|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Варіанти індивідуальних завдань. ЗМІСТ Загальні положенняСтр 1 из 10Следующая ⇒
ЗМІСТ
ЗАГАЛЬНІ ПОЛОЖЕННЯ Дисципліна «Алгоритмізація та програмування» є дисципліною циклу професійної та практичної підготовки студентів. В плані підготовки студентів дисципліна є базовою. Роль і значення дисципліни полягає в наступному: уміння програмувати є необхідним навиком для всіх студентів, які вивчають інформатику; навички, що їх отримують студенти, повинні забезпечити розширення наукового кругозору майбутнього фахівця, дати можливість успішно оволодіти суміжними спеціальностями і ефективно застосовувати сучасні інформаційні технології, тому опанування програмуванням на початку курсу навчання гарантує, що студенти матимуть потрібні знання під час переходу до основних і поглиблених дисциплін, споріднених з програмуванням. Ця дисципліна дає навики та тренінг, необхідний для студентів у їх майбутній роботі. Мета викладання навчальної дисципліни «Алгоритмізація та програмування» полягає в тому, щоб навчити студентів використовувати основні прийоми програмування з урахуванням сучасних концепцій і тенденцій розвитку технологій програмування, розв’язувати реальні науково-технічні задачі різної складності за допомогою комп’ютерів. В даній дисципліни вирішуються такі основні завдання: вивчаються теоретичні принципи та практичні прийоми структурного, процедурного, модульного програмування з реалізацією різними мовами програмування; опановується технологія розробки алгоритмів прикладних задач на структурах даних, кодування вибраною мовою програмування, налагодження програми, оцінки достовірності отриманих результатів. Мета методичних вказівок – допомогти студентам поглибити теоретичні знання з дисципліни та отримати практичні навички у використанні теоретичних знань у практиці алгоритмізації та розробки програмних засобів. Лабораторні роботи розраховані на самостійну і активну діяльність кожного студента, добрі знання з основ алгоритмізації та програмування, дискретної та вищої математики. Під час підготовки до виконання чергової лабораторної роботи студенти зобов’язані вивчити відповідні матеріали літератури, що рекомендується, зазначення щодо їх виконання та відповідний лекційний матеріал. Для виконання лабораторних робіт використовуються ПЕОМ, оснащених стандартним набором приладів введення-виведення. До складу програмного забезпечення входять засоби операційної системи, стандартні загальносистемні програмні засоби та інструментальні засоби створення програм. Завдання для виконання кожної з лабораторних робіт надає керівник. Студентам може бути запропонована індивідуальна постановка задачі. У зв’язку із обмеженою кількістю робочих місць студентська група за рішенням викладача може бути поділена на декілька підгруп. Перед початком лабораторної роботи викладач виконує перевірку підготовленості студентів до її виконання, результати самостійної роботи та знання з відповідної теми теоретичного матеріалу. При незадовільній підготовленості студент може бути відсторонений від виконання лабораторної роботи. За наслідками виконання лабораторної роботи кожним студентом оформлюється звіт. Зміст звіту, зазначення щодо обробки результатів виконання лабораторної роботи та їхнього оформлення наведено при описі кожної лабораторної роботи. До здачі звіту допускаються студенти, які виконали відповідні роботи і отримали позитивні оцінки за наслідками їх виконання. За рішенням викладача, найбільш успішним студентам залік з відповідною оцінкою може виставлятися за результатами допуску, виконання лабораторної роботи та оформлення звіту. Основний зміст лабораторних робіт полягає у виконанні відповідних завдань: 1. Вивчення теоретичного матеріалу щодо основ алгоритмізації та програмування з використанням мови С++. 2. Використання можливостей середовища Borland C++ Builder по створенню, трансляції та налагодженню програм. 3. Ознайомлення із індивідуальним завданням на виконання відповідної лабораторної роботи. 4. Розробка алгоритму вирішення задачі щодо індивідуального завдання. 5. Розробка тексту програми у відповідності із розробленим алгоритмом. 6. Розробка тестових прикладів по налагодженню програми. 7. Використання середовища Borland C++ Builder для створення програми та її налагодження. Порядок виконання лабораторної роботи складається з таких етапів: 1. Подати керівнику занять підготовлену під час самостійної роботи програму виконання лабораторної роботи, до складу якої входить: - оформлені розділи звіту у складі: титульного аркушу, мети роботи, постановки задачі у відповідності із індивідуальним завданням, алгоритму та тексту програми, тестових прикладів для перевірки працездатності програми; - підготовлені програмні документи у складі специфікації та тексту програми. 2. Введення тексту програми з використанням середовища Borland C++ Builder. 3. Виконання операцій по трансляції та налагодження програми. 4. Аналіз отриманих результатів, дооформлення звіту та програмних документів. 5. Захист звіту перед викладачем. Звіт з лабораторної роботи повинен складатися з (Додаток В): - титульного аркуша із зазначенням назви роботи, групи та прізвища студента, який виконував роботу (Додаток Б); - мети роботи; - постановки задачі у відповідності із індивідуальним завданням; - розділу „Самостійна робота по підготовці до лабораторної роботи” у складі опису методу вирішення задачі, алгоритму вирішення задачі та його опису, тексту програми та контрольних прикладів для перевірки працездатності програми; - розділу „Виконання експериментів по налагодженню програми” у складі результатів трансляції та налагодження програми у відповідності із підготовленими контрольними прикладами; - висновків за результатами виконання лабораторної роботи; - додатку у складі визначених викладачем програмних документів. Студенти, які не здали виконану лабораторну роботу без поважних причин, до виконання наступних робіт не допускаються.
