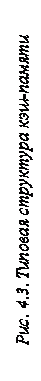|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Регистры отладки и тестирования. 4 страница
4.3.1. Типовая структура кэш-памяти Рассмотрим типовую структуру кэш-памяти (см. рис. 4.3), включающую основные блоки, которые обеспечивают её взаимодействие с ОП и центральным процессором. Строки, составленные из информационных слов, и связанные с ними адресные теги хранятся в накопителе, который является основой кэш-памяти, остальные блоки относятся к кэш-контроллеру. Адрес требуемого слова, поступающий от центрального процессора (ЦП), вводится в блок обработки адресов, в котором реализуются принятые в данной кэш-памяти принципы использования адресов при организации их сравнения с адресными тегами. Само сравнение производится в блоке сравнения адресов (БСА), который конструктивно совмещается с накопителем, если кэш-память строится по схеме ассоциативной памяти. Назначение БСА состоит в выявлении попадания или промаха при обработке запросов от центрального процессора. Если имеет место кэш-попадание (совпадение теговой части адреса, поступающего от центрального процессора, с адресным тегом одной из ячеек кэш-памяти), то в режиме чтения информации соответствующая строка из кэш-памяти переписывается в регистр строк. С помощью селектора из неё выделяется искомое слово, которое и направляется в центральный процессор. В случае промаха с помощью блока формирования запросов осуществляется инициализация выборки из ОП необходимой строки.
Адресация ОП при этом производится в соответствии с информацией, поступившей от центрального процессора. Выбираемая из памяти строка вместе со своим адресным тегом помещается в накопитель и регистр строк, а затем искомое слово передается в центральный процессор. В режиме записи информации в память адрес обрабатывается также, как и при чтении. Само же слово информации из ЦП проходит через демультиплексор и заносится в регистр строк. Далее, в зависимости от выбранного способа записи, оно может загрузиться в накопитель строк кэш-памяти и в ОП или только в кэш-память. Для высвобождения места в кэш-памяти с целью записи выбираемой из ОП строки одна из строк удаляется. Определение удаляемой строки производится посредством блока замены строк, в котором хранится информация, необходимая для реализации принятой стратегии обновления находящихся в накопителе строк. 4.3.2. Способы размещения данных в кэш-памяти
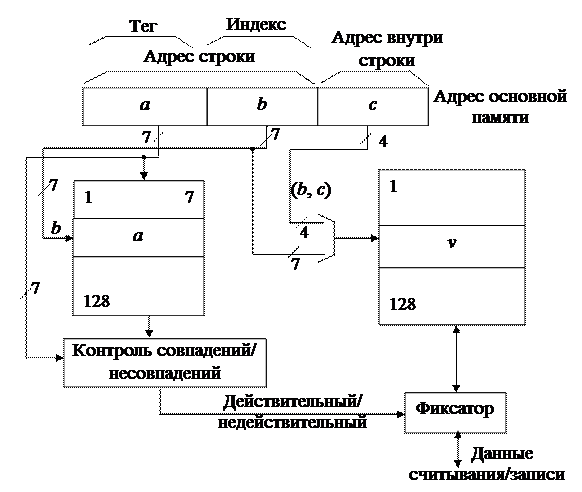
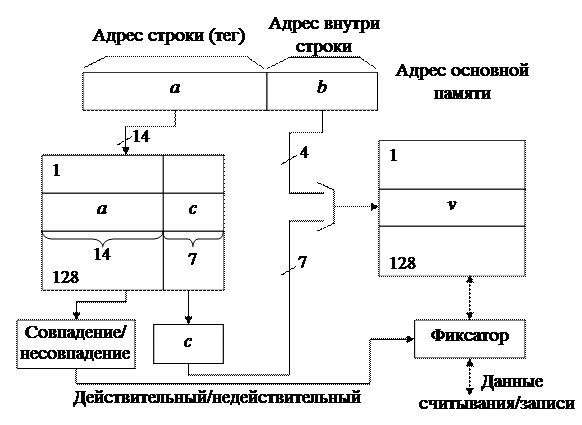
Из них старшие 14 показывают адрес строки, а младшие 4 бит – адрес слова внутри этой строки. При одном обращении к памяти выбирается одна строка. 128 строк кэш-памяти указываются 7-разрядными адресами. Прямое распределение При прямом распределении место хранения строк в кэш-памяти однозначно определяется по адресу строки (см. рис. 4.4). Адрес строки подразделяется на тег (старшие 7 бит) и индекс (младшие 7 бит). Для того, чтобы поместить в кэш-память строку из основной памяти с адресом bn, выбирается область внутри кэш-памяти с адресом bm, который равен 7 младшим битам адреса строки bn. Преобразование из bn в bm сводится только к выборке младших 7 бит адреса строки. По адресу bm в кэш-памяти может быть помещена любая из 128 строк основной памяти, имеющих адрес, 7 младших битов которого равны адресу bm. Для того чтобы определить, какая именно строка хранится в данное время в кэш-памяти, используется память ёмкостью 7 бит x 128 слов, в которую помещается по соответствующему адресу в качестве тега 7 старших битов адреса строки, хранящейся в данное время по адресу bm кэш-памяти. Это специальная память, называемая теговой памятью. Память, в которой хранятся строки, помещенные в кэш, называются памятью данных. В качестве адреса теговой памяти используются младшие 7 битов адреса строки.
