|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Регистры отладки и тестирования. 5 страница
Рассмотрим предельно упрощенную схему функционирования памяти типа SDRAM (см. рис. 4.8, а). Ядро SDRAM-памяти и буферы ввода-вывода работают в синхронном режиме на одной и той же частоте. Передача каждого бита из буфера на шину происходит с каждым тактом работы ядра памяти. При переходе от SDRAM к DDR (см. рис.4.8, б) технология одинарной скорости передачи данных заменяется на удвоенную за счет того, что передача данных от микросхем памяти модуля к контроллеру памяти по внешней шине данных осуществляется по обоим полупериодам синхросигнала (восходящему – «фронту», и нисходящему – «срезу»). В этом и заключается суть технологии «Double Data Rate – DDR», именно поэтому «эффективная» частота памяти DDR-400 составляет 400 МГц, тогда как ее истинная частота, или частота буферов ввода-вывода, составляет 200 МГц. Таким образом, каждый буфер ввода-вывода передает на шину два бита информации за один такт, оставаясь при этом полностью синхронизированным с ядром памяти. Однако, чтобы такой режим работы стал возможным, необходимо, чтобы эти два бита были доступны буферу ввода-вывода на каждом такте работы памяти. Для этого требуется, чтобы каждая команда чтения приводила к передаче из ядра памяти в буфер сразу двух бит по двум независимым линиям передачи внутренней шины данных. Из буфера ввода-вывода биты данных затем поступают на внешнюю шину в требуемом порядке. Иными словами, можно сказать, что при прочих равных условиях внутренняя шина данных должна быть вдвое шире по сравнению с внешней шиной данных. Такая схема доступа к данным называется схемой «2n-предвыборки» (2n-prefetch). DDR-память, как и SDRAM, предназначалась для работы с системными частотами 100, 133, 166, 200, 216, 250 и 266 МГц. Нетрудно рассчитать пропускную способность DDR-памяти. Принимая, что ширина внешней шины данных составляет 8 байт, для памяти DDR-400 получаем 400 МГц х 8 байт = 3,2 Гбайт/с. Наиболее естественным путем решения проблемы достижения более высоких тактовых частот при переходе от DDR к DDR2 явилось снижение тактовой частоты внутренней шины данных вдвое по отношению к реальной тактовой частоте внешней шины данных (частоте буферов ввода-вывода). Так, в рассматриваемом примере микросхем памяти DDR2-800 (см. рис. 4.8, в) частота буферов составляет 400 МГц, а «эффективная» частота внешней шины данных – 800 МГц (поскольку сущность технологии Double Data Rate остается в силе). При этом частота внутренней шины данных (ядра памяти) составляет всего 200 МГц, поэтому для передачи 1 бита (по каждой линии данных) за такт внешней шины с «эффективной» частотой 800 МГц на каждом такте внутренней шины данных требуется передача уже 4 бит данных. Иными словами, внутренняя шина данных микросхемы памяти DDR2 должна быть в 4 раза шире по сравнению с её внешней шиной. Такая схема доступа к данным называется схемой «4n-предвыборки» (4n-prefetch). Ее преимущества перед схемой 2n-prefetch, реализованной в DDR, очевидны. С одной стороны, для достижения равной пиковой пропускной способности можно использовать вдвое меньшую внутреннюю частоту микросхем памяти (200 МГц для DDR-400 и всего 100 МГц для DDR2-400), что позволяет значительно снизить энергопотребление. С другой стороны, при равной внутренней частоте функционирования микросхем DDR и DDR2 (200 МГц как для DDR-400, так и DDR2-800) последние будут характеризоваться вдвое большей теоретической пропускной способностью. Но очевидны и недостатки – функционирование буферов ввода-вывода микросхем DDR2 на вдвое большей частоте и использование более сложной схемы преобразования «4–1» приводит к ощутимому возрастанию задержек (таймингов). Очередной «эволюционный скачок» в технологии реализации памяти DDR SDRAM это переход от стандарта DDR2 к новому стандарту DDR3. Нетрудно догадаться, что основной принцип, лежащий в основе перехода от DDR2 к DDR3, в точности повторяет рассмотренную выше идею, заложенную при переходе от DDR к DDR2.