1 ВИВЧЕННЯ МОЖЛИВОСТЕЙ СЕРЕДОВИЩА BORLAND C++ BUILDER. СТВОРЕННЯ, ТРАНСЛЯЦІЯ ТА НАЛАГОДЖЕННЯ ПРОГРАМ
Мета роботи
Вивчення можливостей середовища Borland C++ Builder. Створення, трансляція та налагодження програм. Отримання практичних навичок алгоритмізації задач та створення програм з використанням мови С++.
1.2 Організація самостійної роботи студентів Під час підготовки до виконання лабораторної роботи необхідно вивчити індивідуальне завдання (п. 1.3), виконати розробку алгоритму вирішення задачі та підготовити текст програми щодо реалізації розробленого алгоритму, підготовити відповідні розділи звіту та вивчити відповідний теоретичний матеріал, який викладено у лекціях: „Основи мови С++, структура програми, типи змінних”, „Операції мови С++: арифметичні, збільшення, зменшення, логічні”, „Керуючі конструкції мови С++” та у наступних підручниках і навчальних посібниках [1, 2, 4, 5, 7, 8]. При вивченні теоретичного матеріалу необхідно усвідомити, що будь-яка програма (проект) на Сі складається з файлів. Файли транслюються Сі-компілятором незалежно одне від одного, а потім поєднуються програмою -побудовником задач. За наслідками цього створюється файл із програмою, готовою до виконання. Файли, що містять тексти Сі-програми, називаються вихідними. У мові Сі вихідні файли бувають двох типів: · заголовні, або h-файли; · файли реалізації, або Сі-файли. Назви заголовних файлів мають розширення ".h". Назви файлів реалізації мають розширення ".c" для мови Сі й ".cpp", ".cxx" або ".cc" для мови C++. Заголовні файли містять тільки описи. Файли реалізації, або Cі-файли, містять тексти функцій і визначення глобальних змінних. Говорячи спрощено, Сі-файли містять самі програми, а h-файли - лише інформацію про програми. Подання вихідних текстів у вигляді заголовних файлів і файлів реалізації необхідно для створення великих проектів, що мають модульну структуру. Заголовні файли використовуються для передачі інформації між модулями. Файли реалізації – це окремі модулі, які розробляються та транслюються незалежно одне від одного та поєднуються при створенні виконуваної програми. Файли реалізації підключають заголовні файли за допомогою директиви препроцесора #include. Самі заголовні файли також можуть використовувати інші заголовні файли. Функція є основною структурною одиницею мови Сі. В інших мовах функції називають підпрограмами. Функція – це фрагмент програми, що може викликатися з інших програм. Функція звичайно алгоритм, що описується та реалізується окремо від інших алгоритмів. При виклику функції передаються аргументи, які можуть бути використані в тілі функції. За результатами роботи функція повертає значення деякого типу. Розглянемо приклад програми, яка виводить на екран фразу "Hello, World". #include <stdio.h> int main() { printf("Hello, World\n"); return 0; }
Перший рядок підключає заголовний файл із описом стандартних функцій введення даних Сі-бібліотеки. У файлі описаний прототип функції printf (друк за форматом). Виконання програми починається з функції main, яка повертає після закінченні роботи ціле число (рядок return 0;), що трактується операційною системою, як код завершення завдання. Число нуль означає успішне виконання задачі, але програміст може самостійно визначати коди завершення. При розгляді типів змінних у C++ варто розрізняти поняття базового типу та конструкції, що дозволяє будувати нові типи на основі вже побудованих. Базових типів зовсім небагато – це цілі та дійсні числа, які розрізняються за діапазонами можливих значень (або по довжині в байтах) та логічний тип даних. До конструкцій відноситься масив, покажчик та структура, а також клас. Цілочисельні типи розрізняються по довжині в байтах і по наявності знака. Їх чотири – char, short, int і long. Крім того, до опису можна додавати модифікатори unsigned або signed для беззнакових (ненегативних) або знакових цілих чисел. Дійсних типів даних два: довгі дійсні числа double (тобто "подвійна точність") та коротке дійсне число float (тобто "плаваюче"). Дійсне число типу double займає 8 байтів, типу float – 4 байти. Тип double є основним для комп'ютера. У мові C++ уведено логічний тип bool. Змінні типу bool приймають два значення: false та true. Слова false та true є ключовими словами мови C++. При вивченні типів даних необхідно звернути увагу на те, як вони представлені у машинному форматі та особливості їх опису у програмах. Для створення нових типів у Сі використовуються конструкції масиву, покажчика та структури. Опис масиву складається з назви базового типу, назви масиву та його розміру, що вказується у квадратних дужках. Розмір масиву обов'язково повинен бути цілочисельною константою або константним виразом. Наприклад: int a[10];char c[256];double d[1000];
У першому рядку описаний масив цілих чисел з 10 елементів. Необхідно пам’ятати, що нумерація в Сі завжди починається з нуля, тому індекси елементів масиву змінюються в межах від 0 до 9. У другому рядку описаний масив символів з 256 елементів (індекси в межах 0...255), у третьому – масив дійсних чисел з 1000 елементів (індекси в межах 0...999). Для доступу до елемента масиву вказується ім'я масиву та індекс елемента у квадратних дужках, наприклад: a[10], c[255], d[123]. Покажчики – це змінні, які зберігають адреси об'єктів. При описі покажчика треба задати тип об'єктів, адреси яких будуть знаходитися в ньому. Перед ім'ям покажчика при описі ставиться зірочка, щоб відрізнити його від звичайної змінної. Приклади описів покажчиків: int *a, *b, c, d;char *e;void *f;