Рис. 4.4. Структура кэш-памяти с прямым распределением При выполнении операции чтения (записи данных) из теговой памяти считывается тег. Параллельно этому осуществляется доступ к памяти данных с помощью 11 младших битов адреса основной памяти (используется 7 разрядов индекса и 4 разряда адреса слова внутри строки). Если считанный из теговой памяти тег и старшие 7 бит адреса основной памяти совпадают, то это означает, что данная строка существует в памяти данных, т. е. осуществляется кэш-попадание. В этом случае при чтении в процессор передается содержимое выбранной ячейки кэш-памяти, а при записи – в выбранную ячейку кэш-памяти загружается новая строка данных. Если выбранный тег отличается от старших 7 бит (кэш-промах), то из основной памяти считывается соответствующая строка, а из кэш-памяти удаляется строка, определяемая 7 младшими разрядами адреса строки, и на его место помещается строка, считанная из основной памяти. Осуществляется также обновление соответствующего тега в теговой памяти. Способ прямого распределения реализовать довольно просто, однако из-за того, что место хранения строки в кэш-памяти однозначно определяется по адресу строки, вероятность сосредоточения областей хранения строк в некоторой части кэш-памяти высока, т. е. замены строк будут происходить довольно часто. В такой ситуации эффективность кэш-памяти заметно снижается. Полностью ассоциативное распределение При полностью ассоциативном распределении (fully associative) допускается размещение каждой строки основной памяти на месте любой строки кэш-памяти. Структура кэш-памяти с полностью ассоциативным распределением представлена на рис. 4.5. Адрес основной памяти состоит из 14-разрядного адреса строки (тега) и 4-разрядного адреса внутри строки. При полностью ассоциативном распределении механизм преобразования адресов должен быстро дать ответ, существует ли копия строки с произвольно указанным адресом в кэш-памяти, и если существует, то по какому адресу. Для этого необходимо, чтобы теговая память была реализована, как ассоциативная память. Входной информацией для ассоциативной памяти тегов (ключ поиска) является тег – 14-разрядный адрес строки, а выходной информацией – адрес строки внутри кэш-памяти (памяти данных). Каждое слово теговой памяти состоит из 14-разрядного тега и 7-разрядного адреса строки памяти данных кэша. Ключ поиска параллельно сравнивается со всеми тегами ассоциативной памяти. При совпадении ключа с одним из тегов теговой памяти (кэш-попадание) происходит выборка соответствующего данному тегу адреса и обращение к памяти данных. Входной информацией для памяти данных является 11-разрядное слово (7 бит адреса строки и 4 бит адреса слова в данной строке). При выполнении операции чтения по этому адресу считывается и передается в процессор выбранная строка, а при записи – по этому же адресу в память данных записывается новая строка данных. При несовпадении ключа ни с одним из тегов теговой памяти (кэш-промах) осуществляется обращение к основной памяти и чтение необходимой строки.
