|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Функция оценки качества разбиения
Обучение дерева решений относится к классу обучения с учителем, то есть обучающая и тестовая выборки содержат классифицированный набор примеров. Оценочная функция, используемая алгоритмом CART, базируется на интуитивной идее уменьшения нечистоты (неопределённости) в узле. Обучение дерева решений относится к классу обучения с учителем, то есть обучающая и тестовая выборки содержат классифицированный набор примеров. Оценочная функция, используемая алгоритмом CART, базируется на интуитивной идее уменьшения нечистоты (неопределённости) в узле. Рассмотрим задачу с двумя классами и узлом, имеющим по 50 примеров одного класса. Узел имеет максимальную "нечистоту". Если будет найдено разбиение, которое разбивает данные на две подгруппы 40:5 примеров в одной и 10:45 в другой, то интуитивно "нечистота" уменьшится. Она полностью исчезнет, когда будет найдено разбиение, которое создаст подгруппы 50:0 и 0:50. В алгоритме CART идея "нечистоты" формализована в индексе Gini. Если набор данных Т содержит данные n классов, тогда индекс Gini определяется как: Если набор Т разбивается на две части
Наилучшим считается то разбиение, для которого Обозначим N – число примеров в узле – предке, L, R – число примеров соответственно в левом и правом потомке,
Чтобы уменьшить объем вычислений формулу можно преобразовать:
Так как умножение на константу не играет роли при минимизации:
В итоге, лучшим будет то разбиение, для которого величина максимальна. Правила разбиения Вектор предикторных переменных, подаваемый на вход дерева может содержать как числовые (порядковые) так и категориальные переменные. В любом случае в каждом узле разбиение идет только по одной переменной. Если переменная числового типа, то в узле формируется правило вида xi <= c. Где с – некоторый порог, который чаще всего выбирается как среднее арифметическое двух соседних упорядоченных значений переменной xi обучающей выборки. Если переменная категориального типа, то в узле формируется правило xi V(xi), где V(xi) – некоторое непустое подмножество множества значений переменной xi в обучающей выборке. Следовательно, для n значений числового атрибута алгоритм сравнивает n-1 разбиений, а для категориального (2n-1 – 1). На каждом шаге построения дерева алгоритм последовательно сравнивает все возможные разбиения для всех атрибутов и выбирает наилучший атрибут и наилучшее разбиение для него. Предлагаемое алгоритмическое решение. Договоримся, что источник данных, необходимых для работы алгоритма, представим как плоская таблица. Каждая строка таблицы описывает один пример обучающей/тестовой выборки. Каждый шаг построения дерева фактически состоит из совокупности трех трудоемких операций. Первое – сортировка источника данных по столбцу. Необходимо для вычисления порога, когда рассматриваемый в текущий момент времени атрибут имеет числовой тип. На каждом шаге построения дерева число сортировок будет как минимум равно количеству атрибутов числового типа. Второе – разделение источника данных. После того, как найдено наилучшее разбиение, необходимо разделить источник данных в соответствии с правилом формируемого узла и рекурсивно вызвать процедуру построения для двух половинок источника данных. Обе этих операции связаны (если действовать напрямую) с перемещением значительных объемов памяти. Здесь намеренно источник данных не называется таблицей, так как можно существенно снизить временные затраты на построение дерева, если использовать индексированный источник данных. Обращение к данным в таком источнике происходит не напрямую, а посредством логических индексов строк данных. Сортировать и разделять такой источник можно с минимальной потерей производительности. Третья операция, занимающая 60–80% времени выполнения программы – вычисление индексов для всех возможных разбиений. Если у Вас n – числовых атрибутов и m – примеров в выборке, то получается таблица n*(m-1) – индексов, которая занимает большой объем памяти. Этого можно избежать, если использовать один столбец для текущего атрибута и одну строку для лучших (максимальных) индексов для всех атрибутов. Можно и вовсе использовать только несколько числовых значений, получив быстрый, однако плохо читаемый код. Значительно увеличить производительность можно, если использовать, что L = N – R, li = "ni" – ri , а li и ri изменяются всегда и только на единицу при переходе на следующую строку для текущего атрибута. То есть подсчет числа классов, а это основная операция, будет выполняться быстро, если знать число экземпляров каждого класса всего в таблице и при переходе на новую строку таблицы изменять на единицу только число экземпляров одного класса – класса текущего примера. Все возможные разбиения для категориальных атрибутов удобно представлять по аналогии с двоичным представлением числа. Если атрибут имеет n – уникальных значений. 2n – разбиений. Первое (где все нули) и последнее (все единицы) нас не интересуют, получаем 2n – 2. И так как порядок множеств здесь тоже неважен, получаем (2n – 2)/2 или (2n-1 – 1) первых (с единицы) двоичных представлений. Если {A, B, C, D, E} – все возможные значения некоторого атрибута X, то для текущего разбиения, которое имеет представление, скажем {0, 0, 1, 0, 1} получаем правило X in {C, E} для правой ветви и [ not {0, 0, 1, 0, 1} = {1, 1, 0, 1, 0} = X in {A, B, D} ] для левой ветви. Часто значения атрибута категориального типа представлены в базе как строковые значения. В таком случае быстрее и удобнее создать кэш всех значений атрибута и работать не со значениями, а с индексами в кэше.
Поиск по сайту: |
 , где
, где  – вероятность (относительная частота) класса i в T.
– вероятность (относительная частота) класса i в T.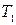 и
и 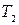 с числом примеров в каждом
с числом примеров в каждом  и
и  соответственно, тогда показатель качества разбиения будет равен:
соответственно, тогда показатель качества разбиения будет равен: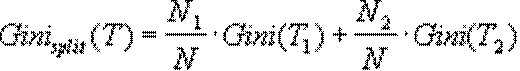
 минимально.
минимально. и
и 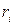 – число экземпляров i-го класса в левом/правом потомке. Тогда качество разбиения оценивается по следующей формуле:
– число экземпляров i-го класса в левом/правом потомке. Тогда качество разбиения оценивается по следующей формуле:

