск по сайту: |







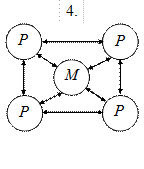





 Рис. 6.1. Классификация вычислительных систем с MIMD-архитектурой
Рис. 6.1. Классификация вычислительных систем с MIMD-архитектурой