Рис. 4.5. Структура кэш-памяти с полностью ассоциативным распределением По этому способу при замене строк кандидатом на удаление могут быть все строки в кэш-памяти. Частично ассоциативное распределение Если некоторая строка основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется частично ассоциативным или множественно ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа строк, расположенных в различных банках (блоках) данных. Если группа (множество) состоит из n – строк (банков, блоков), то такое размещение называется частично (множественно) ассоциативным с n каналами (n – way). В качестве примера рассмотрим структуру четырёх-канальной частично ассоциативной кэш-памяти (рис. 4.6). В этом случае 4 соседних строки из 128 строк кэш-памяти образуют структуру, называемую группой.
Рис. 4.6. Структура кэш-памяти с частично ассоциативным распределением Адрес строки основной памяти (14 бит) разделяется на две части: b – тег (старшие 9 бит) и е – адрес группы (младшие 5 бит). Адрес строки внутри кэш-памяти, состоящий из 7 бит, разделяется на адрес группы (5 бит) и адрес строки внутри группы (2 бита). Массивы тегов и данных состоят из четырех банков данных, доступ к каждому из которых осуществляется параллельно одинаковыми адресами. Каждый банк массива тегов имеет длину слова 9 бит для помещения значения тега, а число групп тегов в банке равно 32. Каждый банк массива данных имеет длину слова такую же, как и у основной памяти, а ёмкость его определяется числом слов в одной строке, умноженным на число групп в кэш-памяти. Для помещения в кэш-память строки, хранимой в ОП по адресу b, необходимо выбрать группу с адресом е. При этом не имеет значения, какая из четырёх строк в группе может быть выбрана. Для выбора группы используется метод прямого распределения, а для выбора строки в группе используется метод полностью ассоциативного распределения. Когда центральный процессор запрашивает доступ по i-му адресу к кэш-памяти с целью чтения или записи, то осуществляется обращение к массиву тегов по адресу е, выбирается группа из четырёх тегов (a, b, c, d), каждый из которых сравнивается со старшими 9 битами (b) адреса строки. На выходе четырёх схем сравнения формируется унитарный код совпадения (0100), который на шифраторе преобразуется в двухразрядный позиционный код, служащий адресом для выбора банка данных (01). При операции чтения (записи) одновременно осуществляется обращение к массиву данных по адресу e.f (9 бит) и считывание (запись) из банка (в банк) V2 требуемой строки или слова.