У першому рядку описані покажчики a і b на тип int та прості змінні c та d типу int (c і d – не є покажчиками!). З покажчиками можливі наступні дві дії: 1. Присвоїти покажчику адресу деякої змінної. Для цього використовується операція узяття адреси, що позначається амперсендом &. Наприклад, рядок a = &c; дозволяє покажчику a присвоїти значення адреси змінної c; 2. Одержати об'єкт, адреса якого записана у покажчику; для цього використовується операція зірочка «*», що записується перед покажчиком. Наприклад, рядок d = *a; присвоює змінній d значення цілочисельної змінної, адреса якої записана в a. Конструкції масиву та покажчика при описі типу можна застосовувати багаторазово в довільному порядку. Крім того, можна описувати прототип функції. У такий спосіб можна будувати складні описи начебто "масив покажчиків", "покажчик на покажчик", "покажчик на масив", "функція, що повертає значення типу покажчик", "покажчик на функцію" та інше. Правила тут такі: · для угруповання можна використовувати круглі дужки, наприклад, опис int *(x[10]); означає "масив з 10 елементів типу покажчик на int"; · при відсутності дужок пріоритети конструкцій опису розподілені в такий спосіб: o операція * визначення покажчика має найнижчий пріоритет. Наприклад, опис int *x[10]; означає "масив з 10 елементів типу покажчик на int". Тут до ім'я змінної x спочатку застосовується операція визначення масиву [] (квадратні дужки), оскільки вона має більше високий пріоритет, чим зірочка. Потім до отриманого масиву застосовується операція визначення покажчика. У результаті виходить "масив покажчиків", а не покажчик на масив! Якщо нам потрібно визначити покажчик на масив, то варто використовувати круглі дужки при описі: int (*x)[10]; Тут до ім'я x спочатку застосовується операція * визначення покажчика; o операції визначення масиву [] (квадратні дужки після ім'я) та визначення функції (круглі дужки після ім'я) мають однаковий пріоритет, більше високий, ніж зірочка. Приклади: - int f(); Описано прототип функції f без аргументів, що повертає значення типу int; - int (*f())[10]; Описано прототип функції f без аргументів, що повертає значення типу покажчик на масив з 10 елементів типу int; · останній приклад не є очевидним. Загальний алгоритм розбору складного опису можна охарактеризувати як читання зсередини. Спочатку знаходимо описуване ім'я. Потім визначаємо, яка операція застосовується до ім'я першої. Якщо немає круглих дужок для угруповання, то це або визначення покажчика (зірочка ліворуч від імені), або визначення масиву (квадратні дужки праворуч від імені), або визначення функції (круглі дужки праворуч від імені). Так виконується перший крок аналізу складного опису. Потім знаходимо наступну операцію опису, що застосовується до вже виділеної частини складного опису, та повторюємо це доти, поки не вичерпаємо весь опис. Розглянемо цей алгоритм на наступному прикладі: void (*a[100])(int x);Описується змінна a. До неї спочатку застосовується операція опису масиву з 100 елементів, далі – визначення покажчика, далі – функція від одного цілочисельного аргументу x типу int, нарешті – визначення типу, що повертається, void. Опис читається в такий спосіб: 1. a - це 2. Масив з 100 елементів типу 3. Покажчик на 4. Функцію з одним аргументом x типу int, що повертає значення типу 5. void. Нижче розставлені номери операцій у порядку їхнього застосування в описі змінної a: void (* a [100])(int x);5) 3) 1) 2) 4) Спеціального типу даних рядок у Сі немає. Рядки представляються масивами символів (а символи – їхніми числовими кодами). Останнім символом масиву, що представляє рядок, повинен бути символ з нульовим кодом. Приклад: char str[10];str[0] = 'e'; str[1] = '2';str[2] = 'e'; str[3] = '4';str[4] = 0;
Описано масив str з 10 символів, що може представляти рядок довжиною не більше 9, оскільки один елемент повинен бути зарезервований для завершального нуля. Далі в масив str записується рядок "e2e4". Рядок завершується нульовим символом. Усього запис рядка використовує 5 перших елементів масиву str з індексами 0...4. Останні 5 елементів масиву не використовуються. Масив можна ініціалізувати безпосередньо при описі, наприклад: char t[] = "abc";