Рис. 4.8. Схематическое представление передачи данных в микросхеме
Выборка широким словом Прямой способ сокращения числа обращений к ОП состоит в организации выборки широким словом. Этот способ основывается на свойстве локальности данных и программ. При выборке широким словом за одно обращение к ОП производится одновременная запись или считывание нескольких команд или слов данных из «широкой» ячейки. Широкое слово заносится в буферную память (кэш-память) или регистр, где оно расформировывается на отдельные команды или слова данных, которые могут последовательно использоваться процессором без дополнительных обращений к ОП. В системах с кэш-памятью первого уровня ширина шин данных ОП часто соответствует ширине шин данных кэш-памяти, которая во многих случаях имеет физическую ширину шин данных, соответствующую количеству разрядов в слове. Удвоение и учетверение ширины шин кэш-памяти и ОП удваивает или учетверяет соответственно полосу пропускания системы памяти.
Расслоение обращений Другой способ повышения пропускной способности ОП связан с построением памяти, состоящей на физическом уровне из нескольких модулей (банков) с автономными схемами адресации, записи и чтения. При этом на логическом уровне управления памятью организуются последовательные обращения к различным физическим модулям. Обращения к различным модулям могут перекрываться, и таким образом образуется своеобразный конвейер. Эта процедура носит название расслоения памяти. Целью данного метода является увеличение скорости доступа к памяти посредством совмещения фаз обращений ко многим модулям памяти. Известно несколько вариантов организации расслоения. Наиболее часто используется способ расслоения обращений за счет расслоения адресов. Этот способ основывается на свойстве локальности программ и данных, предполагающем, что адрес следующей команды программы на единицу больше адреса предыдущей (линейность программ нарушается только командами перехода). Аналогичная последовательность адресов генерируется процессором при чтении и записи слов данных. Таким образом, типичным случаем распределения адресов обращений к памяти является последовательность вида а, а + 1, а + 2, … Из этого следует, что расслоение обращений возможно, если ячейки с адресами а, а + 1, а + 2, … будут размещаться в блоках 0, 1, 2, …. Такое распределение ячеек по модулям (банкам) обеспечивается за счет использования адресов вида
где В – k-разрядный адрес модуля (младшая часть адреса) и С – n-разрядный адрес ячейки в модуле В (старшая часть адреса). Принцип расслоения обращений иллюстрируется на рис. 4.9, а. Все программы и данные «размещаются» в адресном пространстве последовательно. Однако ячейки памяти, имеющие смежные адреса, находятся в различных физических модулях памяти. Если ОП состоит из 4-х модулей, то номер модуля кодируется двумя младшими разрядами адреса. При этом полные m-разрядные адреса 0, 4, 8, … будут относиться к блоку 0, адреса 1, 5, 9, … – к блоку 1, адреса 2, 6, 10, … – к блоку 2 и адреса 3, 7, 11, … – к блоку 3. В результате этого последовательность обращений к адресам 0, 1, 2, 3, 4, 5, … будет расслоена между модулями 0, 1, 2, 3, 0, 1, …. Поскольку каждый физический модуль памяти имеет собственные схемы управления выборкой, можно обращение к следующему модулю производить, не дожидаясь ответа от предыдущего. Так на временной диаграмме (см. рис. 4.9, б) показано, что время доступа к каждому модулю составляет t = 4Т, где Т = ti+1 – ti – длительность такта. В каждом такте следуют непрерывно обращения к модулям памяти в моменты времени t1, t2, t3, …. При наличии четырех модулей темп выдачи квантов информации из памяти в процессор будет соответствовать одному такту Т, при этом скорость выдачи информации из каждого модуля в четыре раза ниже. Задержка в выдаче кванта информации относительно момента обращения также составляет 4Т, однако задержка в выдаче каждого последующего кванта относительно момента выдачи предыдущего составит Т. При реализации расслоения по адресам число модулей памяти может быть произвольным и необязательно кратным степени 2. В некоторых компьютерах допускается произвольное отключение модулей памяти, что позволяет исключать из конфигурации неисправные модули. В современных высокопроизводительных компьютерах число модулей обычно составляет 4 – 16, но иногда превышает 64.
а) организация адресного пространства; б) временная диаграмма работы модулей Так как схема расслоения по адресам базируется на допущении о локальности, она дает эффект в тех случаях, когда это допущение справедливо, т. е. при решении одной задачи. Для повышения производительности мультипроцессорных систем, работающих в многозадачных режимах, реализуют другие схемы, при которых различные процессоры обращаются к различным модулямпамяти. Необходимо помнить, что процессоры ввода-вывода также занимают циклы памяти и вследствие этого могут сильно влиять на производительность системы. Для уменьшения этого влияния обращения центрального процессора и процессоров ввода-вывода можно организовать к разным модулям памяти.
