|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Применение вариационного исчисления ⇐ ПредыдущаяСтр 2 из 2
Хотя задачи, к которым применимо вариационное исчисление, заметно шире, в приложениях они главным образом сводятся к двум основным задачам: нахождение точек в пространстве функций, на котором определён функционал — точек стационарного функционала, стационарных функций, линий, траекторий, поверхностей и т. п., то есть нахождение для заданного Очевидно, обе задачи тесно связаны, и решение второй сводится (при должной гладкости функционала) к решению первой, а затем проверке, действительно ли достигается локальный экстремум (что делается независимо вручную, или — более систематически — исследованием вариационных производных второго и, если все они одного знака и хотя бы одна из них равна нулю, то и более высокого порядка). В описанном процессе выясняется и тип экстремума. Нередко (например, когда функция стационарного функционала единственная, а все изменения функционала при любом большом возмущении имеют один и тот же знак) решение вопроса, экстремум ли это и какого он типа, заранее очевидно. При этом очень часто задача (1) оказывается не менее или даже более важной, чем задача (2), даже когда классификация стационарной точки неопределённа (то есть она может оказаться минимумом, максимумом или седловой точкой, а также слабым экстремумом, точкой, вблизи которой функционал точно постоянен или отличается от постоянного в более высоком порядке, чем второй). Например, в механике (и вообще в физике) кривая или поверхность стационарной потенциальной энергии означает равновесие, а вопрос, является ли она экстремалью, связан лишь с вопросом об устойчивости этого равновесия (который далеко не всегда важен). Траектории стационарного действия отвечают возможному движению, независимо от того, минимально действие на такой траектории, максимально, или седловидно. То же можно сказать о геометрической оптике, где любая линия стационарного времени (а не только минимального, как в простой формулировке принципа наименьшего времени Ферма) соответствует возможному движению светового луча неоднородной оптической среде. Есть системы, где вообще нет экстремалей, но стационарные точки существуют.
22. Динамическое программирование
23. Теорема Байеса Теорема Байеса имеет дело с расчетом вероятности верности гипотезы в условиях, когда на основе наблюдений известна лишь некоторая частичная информация о событиях. Другими словами, по формуле Байеса можно более точно пересчитывать вероятность, беря в учет как ранее известную информацию, так и данные новых наблюдений. Главная, видимо, особенность теоремы Байеса в том, что для ее практического применения обычно требуется огромное количество вычислений-пересчетов, а потому расцвет методов байесовых оценок пришелся аккурат на революцию в компьютерных и сетевых инфотехнологиях. Пример, из 20 студентов, пришедших на экзамен, 8 подготовлены отлично, 6 - хорошо, 4 - посредственно и 2 - плохо. Гипотезы прихода на экзамен отличника (8/20), хорошиста (6/20), троечника (4/20), двоечника (2/20).
24. Метод парных сравнений Метод предусматривает использование эксперта, который проводит оценку целей. Z1, Z2, ...,Zn. Согласно методу осуществляются парные сравнения целей во всех возможных сочетаниях. В каждой паре выделяется наиболее предпочтительная цель. И это предпочтение выражается с помощью оценки по какой-либо шкале. Обработка матрицы оценок позволяет найти веса целей, характеризующие их относительную важность. Одна из возможных модификаций метода состоит в следующем: составляется матрица бинарных предпочтений, в которой предпочтение целей выражается с помощью булевых переменных; определяется цена каждой цели путем суммирования булевых переменных по соответствующей строке матрицы. Примеp1: эксперт проводит оценку 4-х целей, которые связаны с решением транспортной проблемы. Z1 — построить метрополитен Z2 — приобрести 2-хэтажный автобус Z3 — расширить транспортную сеть Z4 — ввести скоростной трамвай Составим матрицу бинарных предпочтений:
Определим цену каждой цели (складываем по строкам) C1=3; C2=0; C3=2; C4=1 Эти числа уже характеризуют важность объектов. Нормируем, т.к. этими числами не удобно пользоваться. Исковые веса целей. V1=3/6=0,5 ; V2=0; V3=0,17 Проверка: Получаем следовательно порядок предпочтения целей: Z1, Z3, Z4, Z2 Примеp2: cумма всех Vi=1, значит решено верно. Белорусские авиалинии «Белавиа» получили возможность приобрести самолет Боинг 747 — встал вопрос об открытии нового чартерного рейса. Были предложены направления: Лондон Пекин Сеул Владивосток Тель-Авив
Где Z1...j — направления Определить наиболее выгодный рейс. Решение: void main(void) { //Введем исходную матрицу бинарных предпочтений for(i=1;i<5;i++) Predpochtenia[0][i]=1; Predpochtenia[1][0]=0; for(i=2;i<5;i++) Predpochtenia[1][i]=0; Predpochtenia[2][0]=0; Predpochtenia[2][1]=1; ...... //Определим цену каждой цели int c[5]; for(i=0;i<5;i++) c[i]=0; for(i=0;i<5;i++) { for(j=0;j<5;j++) { if(i!=j) { c[i]+=Predpochtenia[i][j]; } } } //Определяем веса целей int sum=0; for(i=0;i<5;i++) { sum+=c[i]; } double v[5][2]; for(i=0;i<5;i++) { v[i][0]=double(c[i])/double(sum); v[i][1]=i+1; } //Далее надо отсортировать цели по возрастанию for(i=0;i<5;i++) { for(j=1;j<5;j++) if(v[i][0] < v[j][0] && i ........ } } Результат: 0,4 0 0,3 0,2 0,1 1 3 4 5 2 Вывод: Наиболее выгодный рейс — рейс номер 1, т.к. искомый вес целей самый большой: 0,4.
25. Многоцелевые модели принятия решений. Метод анализа иерархий. Многоцелевые модели. В этих моделях каждая альтернатива оценивается множеством критериев, поэтому они называются также многокритериальными. К наиболее известным многокритериальным моделям относятся многомерные функции полезности, модели многомерного шкалирования, метод анализа иерархий (метод собственных значений). Из многомерных моделей наиболее часто используются аддитивные и мультипликативные многомерные функции полезности. Функцией полезности (ценности) называется скалярная функция U, устанавливающая отношение порядка на множестве вариантов U( где
где Обобщенная форма мультипликативной функции полезности имеет вид
Оценки оказываются эквивалентными (могут быть преобразованы друг в друга). Многомерные модели сравнения вариантов различаются подходами к установлению весов факторов и подфакторов и схемами их агрегирования. Стандартная процедура сравнения вариантов по многим факторам включает формулирование задачи, выбор факторов и подфакторов, построение дерева решений, назначение весов факторам и их нормализацию, назначение весов подфакторам и нормализацию весов, подсчет показателей (баллов) по всем факторам для каждого варианта, получение взвешенных оценок и суммарного числового выражения полезности для каждого варианта решения. Основные неформальные шаги в этом алгоритме – выбор факторов и подфакторов, построение дерева решений и назначение весов факторам и подфакторам. Метод Анализа Иерархий (МАИ) — математический инструмент системного подхода к сложным проблемам принятия решений. МАИ не предписывает лицу, принимающему решение (ЛПР), какого-либо «правильного» решения, а позволяет ему в интерактивном режиме найти такой вариант (альтернативу), который наилучшим образом согласуется с его пониманием сути проблемы и требованиями к ее решению. Этот метод разработан американским математиком Томасом Саати, который написал о нем книги, разработал программные продукты и в течение 20 лет проводит симпозиумы ISAHP (англ. International Symposium on Analytic Hierarchy Process). МАИ широко используется на практике и активно развивается учеными всего мира. В его основе наряду сматематикой заложены и психологические аспекты. МАИ позволяет понятным и рациональным образом структурировать сложную проблему принятия решений в виде иерархии, сравнить и выполнить количественную оценку альтернативных вариантов решения. Метод Анализа Иерархий используется во всем мире для принятия решений в разнообразных ситуациях: от управления на межгосударственном уровне до решения отраслевых и частных проблем в бизнесе, промышленности, здравоохранении и образовании. Для компьютерной поддержки МАИ существуют программные продукты, разработанные различными компаниями. Анализ проблемы принятия решений в МАИ начинается с построения иерархической структуры, которая включает