Тут не вказується у квадратних дужках розмір масиву t, компілятор його обчислює сам. Після операції присвоювання записана строкова константа "abc", що заноситься в масив t. У результаті компілятор створює масив t із чотирьох елементів, оскільки на рядок приділяється 4 байти, включаючи завершальний нуль. Строкові константи записуються у подвійних апострофах, на відміну від символьних, які записуються в одинарні. Вирази у Сі складаються зі змінних або констант, до яких застосовуються різні операції. Для вказівки порядку операцій можна використовувати круглі дужки. Відзначимо, що, крім звичайних операцій, таких, як додавання або множення, у Сі існує ряд операцій, трохи незвичних для початківців. Наприклад, кома та знак рівняння (оператор присвоювання) є операціями в Сі; крім операції додавання +, є ще операція збільшити на += та операція збільшення на одиницю ++. Найчастіше вони дозволяють писати естетично гарні, але не дуже зрозумілі для починаючих програми. Втім, ці незвичні операції можна не використовувати, заміняючи їх традиційними. До чотирьох звичайних арифметичних операцій додавання +, відрахування – , множення * та ділення / у Сі додана операція знаходження остачі від ділення першого цілого числа на друге, котра позначається символом відсотка %. Пріоритет в операції обчислення остачі % такий же, як і в ділення або множення. Відзначимо, що операція % перестановочна з операцією зміни знака (унарним мінусом), наприклад, за наслідками виконання двох рядків Операція порівняння порівнює два вирази. За наслідками виробляється логічне значення – true або false залежно від значень виразів. Приклади: bool res;int x, y;res = (x == y); // true, якщо x дорівнює y, інакше falseres = (x == x); // завжди trueres = (2 < 1); // завжди false
Операції порівняння в Сі позначаються в такий спосіб: == дорівнює, != не дорівнює,> більше, >= більше або дорівнює,< менше, <= менше або дорівнює.Крім звичайних логічних операцій, у Сі є побітові логічні операції, які виконуються незалежно для кожного окремого біта операндів. Побітові операції мають наступні позначення: & побітове логічне додавання ("і")| побітове логічне множення ("або")~ побітове логічне заперечення ("не")^ побітове додавання по модулі 2 (виключне "або")
(Необхідно пам'ятати, що логічні операції множення та додавання записуються за допомогою подвійних знаків && або ||, а побітові – за допомогою одинарних.) В основному побітові операції застосовуються для маніпуляцій з бітовими масками. Наприклад, нехай ціле число x описує набір ознак деякого об'єкта, що складає із чотирьох ознак. Назвемо їх умовно A, B, C, D. Нехай за ознаку A відповідає нульовий біт слова x (біти у двійковому поданні числа нумеруються з праворуч на ліворуч, починаючи з нуля). Якщо біт дорівнює одиниці (програмісти говорять біт установлений), то вважається, що об'єкт має ознаку A. За ознаки B, C, D відповідають біти з номерами 1, 2, 3. Загальноприйнята практика полягає в тому, щоб визначити константи, відповідальні за відповідні ознаки (їх звичайно називають масками): const int MASK_A = 1;const int MASK_B = 2;const int MASK_C = 4;const int MASK_D = 8;
Ці константи містять одиницю у відповідному біті та нулі в інших бітах. Для того щоб перевірити, чи встановлений у слові x біт, що відповідає, приміром, ознаці D, використовується операція побітового логічного множення. Число x множиться на константу MASK_D; якщо результат відмінний від нуля, то біт встановлений, тобто об'єкт має ознаку D, якщо ні, то не встановлений. Така перевірка реалізується наступним фрагментом: if ((x & MASK_D) != 0) { // Біт D установлений у слові x, тобто // об'єкт має ознаку D . . .} else { // Об'єкт не має ознаку D . . .}При побітовому логічному множенні константа MASK_D обнулює всі біти слова x, крім біта D, тобто якби вирізує біт D з x. У двійковому поданні це виглядає так: x: 0101110110...10*101MASK_D: 0000000000...001000x & MASK_D: 0000000000...00*000
Зірочкою тут позначене довільне значення біта D слова x. Для встановлення біта D у слові x використовується операція побітового логічного додавання: x = (x | MASK_D); // Установити біт D у слові x
Частіше це записується з використанням операції типу "збільшити на": x |= MASK_D; // Установити біт D у слові x
У двійковому представленні це виглядає так: x: 0101110110...10*101MASK_D: 0000000000...001000x | MASK_D: 0101110110...101101
Операція побітового заперечення "~" інвертує біти слова: x: 0101110110...101101~x: 1010001001...010010
Для очищення (тобто установки в нуль) біта D використовується комбінація операцій побітового заперечення та побітового логічного множення: x = (x & ~MASK_D); // Очистити біт D у слові x
або, застосовуючи операцію "&=" типу "помножити на": x &= ~MASK_D; // Очистити біт D у слові x
Тут спочатку інвертується маска, що відповідає біту D, MASK_D: 0000000000...001000~MASK_D: 1111111111...110111
у результаті виходять одиниці у всіх бітах, крім біта D. Потім слово x побітно помножується на інвертовану маску: x: 0101110110...10*101~MASK_D: 1111111111...110111x & ~MASK_D: 0101110110...100101
У результаті в слові x біт D обнулюється, а інші біти залишаються незмінними.
Операції зміщення застосовуються до цілочисельних змінних: двійковий код числа зміщується вправо або вліво на зазначену кількість позицій. Зміщення вправо позначається двома символами "більше" >>, зміщення вліво – двома символами "менше" <<. Приклади: int x, y;. . .x = (y >> 3); // Зрушення на 3 позиції вправоy = (y << 2); // Зрушення на 2 позиції вліво
При зміщенні вліво на k позицій молодші k розрядів результату встановлюються в нуль. Зміщення вліво на k позицій еквівалентно множенню на число 2k. Зміщення вправо більше складне, воно по-різному визначається для беззнакових та знакових чисел. При зміщенні вправо беззнакового числа на k позицій k старших розрядів, що звільнилися, установлюються в нуль. Наприклад, у двійковому записі маємо: unsigned x; x = 110111000...10110011x >> 3 = 000110111000...10110
