|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
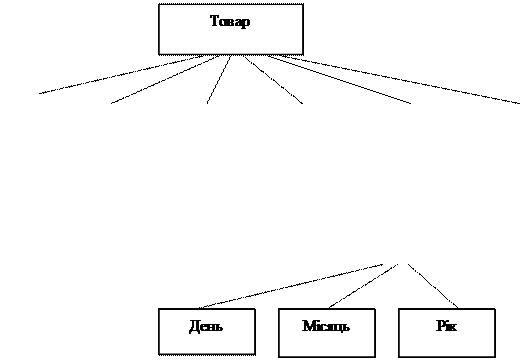
Варіанти індивідуальних завдань. 1. Для структури даних, яка наведена на рисунку 5.3 необхідно створити масив записів та
1. Для структури даних, яка наведена на рисунку 5.3 необхідно створити масив записів та визначити: а) фірму, товар якої надходить частіше за всіх; б) фірму, товар якої надходить рідше за всіх.
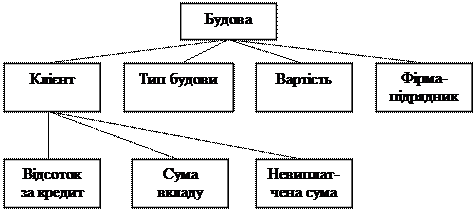
2. Для структури даних, наведеної на рисунку 5.4, необхідно створити масив записів та визначити: 2.1. Визначити клієнтів, у яких сума у банку менш вартості будови; 2.2. Визначити клієнта, який повністю розрахувався за будову; 2.3. Визначити тип будови, яку клієнти замовляли більш 2-х разів; 2.4. Визначити тип будови з максимальною вартістю; 2.5. Визначити невиплачену суму всіх клієнтів; 2.6. Визначити клієнта з максимально не оплаченою сумою.
3. Для структури даних, наведеної на рисунку 5.5, необхідно створити масив записів та визначити:
Рисунок 5.3 3.1. Загальну собівартість реалізованого товару; 3.2. Найбільш рентабельний вид діяльності, виходячи з показників чистого прибутку; 3.3. Фірми, у яких чистий прибуток вище його середнього значення по всіх фірмах; 3.4. Самий нерентабельний тип діяльності, виходячи з показників чистого прибутку.
Рисунок 5.4
Рисунок 5.5
5.4 Контрольні питання та завдання
1. Надайте загальне поняття структури даних. 2. Що розуміється під поняттям «порядок доступу до даних»? Які види доступу ви знаєте? 3. Надайте характеристику масиву як базової структури. 4. Назвіть основні типи змінних, які використовуються у Сі. Яким чином вони використовуються? 5. Що таке символьні та логічні змінні? 6. Що таке вирази, як їх використовують у програмах? 7. Що таке текстові строки? 8. Яким чином у програмах реалізується доступ до даних? 9. Надайте логічний опис елементарних структур даних – черга та стек. 10. Що таке множини та навантажені множини, 11. Які можливості має С++ для реалізації навантажених множин, 6. СТВОРЕННЯ ТА ОБРОБКА СПИСКІВ У СЕРЕДОВИЩІ С++
Мета роботи
Вивчення методів реалізації списків у середовищі мови С++. Отримання практичних навичок по використанню списків при вирішенні практичних завдань. 6.2 Організація самостійної роботи студентів
Під час підготовки до виконання лабораторної роботи необхідно вивчити індивідуальне завдання (п. 6.3), виконати розробку алгоритму вирішення задачі та підготовити текст програми щодо реалізації розробленого алгоритму, підготовити відповідні розділи звіту та вивчити відповідний теоретичний матеріал, який викладено у лекціях: „Реалізація структур даних у С++ на основі посилань”, „Списки та їх реалізація у С++”, та у наступних підручниках і навчальних посібниках [1, 4, 5, 7, 8]. Більшість структур даних реалізується на базі масиву. Всі реалізації можна розділити на два класи: безперервні та з посиланням. У безперервних реалізаціях елементи структури даних розташовуються послідовно один за одним у безперервному відрізку масиву, причому порядок їхнього розташування в масиві відповідає їхньому порядку в реалізованій структурі. У реалізаціях з посиланням елементи структури даних зберігаються в довільному порядку. При цьому разом з кожним елементом зберігаються посилання на один або кілька сусідніх елементів. Як посилання можуть використовуватися або індекси елементів масиву, або адреси пам'яті. Реалізації з посиланнями мають два яскраво виражені недоліки: 1) для зберігання посилань потрібна додаткова пам'ять; 2) для доступу до деякого елемента структури необхідно спочатку добратися до нього, проходячи послідовно, по ланцюжку, інші елементи. Виникає питання, навіщо потрібні такі реалізації? Всі недоліки реалізацій з посиланнями компенсуються одним надзвичайно важливим достоїнством: в них можна додавати та вилучати елементи в середині структури даних, не переміщаючи інші елементи. Класичний приклад структури даних послідовного доступу, у якій можна видаляти та додавати елементи в середині структури – це лінійний список. Розрізняють списки з одним та двома напрямками (іноді говорять однозв'язний і двозв’язний). Елементи списку розміщені в ланцюжку, один за одним (рисунок 6.1). У списку є початок та кінець. Є також покажчик списку, що розташовується між елементами. У будь-який момент часу в списку доступні лише два елементи – елементи до покажчика та за покажчиком.