цель, критерии, альтернативы и другие рассматриваемые факторы, влияющие на выбор. Эта структура отражает понимание проблемы лицом, принимающим решение. Каждый элемент иерархии может представлять различные аспекты решаемой задачи, причем во внимание могут быть приняты как материальные, так и нематериальные факторы, измеряемые количественные параметры и качественные характеристики, объективные данные и субъективные экспертные оценки [1]. Иными словами, анализ ситуации выбора решения в МАИ напоминает процедуры и методы аргументации, которые используются на интуитивном уровне. Следующим этапом анализа является определение приоритетов, представляющих относительную важность или предпочтительность элементов построенной иерархической структуры, с помощью процедуры парных сравнений. Безразмерные приоритеты позволяют обоснованно сравнивать разнородные факторы, что является отличительной особенностью МАИ. На заключительном этапе анализа выполняется синтез (линейная свертка) приоритетов на иерархии, в результате которой вычисляются приоритеты альтернативных решений относительно главной цели. Лучшей считается альтернатива с максимальным значением приоритета. Метод анализа иерархий содержит процедуру синтеза приоритетов, вычисляемых на основе субъективных суждений экспертов. Число суждений может измеряться дюжинами или даже сотнями. Математические вычисления для задач небольшой размерности можно выполнить вручную или с помощью калькулятора, однако гораздо удобнее использовать программное обеспечение (ПО) для ввода и обработки суждений. Самый простой способ компьютерной поддержки — электронные таблицы, самое развитое ПО предусматривает применение специальных устройств для ввода суждений участниками процесса коллективного выбора. Порядок применения Метода Анализа Иерархий: · Построение качественной модели проблемы в виде иерархии, включающей цель, альтернативные варианты достижения цели и критерии для оценки качества альтернатив. · Определение приоритетов всех элементов иерархии с использованием метода парных сравнений. · Синтез глобальных приоритетов альтернатив путем линейной свертки приоритетов элементов на иерархии. · Проверка суждений на согласованность. · Принятие решения на основе полученных результатов.
J = (#Jf#)/(#S#), где #Jf# – число разнотипных по функциям систем; #S# – общее число подсистем.
26. Принятие решений методом «Дерево решений» Деревья решений – это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Область применения деревья решений в настоящее время широка, но все задачи, решаемые этим аппаратом могут быть объединены в следующие три класса: · Описание данных: Деревья решений позволяют хранить информацию о данных в компактной форме, вместо них мы можем хранить дерево решений, которое содержит точное описание объектов.
· Классификация: Деревья решений отлично справляются с задачами классификации, т.е. отнесения объектов к одному из заранее известных классов. Целевая переменная должна иметь дискретные значения.
· Регрессия: Если целевая переменная имеет непрерывные значения, деревья решений позволяют установить зависимость целевой переменной от независимых(входных) переменных. Например, к этому классу относятся задачи численного прогнозирования(предсказания значений целевой переменной).
Другое определение: деревья решений - это способ представления правил в иерархической, последовательной структуре, где каждому объекту соответствует единственный узел, дающий решение. Деревья решений разбивают данные на группы на основе значений переменных, в результате чего возникает иерархия операторов "ЕСЛИ - ТО", которые классифицируют данные. Под правилом понимается логическая конструкция вида «если - то». · Объект – некоторый пример, действие, шаблон, наблюдение. · Атрибут – признак, свойство. · Узел – внутренний узел дерева, узел проверки. · Лист – конечный узел дерева, узел решения. 