4.3.3. Методы обновления строк основной памяти и кэша В табл. 4.1 приведены условия сохранения и обновления информации в ячейках кэш-памяти и основной памяти. Если процессор намерен получить информацию из некоторой ячейки основной памяти, а копия содержимого этой ячейки уже имеется в кэш-памяти (первая строка табл. 4.1.), то вместо оригинала считывается копия. Информация в кэш-памяти и основной памяти не изменяется. Если копии нет, то производится обращение к основной памяти. Полученная информация пересылается в процессор и попутно запоминается в кэш-памяти. Чтение информации в отсутствии копии отражено во второй строке таблицы. Информация в основной памяти не изменяется. При записи существует несколько методов обновления старой информации. Эти методы называются стратегией обновления срок основной памяти. Если результат обновления строк кэш-памяти не возвращается в основную память, то содержимое основной памяти становится неадекватным вычислительному процессу. Чтобы избежать этого, предусмотрены методы обновления основной памяти, которые можно разделить на две большие группы: метод сквозной записи и метод обратной записи. Таблица 4.1 Условия сохранения и обновления информации
Сквозная запись По методу сквозной записи обычно обновляется слово, хранящееся в основной памяти. Если в кэш-памяти существует копия этого слова, то она также обновляется. Если же в кэш-памяти отсутствует копия этого слова, то либо из основной памяти в кэш-память пересылается строка, содержащая это слово (метод WTWA – сквозная запись с распределением), либо этого не допускается (метод WTNWA – сквозная запись без распределения). Когда по методу сквозной записи область (строка) в кэш-памяти назначается для хранения другой строки, то в основную память можно не возвращать удаляемый блок, так как копия там есть. Однако в этом случае эффект от использования кэш-памяти отсутствует. Обратная запись По методу обратной записи, если адрес объектов, по которым есть запрос обновления, существует в кэш-памяти, то обновляется только кэш-память, а основная память не обновляется. Если адреса объекта обновления нет в кэш-памяти, то в неё из основной памяти пересылается строка, содержащая этот адрес, после чего обновляется только кэш-память. По методу обратной записи в случае замены строк удаляемую строку необходимо также пересылать в основную память. У этого метода существуют две разновидности: метод SWB (простая обратная запись), по которому удаляемая строка возвращается в основную память, и метод FWB (флаговая обратная запись), по которому в основную память записывается только обновлённая строка кэш-памяти. В последнем случае каждая область строки в кэш-памяти снабжается однобитовым флагом, который показывает, было или нет обновление строки, хранящейся в кэш-памяти. Метод FWB обладает достаточной эффективностью, однако более эффективным считается метод FPWB (флаговая регистровая обратная запись), в котором благодаря размещению буфера между кэш-памятью и основной памятью предотвращается конфликт между удалением и выборкой строк. Таким образом, теоретически более предпочтительным алгоритмом записи для кэша является метод обратной записи. Кэш с обратной записью будет хранить новую информацию до тех пор, пока у него не появится необходимость избавиться от неё. Тем самым процессор может более оперативно управлять системой. В связи с тем, что кэш со сквозной записью сразу же передаёт вновь записанную информацию в память следующего уровня, кэш со сквозной записью может вызывать дополнительные потери в быстродействии по сравнению с кэшем с обратной записью. В случае кэша с обратной записью допускается выполнение длинных последовательностей быстрых операций записи из процессора, поскольку нет необходимости немедленно направлять эти данные в основную память. 4.3.4. Методы замещения строк кэш-памяти Способ определения строки, удаляемой из кэш-памяти, называется стратегией замещения. Для замещения строк кэш-памяти существует несколько методов: · замещение строки, к которой наиболее длительное время не было обращения (метод LRU); · первая загруженная в кэш-память строка замещается первой (метод FIFO); · произвольное замещение. Реализация этих методов упрощается в указанной последовательности, но наибольшим эффектом обладает метод замещения наиболее давнего по использованию объекта (строки). Для реализации этого метода необходимо манипулировать строками, которые являются объектами замещения, с помощью LRU-стека. При каждой загрузке в этот стек помещается строка, в результате чего при замене используется строка, хранящаяся в наиболее глубокой позиции стека, и эта строка удаляется из стека. При доступе к строке, которая уже содержится в LRU-стеке, эта строка удаляется из стека и заново загружается в него. Стек типа LRU устроен таким образом, что, чем дольше к строке не было доступа, тем в более глубокой позиции она располагается. Реализация стека типа LRU, позволяющего с высокой скоростью выполнять такую операцию, усложняется по мере увеличения числа строк. 4.3.5.