Зміщення вправо на k позицій відповідає цілочисельному діленню на число 2k. При зміщенні вправо чисел зі знаком відбувається так зване "розширення знакового розряду". А саме, якщо число позитивне, тобто старший, або знаковий, розряд числа дорівнює нулю, то відбувається звичайне зміщення, як і у випадку беззнакових чисел. Якщо ж число негативне, тобто його старший розряд дорівнює одиниці, то ті розряди, що звільнилися в результаті зміщення k старших розрядів, установлюються в одиницю. Число, таким чином, залишається негативним. При k = 1 це відповідає діленню на 2 тільки для негативних чисел, не рівних -1. Для числа -1, всі біти двійкового коду якого дорівнюють одиниці, зміщення вправо не приводить до його зміни. Приклад (використовується двійковий запис): int x;x = 110111000...10110011x >> 3 = 111110111000...10110
У програмах краще не покладатися на цю особливість зміщення вправо для знакових чисел і використовувати конструкції, які свідомо однаково працюють для знакових та беззнакових чисел. Наприклад, у наступному фрагменті коду із цілого числа виділяються його складові байти та записуються до цілочисельних змінних x0, x1, x2, x3, молодший байт в x0, старший в x3. При цьому байти трактуються як позитивні числа. Фрагмент виконується однаково для знакових та беззнакових чисел: int x;int x0, x1, x2, x3;. . .x0 = (x & 255);x1 = ((x >> 8) & 255);x2 = ((x >> 16) & 255);x3 = ((x >> 24) & 255);
Тут число 255 відіграє роль маски. При побітовому множенні на цю маску із цілого числа вирізьблюється його молодший байт, оскільки маска 255 містить одиниці в молодших вісьмох розрядах. Щоб одержати байт числа x з номером n, n = 0,1,2,3, необхідно спочатку змістити двійковий код x вправо на 8n розрядів, таким чином, байт із номером n стає молодшим. Потім за допомогою побітового множення вирізьблюється молодший байт. Керуючі конструкції дозволяють організовувати цикли та розгалуження в програмах. У Си всього кілька конструкцій, причому половину з них можна не використовувати (вони реалізуються через інші). Оператор if ("якщо") дозволяє організувати розгалуження в програмі. Він має дві форми: оператор "якщо" і оператор "якщо...інакше". Оператор "якщо" має вигляд: if (умова) дія;оператор "якщо...інакше" має вигляд if (умова) дія1;else дія2; Як умову можна використовувати будь-який вираз логічного або цілого типу. Нагадаємо, що при використанні цілочисельного виразу значенню "істина" відповідає будь-яке ненульове значення. При виконанні оператора "якщо" спочатку обчислюється умовний вираз після if. Якщо воно дійсне, то виконується дія, якщо воно не дійсне, то нічого не відбувається. Наприклад, у наступному фрагменті в змінну m записується максимальне зі значень змінних x та y: double x, y, m;. . .m = x;if (y > x) m = y;
При виконанні оператора "якщо...інакше" у випадку, коли умова істинна, виконується дія, що записана після if; у противному випадку виконується дія після else. Наприклад, попередній фрагмент запишеться в такий спосіб: double x, y, m;. . .if (x > y) m = x;else m = y;
Коли треба виконати кілька дій залежно від істинності умови, необхідно використовувати фігурні дужки, поєднуючи декілька операторів у блок, наприклад: double x, y, d;. . .if (d > 1.0) { x /= d; y /= d;} Тут змінні x та y діляться на d тільки в тому випадку, коли значення d більше одиниці. Кілька умовних операторів типу "якщо...інакше" можна записувати послідовно (тобто дія після else можна знову записати умовний оператор). У результаті реалізується вибір з декількох можливостей. Конструкція вибору використовується в програмуванні дуже часто. Приклад: є дійсна змінна x, необхідно записати у дійсну змінну y значення функції sign(x): sign(x) = -1, при x < 0sign(x) = 1, при x > 0sign(x) = 0, при x = 0 Це робиться з використанням конструкції вибору: double x, s;. . .if (x < 0.0) { s = (-1.0);}else if (x > 0.0) { s = 1.0;}else { s = 0.0;}
При виконанні цього фрагмента спершу перевіряється умова x < 0.0. Якщо вона дійсна, то виконується оператор s = (-1.0); інакше перевіряється друга умова x < 0.0. У випадку його істинності виконується оператор s = 1.0, інакше виконується оператор s = 0.0. Фігурні дужки тут додані для поліпшення структурності тексту програми. У кожному разі, у результаті виконання конструкції вибору виконується лише один з операторів (можливо, складових). Умови перевіряються послідовно зверху донизу. Як тільки є дійсна умова, то виконується відповідна дія і вибір закінчується. Конструкція циклу "доки" відповідає циклу while: while (умова) дія;
Цикл while називають циклом із передумовою, оскільки умова перевіряється перед виконанням тіла циклу. Цикл while виконується в такий спосіб: спочатку перевіряється умова. Якщо вона дійсна, то виконується дія. Потім знову перевіряється умова; якщо вона дійсна, то знову повторюється дія, і так нескінченно. Цикл завершується, коли умова стає помилковою. Приклад: int n, p;. . .p = 1;while (2*p <= n) p *= 2;