2 Построение деревьев Способ 1. Рисуют деревья слева направо. Места, где принимаются решения, обозначают квадратами, места появления исходов – кругами, возможные решения – пунктирными линиями, возможные исходы – сплошными линиями. Для каждой альтернативы мы считаем ожидаемую стоимостную оценку (EMV) – максимальную из сумм оценок выигрышей, умноженных на вероятность реализации выигрышей, для всех возможных вариантов (см. пример 1). Пример 1. Компания рассматривает вопрос о строительстве завода. Возможны три варианта действий: а). Построить большой завод стоимостью Ст1 = 500 тысяч у.е. При этом варианте возможны большой спрос (годовой доход в размере Д1 = 200 тысяч у.е. в течение следующих 5 лет) с вероятностью p1 = 0,7 и низкий спрос (ежегодные убытки Д2 = 90 тысяч у.е.) с вероятностью р2 = 0,3. б). Построить маленький завод стоимостью Ст2 = 300 тысяч у.е. При этом варианте возможны большой спрос (годовой доход в размере Д3 = 100 тысяч у.е. в течение следующих 5 лет) с вероятностью p3 = 0,7 и низкий спрос (ежегодные убытки Д4 = 40 тысяч у.е.) с вероятностью р4 = 0,3. в). Отложить строительство завода на один год для сбора дополнительной информации, которая может быть позитивной или негативной с вероятностью p5 = 0,4 и p6 = 0,6 соответственно. В случае позитивной информации можно построить заводы по указанным выше расценкам, а вероятности большого и низкого спроса меняются на p7 = 0,8 и р8 = 0,2 соответственно. Доходы на последующие четыре года остаются прежними. В случае негативной информации компания заводы строить не будет. Нарисовав дерево решений, определим наиболее эффективную последовательность действий, основываясь на ожидаемых доходах. Решение. Строим дерево решений. Строим узел 1, из которого исходят три заявленные в условии варианты. Обозначаем эти ветви пунктиром, поскольку это – возможные решения. На концах ветвей ставим узлы-исходы, заключаем их в круг и обозначаем буквами А, В и т.д. Рисуем из этих узлов-исходов ветви с возможными исходами при выборе того или иного варианта из условия. Под каждой ветвью подписываем вероятности соответствующих исходов. На концах каждой ветви, не закрытой новым узлом, выставляем доходы и убытки, умноженные (исходя из условия) на время (годы из условия). На ветвях (возможные решения) ставим стоимость строительства со знаком «-», так как это расходы компании. Убытки на концах «открытых» ветвей также пишем со знаком «-». Рис.1 – Дерево решений для примера 1. Первый этап построения Далее считаем ожидаемые стоимостные оценки узлов. Ожидаемая стоимостная оценка узла А равна: ЕМV(А) = 0,8 х 1000 + 0,2 х (-450) -500 = 210. EMV( B) = 0,8 х 500 + 0,2 х (-200) - 300 = 60. EMV( D) = 0,9 x 800 + 0,1 x (-360) - 500 = 184. EMV(E) = 0,9 x 400 + 0,1 х (-160) - 300 = 44. Для узлов принятия решения 2 (второй уровень, условно) выбираем максимальную оценку: EMV(2) = max {EMV( D), EMV( E)} = max {184, 44} = 184 = EMV(D). Поэтому в узле 2 отбрасываем возможное решение «маленький завод». EMV(C) = 0,7 x 184 + 0,3 x 0 = 128,8. Для узла принятия решения 1 – узла принятия окончательного решения, аналогично выбираем максимальную оценку на других узлах. EMV(1) = max {ЕМV(A), EMV(B), EMV(C)} = max {210; 60; 128,8} = 210 = EMV(А). Поэтому в узле 1 выбираем решение «большой завод». Исследование проводить не нужно. Строим большой завод. Ожидаемая стоимостная оценка этого наилучшего решения равна 210 тысяч у.е. Ответ: наиболее подходящее решение – решение строить большой завод. Рис.2 – Дерево решений со стоимостными оценками В рассмотренном примере мы произвели отсечение ветвей в узле 2. И далее в задаче мы отсекаем те ветви и узлы, стоимостные оценки которых не приемлемы для принятия наиболее выгодного решения.
Поиск по сайту: |
 таких
таких  , для которых
, для которых  при любом (бесконечно малом)
при любом (бесконечно малом)  , или, иначе, где
, или, иначе, где  , нахождение локальных экстремумов функционала, то есть в первую очередь определение тех
, нахождение локальных экстремумов функционала, то есть в первую очередь определение тех  ,
,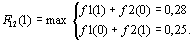

 ,...,
,...,  )
)  (
(  ,...,
,...,  )
)  (
(  )
)  (
( 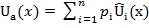 , (5.2.6)
, (5.2.6) – функция полезности варианта x;
– функция полезности варианта x;  – вес фактора (критерия)
– вес фактора (критерия)  ;
;  – оценка полезности варианта x по критерию
– оценка полезности варианта x по критерию  .
. . (5.2.7)
. (5.2.7)