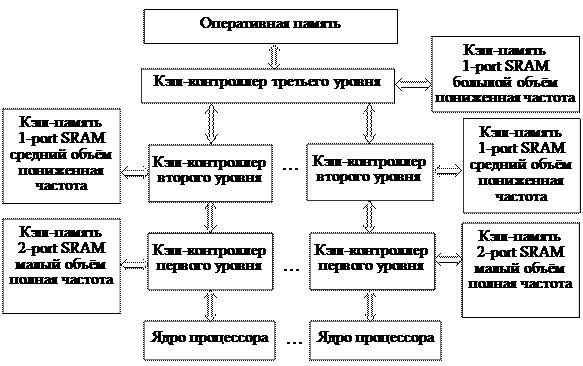
Предельно достижимая ёмкость кэш-памяти ограничена не только её ценой, но и электромагнитной интерференцией, налагающей жёсткие ограничения на максимально возможное количество адресных линий, а значит – на непосредственно адресуемый объём памяти. В принципе, можно прибегнуть к мультиплексированию выводов или последовательной передаче адресов, но это неизбежно снизит производительность и увеличит время доступа к ячейке кэш-памяти. С другой стороны, двухпортовая статическая память действительно очень дорогая, а однопортовая не в состоянии обеспечить параллельную обработку нескольких ячеек, что приводит к досадным задержкам. Естественный выход состоит в создании многоуровневой кэш-иерархии (см. рис. 4.7). Большинство современных компьютеров имеют два или три уровня кэш-памяти. Первый, наиболее «близкий» к ядру процессора (L1), обычно реализуется на быстрой двухпортовой синхронной статической памяти, работающей на полной частоте ядра. Объём L1-кэша весьма невелик, составляет 64 КВ или 128 КВ и разделяется пополам на два кэша данных и команд для каждого ядра процессора. Латентность кэша L1 измеряется 3-мя, 4-мя тактами. На втором уровне расположен кэш L2. Он реализуется на однопортовой конвейерной статической памяти и зачастую работает на пониженной тактовой частоте. Поскольку однопортовая память значительно дешевле, объём L2-кэша достигает нескольких мегабайт в двухъядерных структурах процессоров, когда он является общим для двух ядер (Intel Core 2 Duo), или несколько сотен килобайт (256 КВ или 512 КВ), когда в многоядерном процессоре каждое ядро имеет свой L2-кэш (см. рис. 4.7). Этот кэш хранит как команды, так и данные. Латентность L2 для процессоров Intel Nehalem 3,2 ГГц составляет 11 тактов, для Penryn 3,2 ГГц – 18 тактов.
Рис. 4.7. Трехуровневая структура кэш-памяти многоядерного процессора На третьем уровне находится L3-кэш, который объединяет ядра между собой и является разделяемым. В результате, L2-кэш выступает в качестве буфера при обращениях процессорных ядер в разделяемую кэш-память, имеющую достаточно солидный объём (2 МВ – AMD K10, 8 МВ – Intel Nehalem). Латентность L3-кэша исчисляется 52-мя, 54-мя тактами. При построении многоуровневой кэш-памяти используют включающую (inclusive) или исключающую (exclusive) технологии. Кэш верхнего уровня, построенный по inclusive-технологии, всегда дублирует содержимое кэша нижнего уровня. Если построить инклюзивный L3-кэш, то он будет дублировать данные, хранящиеся в кэшах первого и второго уровней, что снижает эффективную ёмкость всей кэш-подсистемы. С другой стороны, инклюзивный разделяемый L3-кэш способен обеспечить в многоядерных процессорах более высокую скорость работы подсистемы памяти. Это связано с тем, что, если ядро попытается получить доступ к данным, и они отсутствуют в кэше L3, то нет необходимости искать эти данные в собственных кэшах других ядер – там их нет. А благодаря тому, что каждая строка L3-кэша снабжена дополнительными флагами, указывающими владельцев (ядра) этих данных, не вызывает затруднений и процедура обратного изменения содержимого строки кэша. Так, если какое-то ядро модифицирует данные в L3-кэше, изначально принадлежащие другому (или другим) ядрам, то в этом случае обновляется содержимое L1 и L2-кэшей и этих ядер. Эта технология весьма эффективна для обеспечения когерентности персональных кэшей каждого ядра, поскольку она уменьшает потребность в обмене информацией между ядрами. По такой технологии организована кэш-память процессоров Intel Nehalem. Кэш – подсистема, построенная по exclusive-технологии, никогда не хранит избыточных копий данных и потому эффективная ёмкость подсистемы определяется суммой ёмкостей кэш-памятей всех уровней. Кэш первого уровня никогда не уничтожает строки при нехватке места. Даже если они не были модифицированы, данные в обязательном порядке вытесняются в кэш второго уровня, помещаясь на то место, где находилась только что переданная кэшу L1 строка. Т. е. кэши L1 и L2 как бы обмениваются друг с другом своими строками, а потому кэш-память используется весьма эффективно. По такой технологии организована кэш-память процессоров AMD K10. 