У результаті виконання цього фрагмента в змінної p буде обчислений максимальний ступінь двійки, який не переважає цілого позитивного числа n. Якщо необхідно перервати виконання циклу, то необхідно використовувати оператор
break; Оператор застосовується усередині тіла циклу у фігурних дужках. Приклад: потрібно знайти корінь цілочисельної функції f(x), дійсної для цілочисельних аргументів. int f(int x); // Опис прототипу функції. . .int x;. . .// Шукаємо корінь функції f(x)x = 0;while (true) { if (f(x) == 0) { break; // Знайшли корінь } // Переходимо до наступного цілого значення x // у порядку 0, -1, 1, -2, 2, -3, 3, ... if (x >= 0) { x = (-x - 1); } else { x = (-x); }}// Твердження: f(x) == 0
Тут використовується нескінченний цикл "while (true)". Вихід із циклу здійснюється за допомогою оператора "break". Іноді потрібно пропустити виконання тіла циклу при яких-небудь значеннях змінних у циклі, переходячи до наступного набору значень і чергової ітерації. Для цього використовується оператор: continue;
Оператор continue, так само, як і break, використовується лише в тому випадку, коли тіло циклу складається більш ніж з одного оператора та вставлено у фігурні дужки. Його варто розуміти як перехід на фігурну дужку, що закриває тіло циклу. Приклад: нехай заданий n+1 крапка на дійсній прямій
Нехай потрібно обчислити значення елементарного інтерполяційного багаточлена double x[100]; // Вузли інтерполяції (не більше 100)int n; // Кількість вузлів інтерполяціїint k; // Номер вузлаdouble t; // Крапка, у якій обчислюється значенняdouble L; // Значення багаточлена L_k(x) у tint i;. . .L = 1.0; // Початкове значення добуткуi = 0;while (i <= n) { if (i == k) { ++i; // До наступного вузла continue; // Пропустити k-й множник } // Обчислення добутку L *= (t - x[i]) / (x[k] - x[i]); ++i; // До наступного вузла}// Відповідь у змінної L
Тут оператор continue використовується для того, щоб пропустити обчислення при i = k. Циклу for має вигляд: for (ініціалізація; умова продовження; ітератор) тіло циклу;Ініціалізація виконується один раз перед першою перевіркою умови продовження та першим виконанням тіла циклу. Умова продовження перевіряється перед кожним виконанням тіла циклу. Якщо умова істинна, то виконується тіло циклу, інакше цикл завершується. Ітератор виконується після кожного виконання тіла циклу (перед наступною перевіркою умови продовження). Оскільки умова продовження перевіряється перед виконанням тіла циклу, цикл for є, подібно циклу while, циклом із передумовою. Якщо умова продовження ніколи не виконується, то тіло циклу не виконується жодного разу, що добре як з погляду надійності програми, так і з погляду простоти та естетики (оскільки не потрібно окремо розглядати виняткові випадки). Розглянемо приклад підсумовування масиву з використанням циклу for: double a[100]; // Масив a містить не більше 100 эл-тівint n; // Реальна довжина масиву a (n <= 100)double sum; // Змінна для суми эл-тів масивуint i; // Змінна циклу. . .sum = 0.0;for (i = 0; i < n; ++i) { sum += a[i]; // Збільшуємо суму на a[i]}
Тут цілочисельна змінна i використовується як змінна циклу. В операторі ініціалізації змінної i присвоюється значення 0. Умовою продовження циклу є умова i<n. Ітератор ++i збільшує змінну i на одиницю. Таким чином, змінна i послідовно приймає значення 0, 1, 2,..., n-1. Для кожного значення i виконується тіло циклу. При вивченні керуючих конструкцій необхідно ознайомитися із логічним представлення цих конструкцій у вигляді алгоритмів з використанням графічної мови, що описана у Єдиній системі програмної документації (ЄСПД). Варіанти індивідуальних завдань 1. Для масиву 7
2. Для масиву 7
3. Для матриці 6
4. Для масиву 7
5. Для масиву 6
6. Для масиву 7
7. Для матриці 7
8. Для матриці 6
9. Для матриці 7
10. Для матриці 7
1.3 Контрольні питання та завдання 1. З яких частин складається Сі – програма? 2. Що таке заголовочні файли та файли реалізації? Їх призначення. 3. Назвіть основні типи змінних мови Сі. 4. Які типи змінних входять до базових? 5. Надайте характеристику цілочисельних типів даних: int, char, short, long. 6. Надайте характеристику дійсних типів даних: float, double. 7. Надайте характеристику типу даних void. 8. Надайте характеристику наступним конструкціям даних: масив, вказівник, структура. 9. Що таке вирази у мові Сі? 10. Назвіть арифметичні операції, які використовуються у мові Сі? 11. Що таке операції збільшення та зменшення? Їх форми. 12. Що таке операції „збільшення на”, „зменшення на”? Їх різновид. 13. Які логічні операції використовуються у мові Сі? 14. Що таке операції порівняння? 15. Які побітові логічні операції використовуються у мові Сі? 16. Які операції зміщення використовуються у мові Сі? 17. Надайте характеристику керуючим конструкціям мови Сі: if-else, if-else if, while, for. 18. Назвіть основні можливості інструментального засобу Borland C++ Builder. 19. З яких частин складаються такі програмні документи як специфікація та текст програми.
2 ВИВЧЕННЯ МОЖЛИВОСТЕЙ МОВИ С++ ПРИ РОБОТІ З ФУНКЦІЯМИ Мета роботи Вивчення можливостей мови С++ при роботі з функціями. Отримання практичних навичок по створенню, трансляції та налагодження програм, які використовують функції, у середовищі Borland C++ Builder.