Прямое уменьшение числа конфликтов за счет организации чередующихся обращений к различным модулям памяти может быть достигнуто путем размещения программ и данных в разных модулях. Доля команд в программе, требующих ссылок к находящимся в ОП данным, зависит от класса решаемой задачи и от архитектурных особенностей компьютера. Для большинства ЭВМ с традиционной архитектурой и задач научно-технического характера эта доля превышает 50 %. Поскольку обращения к командам и элементам данных чередуются, то разделение памяти на память команд и память данных повышает быстродействие машины подобно рассмотренному выше механизму расслоения. Разделение памяти на память команд и память данных широко используется в системах управления или обработки сигналов. В подобного рода системах в качестве памяти команд нередко используются постоянные запоминающие устройства (ПЗУ), цикл которых меньше цикла устройств, допускающих запись, это делает разделение программ и данных весьма эффективным. Следует отметить, что обращения процессоров ввода-вывода в режиме прямого доступа в память логически реализуются как обращения к памяти данных. Выбор той или иной схемы расслоения для компьютера (системы) определяется целями (достижение высокой производительности при решении множества задач или высокого быстродействия при решении одной задачи), архитектурными и структурными особенностями системы, а также элементной базой (соотношением длительностей циклов памяти и узлов обработки). Могут использоваться комбинированные схемы расслоения. 4.4.3.
Оперативная память является важнейшим и наиболее дефицитным ресурсом в вычислительных машинах и системах, требующим тщательного и эффективного управления. Проблема усложняется при переходе к мультипрограммным системам, так как в них оперативную память одновременно используют несколько вычислительных процессов (программ). Типы адресов Для идентификации переменных и команд используются символьные имена (метки), виртуальные адреса и физические адреса (рис. 4.10). Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или ассемблере.
Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Так как во время трансляции в общем случае неизвестно, в какое место ОП будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Совокупность виртуальных адресов процесса (программы) называется виртуальным адресным пространством. Каждый процесс имеет собственное виртуальное адресное пространство. Максимальный размер виртуального адресного пространства ограничивается разрядностью адреса, присущей данной архитектуре компьютера и, как правило, не совпадает с объемом физической памяти, имеющимся в компьютере. Физические адреса соответствуют номерам ячеек ОП, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами. В первом случае замену виртуальных адресов на физические делает специальная системная программа – перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной транслятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая её с заменой виртуальных адресов физическими. Второй способ заключается в том, что программа загружается в память в неизменном виде в виртуальных адресах, при этом операционная система (ОС) фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к ОП выполняется преобразование виртуального адреса в физический. Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку. Вместе с тем использование загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае – каждый раз при обращении по данному адресу. В некоторых случаях (обычно в специализированных системах), когда заранее точно известно, в какой области ОП будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах. Классификация методов распределения оперативной памяти Все методы управления памятью могут быть разделены на два класса (см. рис. 4.11): · методы распределения ОП без использования внешней памяти (дискового пространства); · методы распределения памяти с использованием дискового пространства. Первая группа включает методы распределения памяти фиксированными, динамическими и перемещаемыми разделами. Вторая – страничное, сегментное и странично-сегментное распределение памяти.
Рассмотрим вначале первую группу методов. Распределение памяти фиксированными разделами Самым простым способом управления оперативной памятью является разделение её на несколько разделов (сегментов) фиксированной величины (статическое распределение). Это может быть выполнено вручную оператором во время старта системы или во время её генерации. Очередная задача, поступающая на выполнение, помещается либо в общую очередь (см. рис. 4.12, а), либо в очередь к некоторому разделу (см. рис. 4.12, б). Подсистема управления памятью в этом случае выполняет следующие задачи: сравнивает размер программы, поступившей на выполнение, и свободных разделов памяти; выбирает подходящий раздел; осуществляет загрузку программы и настройку адресов. При очевидном преимуществе, заключающемся в простоте реализации, данный метод имеет существенный недостаток – жёсткость. Так как в каждом разделе может выполняться только одна программа, то уровень мультипрограммирования заранее ограничен числом разделов независимо от того, какой размер имеют программы. Даже если программа имеет небольшой объём, она будет занимать весь раздел, что приводит к неэффективному использованию памяти. С другой стороны, даже если объём оперативной памяти машины позволяет выполнить некоторую программу, разбиение памяти на разделы не позволяет сделать этого.
Рис. 4.12. Распределение памяти фиксированными разделами: а – с общей очередью; б – с отдельными очередями Распределение памяти разделами переменной величины В этом случае память машины не делится заранее на разделы. Сначала вся память свободна. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объём памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На рис. 4.13 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так в момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5 задачами, причём задача П4, завершая работу, покидает память к моменту t2. На освободившееся место загружается задача П6, поступившая в момент t3. Задачами операционной системы при реализации данного метода управления памятью являются: ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти; анализ запроса (при поступлении новой задачи), просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи; загрузка задачи в выделенный ей раздел и корректировка таблиц свободных и занятых областей; корректировка таблиц свободных и занятых областей (после завершения задачи).