4.4. Принципы организации оперативной памяти 4.4.1. Общие положения Оперативная (основная) память представляет собой следующий уровень иерархии памяти. Оперативная память удовлетворяет запросы кэш-памяти и устройств ввода/вывода. Она является местом назначения для ввода и источником для вывода. Для оценки производительности (быстродействия) основной памяти используются следующие параметры: время доступа, длительность цикла памяти, латентность и пропускная способность. Как было сказано выше, время доступа – это время, проходящее с момента обращения к памяти до момента считывания данных. Данная величина приблизительно одинакова для всех типов динамической памяти и составляет примерно 50 нсек. Время доступа актуально при случайном доступе к памяти, т. е., когда последовательно считываемые ячейки памяти принадлежат различным строкам матрицы памяти. Если говорить о блочной передачи, то более показательной характеристикой является время цикла, т. е. время между двумя последовательными обращениями к ячейкам памяти. Первый цикл обращения всегда равен времени доступа, т. е. около 50 нс. Но при последующих циклах обращения в пределах одной страницы (строки матрицы) время существенно меньше и составляет 10 нс или 7,5 нс. Любая динамическая память характеризуется циклами доступа, записываемыми в виде цепочек типа 5–1–1–1 или 5–2–2–2 и т. д. Такая цепочка определяет количество тактов, необходимых для чтения первых четырех элементов (байт, слово, двойное слово) данных в страничном режиме доступа. Первая цифра в таком обозначении определяет время доступа, то есть количество тактов, прошедших от начала обращения к банку памяти до появления данных на шине. Соответственно, при работе в страничном режиме следующие данные появятся на шине уже через меньшее количество тактов. Например, при цепочке 5–1–1–1 последующие данные появляются без задержек, т. е. с каждым тактовым импульсом. Латентность памяти определяется некоторым набором значений временных задержек, происходящих в модуле памяти с момента прихода команды чтения (записи) до ее выполнения. Эти значения задержек принято называть таймингами. При описании памяти принято использовать четыре тайминга tCL, tRCD, tRP, tRAS (иногда дополнительно указывается и Command rate), причем записываются они обычно в этой же последовательности в виде 4–4–4–12 (1Т), где цифры указывают количество затраченных тактов синхронизации (в данном случае цифровые значения взяты произвольно). Перед тем, как расшифровать аббревиатуры указанных таймингов, несколько слов о принципах организации и работы оперативной памяти. Ядро памяти организовано в виде двумерной матрицы. Для получения доступа к той или иной ячейке необходимо указать адреса соответствующей строки и столбца. Для ввода адреса строки используется стробирующий сигнал RAS, а для адреса столбца – стробирующий сигнал CAS. Порядок обращения к памяти начинается с установки регистров управления. После чего вырабатывается сигнал выбора нужного банка памяти и по прошествии (задержки) Command rate осуществляется ввод адреса строки и подача стробирующего сигнала RAS (обычно эта задержка составляет один или два такта). С приходом положительного фронта тактового импульса открывается доступ к нужной строке, а адрес строки помещается в адресный буфер строки, где он может удерживаться столько времени, сколько нужно. Через промежуток времени, называемый RAS to CAS delay (tRCD) – то есть задержка подачи сигнала CAS относительно сигнала RAS, подается стробирующий импульс CAS, под действием которого происходит