2.2 Організація самостійної роботи студентів
Під час підготовки до виконання лабораторної роботи необхідно вивчити індивідуальне завдання (п. 2.3), виконати розробку алгоритму вирішення задачі та підготовити текст програми щодо реалізації розробленого алгоритму, підготовити відповідні розділи звіту та вивчити відповідний теоретичний матеріал, який викладено у лекціях: „Керуючі конструкції мови С++”, „Представлення програми у вигляді функції”, та у наступних підручниках і навчальних посібниках [1, 2, 4, 5, 7, 8]. Завжди перед використанням або реалізацією функції необхідно описати її прототип. Прототип функції включає інформацію про ім'я функції, типі значення, що повертається, кількості та типах її аргументів. Приклад: int gcd(int x, int y);
Тут описано прототип функції gcd, що повертає ціле значення із двома цілими аргументами. Імена аргументів x та y тут є лише коментаріями, тому що не несуть ніякої інформації для компілятора. Їх можна опускати, наприклад, опис int gcd(int, int);
є цілком припустимим. Описи прототипів функцій взагалі виносяться в заголовні файли. Для коротких програм, які містяться в одному файлі, опис прототипів розташовують на початку програми. У мові Сі функціям передаються значення фактичних параметрів. При виклику функції значення параметрів копіюються в апаратний стек. Варто чітко розуміти, що зміна формальних параметрів у тілі функції не призводить до зміни змінних програми, переданих функції при її виклику – адже функція працює не із самими цими змінними, а з копіями їхніх значень! Розглянемо наступний приклад фрагменту програми: void f(int x); // Опис прототипу функції int main() { . . . int x = 5; f(x); // Значення x як і раніше дорівнює 5 . . .} void f(int x) { . . . x = 0; // Зміна формального параметра . . . // не приводить до зміни фактичного // параметра в зухвалій програмі}
Тут функція main викликає функцію f, якій передається значення змінної x, рівне п'яти. Незважаючи на те, що в тілі функції f формальному параметру x присвоюється значення 0, значення змінної x у функції main не міняється. Якщо необхідно, щоб функція могла змінити значення змінних програми, треба передавати їй покажчики на ці змінні. Тоді функція може записати будь-яку інформацію з переданих адрес. У Сі в такий спосіб реалізуються вихідні та вхідно-вихідні параметри функцій. У традиційних мовах програмування, таких як Сі, Фортран, Паскаль, існують три види пам'яті: статична, стекова та динамічна. Звичайно, з фізичної точки зору, ніяких різних видів пам'яті немає: оперативна пам'ять – це масив байтів, кожний байт має адреса, починаючи з нуля. Коли говориться про види пам'яті, маються на увазі способи організації роботи з нею, включаючи виділення та звільнення пам'яті, а також методи доступу. Статична пам'ять виділяється ще до початку роботи програми, на стадії компіляції та складання. Статичні змінні мають фіксовану адресу, відому до запуску програми та не змінну в процесі її роботи. Статичні змінні створюються та ініціалізуються до входу у функцію main, з якої починається виконання програми. Існує два типи статичних змінних: · глобальні змінні – це змінні, визначені поза функціями, в описі яких відсутнє слово static. Описи глобальних змінних, що включають слово extern, виносяться в заголовні файли ( h-файли). Слово extern означає, що змінна описується, але не створюється в даній частині програми. Визначення глобальних змінних, тобто опис без слова extern, міститься у файлах реалізації (c-файли або cpp-файли). Приклад: глобальна змінна maxind описується двічі: o в h-файлі за допомогою рядка: extern int maxind;
цей опис повідомляє про наявність такий змінної, але не створює цю змінну! o в cpp-файлі за допомогою рядка: int maxind = 1000;
цей опис створює змінну maxind та встановлює її початкове значення 1000. Помітимо, що стандарт мови не вимагає обов'язкового присвоєння початкових значень глобальним змінним, але це краще робити завжди, інакше в змінній буде знаходитися непередбачене значення (сміття, як говорять програмісти). Ініціалізація всіх глобальних змінних при їхньому визначенні – це правило гарного стилю. Глобальні змінні називаються так тому, що вони доступні в будь-якій частині програми, у всіх її файлах. Тому імена глобальних змінних повинні бути досить довгими, щоб уникнути випадкового збігу імен двох різних змінних. Наприклад, імена x або n для глобальної змінної не підходять; · статичні змінні – це змінні, в описі яких присутнє слово static. Як правило, статичні змінні описуються поза функціями. Такі статичні змінні у всьому подібні глобальними, з одним виключенням: область видимості статичної змінної обмежена одним файлом, усередині якого вона визначена – і, більше того, її можна використовувати тільки після її опису, тобто нижче по тексту. Із цієї причини описи статичних змінних виносяться на початок файлу. На відміну від глобальних змінних, статичні змінні ніколи не описуються в h-файлах (модифікатори extern і static конфліктують між собою).Порада: використовуйте статичні змінні, якщо потрібно, щоб вони були доступні тільки для функцій, описаних усередині того самого файлу. По можливості не застосовуйте в таких ситуаціях глобальні змінні, це дозволить уникнути конфліктів імен при реалізації великих проектів, що складаються із сотень файлів. o Статичну змінну можна описати й усередині функції, хоча звичайно так ніхто не робить. Змінна розміщається не в стеку, а в статичній пам'яті, тобто її не можна використовувати при рекурсії, а її значення зберігається між різними входами у функцію. Область видимості такий змінної обмежена тілом функції, у якій вона визначена. В іншому вона подібна статичній або глобальній змінній. Помітимо, що ключове слово static у мові Сі використовується для двох різних цілей: § як вказівка типу пам'яті: змінна розташовується в статичній пам'яті, а не в стеку; § як спосіб обмежити область видимості змінної рамками одного файлу (у випадку опису змінної поза функцією). Слово static може бути присутнім і в заголовку функції. При цьому воно використовується тільки для того, щоб обмежити область видимості ім'я функції рамками одного файлу. Приклад: static int gcd(int x, int y); // Прототип ф-ции. . .static int gcd(int x, int y) { // Реалізація . . .}