Программный код не перемещается во время выполнения, т. е. может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика. Выбор раздела для вновь поступившей задачи может осуществляться по разным правилам: «первый попавшийся раздел достаточного размера»; «раздел, имеющий наименьший достаточный размер»; «раздел, имеющий наибольший достаточный размер». Все эти правила имеют свои преимущества и недостатки. По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток – фрагментация памяти. Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объём памяти. Перемещаемые разделы Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов так, чтобы вся свободная память образовывала единую свободную область (рис. 4.14). В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей.
Эта процедура называется «сжатием». Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором – реже выполняется процедура сжатия. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом. Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода. 4.4.4.
Концепция виртуальной памяти Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений. Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем. В любой момент времени компьютер выполняет множество процессов или задач, каждый из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую оперативную память какой-то одной задаче, тем более, что многие задачи реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности. Она делит физическую память на блоки и распределяет их между различными задачами, при этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение. Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объёма. Раньше, если программа становилась слишком большой для физической оперативной памяти, часть её необходимо было хранить во внешней памяти (на диске) и задача приспособить её для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из неё под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведённого ей пространства физической памяти. Виртуальная память освободила программистов от этого бремени. Виртуальным называется такой ресурс, который для пользователя (пользовательской программы) представляется обладающим свойствами, которыми он в действительности не обладает. Так, например, пользователю может быть предоставлена виртуальная оперативная память, размер которой превосходит всю имеющуюся в системе реальную ОП. Пользователь пишет программы так, как будто в его распоряжении имеется однородная (одноуровневая) оперативная память большого объёма, но в действительности все данные, используемые программой, хранятся на нескольких разнородных запоминающих устройствах, обычно в ОП и на дисках, и при необходимости частями перемещаются между ними. Все эти действия выполняются автоматически, без участия программиста, т. е. механизм виртуальной памяти является прозрачным по отношению к пользователю.
Страничное распределение На рис. 4.15 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части, называемые виртуальными страницами, одинакового, фиксированного (для данной системы) размера. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью. Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами(или блоками). Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т. д., это позволяет упростить механизм преобразования адресов. При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные – на диск. Смежные виртуальные страницы необязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру – таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск (ВЗУ). Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемости (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчёта числа обращений за определённый период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти. При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса. При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
Поиск по сайту: |


 Рис. 4.9. Расслоение памяти:
Рис. 4.9. Расслоение памяти: Рис. 4.10. Типы адресов
Рис. 4.10. Типы адресов Рис. 4.11. Классификация методов распределения ОП
Рис. 4.11. Классификация методов распределения ОП
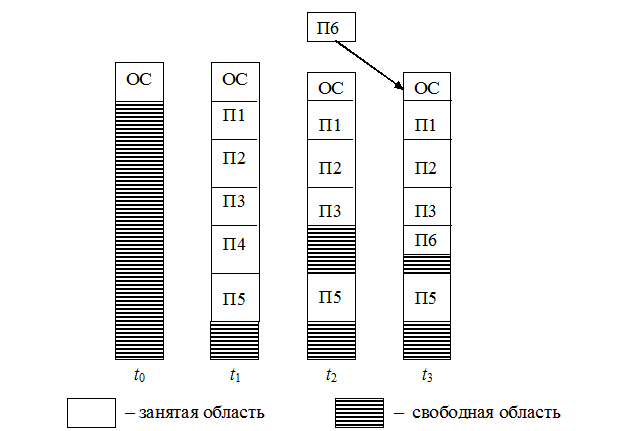 Рис. 4.13. Распределение памяти динамическими разделами
Рис. 4.13. Распределение памяти динамическими разделами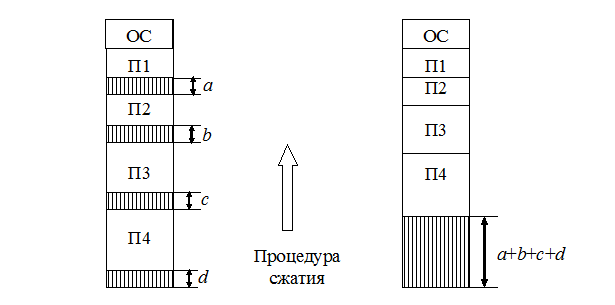 Рис. 4.14. Распределение памяти перемещаемыми разделами
Рис. 4.14. Распределение памяти перемещаемыми разделами