выборка адреса столбца и открывается доступ к нужному столбцу матрицы памяти. Затем, через время CAS latency (tCL), на шине данных появляется первое слово, которое может быть считано процессором. После завершения работы со всеми ячейками активной строки выполняется команда деактивации Precharge, позволяющая перейти к следующей строке (tRP – это time of Row Precharge: тайминг между завершением обработки одной строки и перехода к другой). Значение tRAS (time of Active to Precharge Delay) считается одним из основных параметров, поскольку он описывает время задержки между моментом активации строки и моментом подачи команды деактивации Precharge, которой заканчивается работа с этой строкой. Общее правило гласит: чем меньше тайминги при одной тактовой частоте, тем быстрее память. Более того, в целом ряде случаев быстрее оказывается память с меньшими таймингами, работающая даже на более низкой тактовой частоте. Память с более высокой тактовой частотой имеет, как правило, более высокие тайминги. Другой важнейшей характеристикой ОП является ее пропускная способность, которая определяется как произведение частоты работы памяти на объем данных, передаваемых за один такт. Самый простой способ увеличения максимальной пропускной способности памяти заключается в увеличении частоты ее работы. Однако на практике реализовать это совсем не просто. Вспомним, что элементарной ячейкой динамической памяти является конденсатор – инерционное по своей природе устройство. Чтобы произвести считывание информации с конденсатора, необходимо его разрядить, для чего требуется определенное время, пропорциональное емкости конденсатора, – сделать это мгновенно невозможно. Следовательно, нельзя повышать частоту ядра памяти до бесконечности. Кроме того, динамическая память требует периодической регенерации, чтобы восстанавливать заряды конденсаторов, а для зарядки конденсаторов тоже необходим определенный временной интервал. В результате повышение частоты ядра памяти сопряжено с непреодолимыми трудностями. Конечно, применение более миниатюрных конденсаторов повышает их быстродействие, однако для этого нужно использовать иную проектную норму при производстве чипов памяти. К тому же переход на новый технологический процесс производства не может кардинально увеличить скорость работы памяти. Поэтому, кроме банального увеличения частоты работы памяти, для увеличения ее пропускной способности часто используют другие приемы. 4.4.2. Методы повышения пропускной способности ОП Согласование производительности современных процессоров со скоростью ОП остается одной из важнейших проблем. Методы повышения производительности за счет увеличения размеров кэш-памяти и введения многоуровневой организации кэш-памяти полностью не решают эту проблему. Поэтому важным направлением современных разработок являются методы повышения пропускной способности памяти за счет ее организации, включая специальные способы организации DRAM. Развитие способов организации памяти DDR SDRAM Кардинальным способом увеличения пропускной способности ОП стал переход к стандарту DDR. Динамическая память DDR SDRAM пришла на смену синхронной SDRAM и обеспечила в два раза большую пропускную способность. Аббревиатура DDR (Double Data Rate) означает удвоенную скорость передачи данных. Как уже отмечалось выше, основным сдерживающим элементом увеличения тактовой частоты работы памяти является ядро памяти (массив элементов хранения – Memory Cell Array). Однако, кроме ядра в модуле памяти присутствуют и буферы промежуточного хранения (буферы ввода-вывода – I/O Buffers), через которые ядро памяти обменивается данными с шиной памяти. Эти буферы могут иметь значительно более высокое быстродействие, чем само ядро, поэтому тактовую частоту работы шины памяти и буферов обмена можно легко увеличить. Именно такой способ и используется в DDR-памяти.
Поиск по сайту: |