Рисунок 6.1 – Загальний вигляд списку
У списку з одним напрямком покажчик можна пересувати лише в одному напрямку – уперед, у напрямку від початку до кінця. Крім того, можна встановити покажчик на початок списку, перед його першим елементом. На відміну від списку з одним напрямком, список з двома напрямками абсолютно симетричний, покажчик у ньому можна пересувати вперед та назад, а також встановлювати, як перед першим, так і за останнім елементами списку. У списку з двома напрямками можна додавати та видаляти елементи до та за покажчиком. У списку з одним напрямком додавати елементи можна також по обидва боки від покажчика, але вилучати елементи можна тільки за покажчиком. На практиці вважається, що перед першим елементом списку розташовується спеціальний порожній елемент, який називається головою списку. Голова списку присутній завжди, навіть у порожньому списку. Завдяки цьому можна припускати, що перед покажчиком завжди є якийсь елемент, що спрощує процедури додавання та вилучення елементів. У списку з двома напрямами вважають, що за останнім елементом списку знову йде голова списку, тобто список зациклений у кільце (рисунок 6.2).
Рисунок 6.2 – Вигляд списку з двома напрямками
Можна було б точно так само зациклити і список з одним напрямком. Але набагато частіше вважають, що за останнім елементом списку з одним напрямком нічого нема. Список з одним напрямком, таким чином, представляє собою ланцюжок (рисунок 6.3), що починається з голови списку, за яким знаходиться перший елемент, потім другої і так далі аж до останнього елемента, а закінчується ланцюжок посиланням у нікуди.
Рисунок 6.3 – практична реалізація списку з одним напрямком Вище означене є абстрактним поняттям списку. Але в програмуванні найчастіше ототожнюють поняття списку з його реалізацією на базі масиву або безпосередньо на базі оперативної пам'яті. Основна ідея реалізації списку з одним напрямком полягає в тім, що разом з кожним елементом списку зберігаються посилання на наступний та попередній елементи. У випадку реалізації на базі масиву посилання представляють собою індекси елементів масиву. Частіше, однак, елементи списку не розташовують у якому-небудь масиві, а просто розміщають кожний окремо в оперативній пам'яті, виділеній даній задачі. (Звичайно елементи списку розміщаються в так званій динамічній пам'яті, або купі). Як посилання в цьому випадку використовують адреси елементів в оперативній пам'яті. Голова списку зберігає посилання на перший та останній елементи списку. Оскільки список зациклений у кільце, то наступним за головою списку буде його перший елемент, а попередньої – останній елемент. Голова списку зберігає тільки посилання і не зберігає ніякого елемента. Це як би порожній ящик, у який не можна нічого покласти і який використовується тільки для того, щоб написати на ньому адреси наступного та попереднього ящиків, тобто першого і останнього елементів списку. Коли список порожній, голова списку зациклений сам на себе. Покажчик списку реалізується у вигляді посилання на наступний і попередній елементи, він просто відзначає деяке місце в ланцюжку елементів. У випадку списку з одним напрямком зберігається тільки посилання на наступний елемент, таким чином заощаджується пам'ять. Голова списку з одним напрямком зберігає посилання на перший елемент списку. Останній елемент списку зберігає нульове посилання, тобто посилання в нікуди, тому що в програмах нульова адреса ніколи не використовується. Цінність реалізації списку з посиланнями полягає в тому, що процедури додавання та вилучення елементів не призводять до масових операцій. Розглянемо, наприклад, операцію вилучення елемента за покажчиком. Зчитуючи посилання на наступний елемент в елементі, що вилучається, ми знаходимо, який елемент повинен бути наступним за покажчиком після видалення поточного елемента. Після цього досить зв'язати елемент до покажчика з новим елементом за покажчиком. А саме, позначимо через X адресу елемента до покажчика, через Y – адресу нового елемента за покажчиком. У поле наступного елемента з адресою X треба записати значення Y, а у поле попереднього елемента з адресою Y – значення X. Таким чином, при вилученні елемента за покажчиком він виключається з ланцюжка списку. Для цього досить лише поміняти посилання у двох сусідніх елементах. Аналогічно, для додавання елемента досить включити його в ланцюжок, а для цього також потрібно всього лише модифікувати посилання у двох сусідніх елементах. Елемент, що додається, може розташовуватися де завгодно, отже, немає ніяких проблем із захопленням і звільненням пам'яті під елементи.
Поиск по сайту: |