Порада: використовуйте модифікатор static у заголовку функції, якщо відомо, що функція буде викликатися лише усередині одного файлу. Слово static повинне бути присутнім як в описі прототипу функції, так і в заголовку функції при її реалізації. Локальні, або стекові, змінні – це змінні, описані усередині функції. Пам'ять для таких змінних виділяється в апаратному стеку. Пам'ять виділяється в момент входу у функцію або блок і звільняється в момент виходу з функції або блоку. При цьому захоплення та звільнення пам'яті відбуваються практично миттєво, тому що комп'ютер тільки змінює регістр, що містить адресу вершини стека. Локальні змінні можна використовувати при рекурсії, оскільки при повторному вході у функцію в стеку створюється новий набір локальних змінних, а попередній набір не руйнується. По цій же причині локальні змінні безпечні при використанні ниток у паралельному програмуванні. Програмісти називають таку властивість функції реентерабельністю, від англ. re-enter able – можливість повторного входу. Це дуже важлива якість із погляду надійності та безпеки програми! Програма, що працює зі статичними змінними, цією властивості не має, тому для захисту статичних змінних доводиться використовувати механізми синхронізації, а логіка програми різко ускладнюється. Завжди варто уникати використання глобальних та статичних змінних, якщо можна обійтися локальними. Недоліки локальних змінних є продовженням їхніх достоїнств. Локальні змінні створюються при входженні до функції, а зникають після виходу з неї, тому їх не можна використовувати як дані, що поділяються між декількома функціями. До того ж, розмір апаратного стека обмежений, стек може переповнитися (наприклад, при глибокій рекурсії), що призведе до катастрофічного завершення програми. Тому локальні змінні не повинні мати великого розміру. Зокрема, не можна використовувати великі масиви як локальні змінні. Крім статичної та стекової пам'яті, існує ще практично необмежений ресурс пам'яті, що називається динамічна, або купа (heap). Програма може захоплювати ділянки динамічної пам'яті потрібного розміру. Після використання раніше захоплена ділянка динамічної пам'яті її необхідно звільнити. Під динамічну пам'ять приділяється простір віртуальної пам'яті процесу між статичною пам'яттю та стеком. Стек розташовується в старших адресах віртуальної пам'яті та росте убік зменшення адрес. Програма та константні дані розміщаються в молодших адресах, вище розташовуються статичні змінні. Простір вище статичних змінних та нижче стека займає динамічна пам'ять. Структура динамічної пам'яті автоматично підтримується виконуючою системою мови C++. Динамічна пам'ять складається із захоплених і вільних сегментів, кожному з яких передує опис сегмента. При виконанні запиту на захоплення пам'яті виконуюча система робить пошук вільного сегмента достатнього розміру та захоплює в ньому відрізок необхідної довжини. При звільненні сегмента пам'яті він позначається як вільний, при необхідності декілька вільних сегментів, що ідуть підряд, поєднуються. У мові С++ для захоплення та звільнення динамічної пам'яті застосовуються оператори new та delete. Вони є частиною мови C++. Нехай T – деякий тип мови C++, p – покажчик на об'єкт типу T. Тоді для захоплення пам'яті розміром в один елемент типу T використовується оператор new: T *p;p = new T;
Наприклад, для захоплення восьми байтів під дійсне число типу double використовується фрагмент double *p;p = new double;
Оператор new зручний тим, що можна присвоїти початкове значення об'єкту, створеному в динамічній пам'яті (тобто виконати ініціалізацію об'єкта). Для цього початкове значення записується в круглих дужках після імені типу після слова new. Наприклад, у наведеному нижче рядку захоплюється пам'ять під дійсне число, якому присвоюється початкове значення 1.5: double *p = new double(1.5);
Цей фрагмент еквівалентний фрагменту: double *p = new double;*p = 1.5;
За допомогою оператора new можна захоплювати пам'ять під масив елементів заданого типу. Для цього у квадратних дужках вказується довжина захоплюваного масиву, що може представлятися будь-яким цілочисельним виразом. Наприклад, у наступному фрагменті в динамічній пам'яті створюється фрагмент для зберігання дійсної матриці розміру m*n: double *a;int m = 100, n = 101;a = new double[m * n];
Таку форму оператора new іноді називають векторною. Оператор delete звільняє пам'ять, захоплену раніше за допомогою оператора new, наприклад, double *p = new double(1.5); //Захоплення та ініціалізація. . .delete p; // Звільнення пам'яті
Якщо пам'ять під масив була захоплена за допомогою векторної форми оператора new, то для її звільнення необхідно використовувати векторну форму оператора delete, у якій після слова delete записуються порожні квадратні дужки: double *a = new double[100]; // Захоплюємо масив. . .delete[] a; // Звільняємо масив· Для масивів, що складаються з елементів базових типів Сі, при звільненні пам'яті можна використовувати звичайну форму оператора delete. Єдина відмінність векторної форми: при звільненні масиву елементів класу, у якому визначений деструктор, тобто завершальна дія перед знищенням об'єкта, цей деструктор викликається для кожного елемента знищуваного масиву. Оскільки для базових типів деструктори не визначені, векторна та звичайна форми оператора delete для них еквівалентні. Приємна особливість оператора delete полягає в тому, що при звільненні нульового покажчика нічого не відбувається. Наприклад, як видно, наступний фрагмент програми цілком коректний: double *a = 0; // Нульовий покажчикbool b;. . .if (b) { a = new double[1000]; . . .}. . .delete[] a;
Тут у покажчик a спочатку записується нульова адреса. Потім, якщо справедлива деяка умова, захоплюється пам'ять під масив. Таким чином, при виконанні оператора delete покажчик a містить або нульове значення, або адресу масиву. У першому випадку оператор delete нічого не робить, у другому звільняє пам'ять, зайняту масивом. Така технологія застосовується практично всіма програмістами на C++: завжди ініціалізувати покажчики на динамічну пам'ять нульовими значеннями і не мати ніяких проблем при звільненні пам'яті.
Поиск по сайту: |
 , i = 0, 1,..., n; крапки
, i = 0, 1,..., n; крапки  – це багаточлен ступеня n, що приймає нульові значення у всіх вузлах
– це багаточлен ступеня n, що приймає нульові значення у всіх вузлах 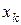 . В k-ом вузлі
. В k-ом вузлі 
 7 знайти максимальний елемент масиву та виконати сортування головної діагоналі за зменшенням значень її елементів.
7 знайти максимальний елемент масиву та виконати сортування головної діагоналі за зменшенням значень її елементів.