|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Сущность теории непараметрической статистикиСтр 1 из 2Следующая ⇒
1 Краткая история возникновения корреляционного анализа
Начало применения математико-статистических приемов для изучения корреляционных зависимостей относится к 70 годам девятнадцатого столетия. Многие историки – статистики историю развития корреляции ведут от сороковых годов девятнадцатого столетия – от того времени, когда французский математик О. Браве предложил формулу для распределения двух случайных величин, удовлетворяющих требованиям закона нормального распределения. Однако истинным основателем корреляционной теории считается английский математик – статистик К. Пирсон, создавший в конце девятнадцатого начале двадцатого веков данную теорию. В ней корреляция выступает как форма диалектической связи, при которой действует множество различных причин, как необходимых, так и случайных, как общих для обеих корреляционных величин, так и частных, влияющих только на одну из них. Причем, не все закономерные связи – причинные. Развитие теории осуществлялось с помощью других исследований, когда основные положения теории корреляции были уже созданы. Причем в области изучения корреляций практика резко расходилась с теорией, ставя исследователей в такие условия, которые не удовлетворяли ее требованиям. Основой формирования способов изучения корреляций и регрессий были данные, характеризующие какие-либо, количественно выраженные признаки. Поэтому исследователи на первых же шагах встретились с задачей корреляции качественных признаков, например, связь между цветом глаз у отцов и сыновей. Общий принцип, который был положен в основу конструкции показателей корреляции качественных признаков, заключался в том, что два качественных признака можно считать взаимосвязанными, если действие одного из них А при действии признака Б таково же, как и при действии признака не Б. В развитие этого принципа, и предлагались различные конструкции таких показателей, как, например, коэффициент средней квадратичной сопряженности Пирсона или коэффициент взаимной сопряженности Чупрова. Изучение корреляции качественных признаков породило в общем учении о корреляции так называемую теорию рангов и основанную на ней теорию ранговой корреляции. Английский математик-статистик М. Кендалл, автор монографии, посвященной проблемам ранговой корреляции, указывал, что теория рангов впервые возникла как ответвление теории случайных процессов. На начальной стадии в рангах чаще всего видели просто удобный аппарат, благодаря которому удается обойтись без измерения абсолютной величины переменных и тем самым сэкономить время и усилия. Позднее статистика рангов смогла завоевать признание благодаря своим собственным достоинствам. Кендалл сконструировал показатель, который применим и для изучения частной корреляции между рангами. Современную теорию ранговой корреляции невозможно представить без наиболее полно ее освещающих исследований М. Кендалла. Таким образом, уже к началу двадцатого столетия математико-статистические методы измерения корреляций и регрессий сложились в общем в достаточно стройную целостную систему, включающую в себя методы непараметрической статистики и непараметрические ранговые методы.
2 Непараметрические ранговые методы
Непараметрические ранговые методы – это бурно развивающаяся область математической статистики. История современных непараметрических методов, основанных на рангах, довольно коротка – всего лишь около 40 лет. Ранговые методы выделились в особое направление непараметрической статистики не только вследствие природы исходного материала, но и по идеям его дальнейшего использования. Сегодня этими методами решаются многие задачи анализа экономических, статистических, инженерных, естественнонаучных, социологических, медицинских данных. Ранжирование – это процедура упорядочения объектов изучения, которая выполняется на основе предпочтения. Ранг – это порядковый номер значений признака, расположенных в порядке возрастания или убывания их величин. Как показали статистические исследования, проведенные за последние 10-15 лет, ранговые методы в значительной мере лишены ряда недостатков для работы с малыми выборками, распределение которых неизвестно. Как известно, переход от самих наблюдений к их рангам сопровождается определенной потерей информации. Однако, эти потери не слишком велики. К сожалению, в настоящее время все еще сказывается нехватка специальной литературы по данному вопросу. В последнее время в прогнозировании и при решении ряда других задач стали широко применяться экспертные оценки. Методы ранговой корреляции в этой области является едва ли не единственным путем обобщения экспертных оценок. Теория рангов впервые возникла как ответвление теории случайных процессов. На начальной стадии в рангах чаще всего видели просто удобный аппарат, благодаря которому удается обойтись без изменения абсолютной величины переменных и тем самым сэкономить время или усилия. Благодаря использованию рангов можно было избежать трудностей, связанных с построением объективной шкалы абсолютных значений. Позднее статистика рангов смогла завоевать признание благодаря своим собственным достоинствам. Ниже будут рассмотрены наиболее распространенные способы упорядочения изучаемых объектов: - задача может сводиться просто к упорядочению объектов по месту, которое они занимают в пространстве или во времени. Например, карты были расположены в колоде в некотором порядке, а затем перетасованы. Новое расположение карт также характеризуется определенным порядком, ранжированием. Сравнив его со старым, можно увидеть, насколько тщательно были перетасованы карты. В этой задаче интересно только общее расположение карт в колоде, и нет необходимости упорядочить объекты в соответствии с “возрастанием” или “убыванием” того или иного присущего всем им признака; - упорядочить объекты можно и по некоторому качеству, для которого не существует объективной абсолютной шкалы изменения. Можно, например, ранжировать образцы горных пород по твердости, исходя из следующего простого критерия: А тверже Б, если А оставляет царапину на Б, когда они соприкасаются. Если А оставляет царапину на Б, а Б – на В, то А будет оставлять царапину на В. Таким образом, прибегнув к ряду сопоставлений, можно с достаточной точностью упорядочить рассматриваемые объекты (если только набор не включает такие два объекта, которые обладают одинаковой твердостью). Однако подобный способ не позволяет измерить абсолютную величину твердости горных пород. Всегда можно установить, что А тверже Б. Однако до тех пор, пока не построена та или иная шкала измерения абсолютных величин, нельзя утверждать, что А, скажем, вдвое тверже Б; - упорядочение может проводиться в соответствии с измеряемой (или теоретически исчисляемой) величиной некоторого признака. Например, можно располагать людей в том или ином порядке в зависимости от их роста, а города по численности населения. При этом не всегда требуется прибегать к самому процессу измерения: можно «на глаз» построить группу студентов по росту; однако в таких случаях критерий, по которому происходит ранжирование, должен допускать возможность непосредственных сопоставлений. Можно упорядочить объекты по некоторому признаку, величину которого, в принципе, можно измерить, но на практике (или даже теоретически) не удается прибегнуть к такому измерению в силу тех или иных причин. Например, можно упорядочить ряд лиц по их интеллектуальным способностям, полагая, что такое качество действительно существует и что можно разместить людей в том или ином порядке в соответствии с интенсивностью этого признака. В практических приложениях методов, основанных на ранжировании, иногда сталкиваются со случаями, когда два или несколько объектов настолько подобны, что не удается отдать предпочтение одному из них. Когда эксперт ранжирует объект на основе субъективных суждений, то это свойство (отсутствие предпочтений) связано с истиной их неразличимостью или неспособностью исследователя найти существенные различия. В этом случае говорят, что такой объект называется связанным. Например, студентов расположили в соответствии с их достоинствами или экзаменационными баллами. Метод, который принимается для предписания числовых значений рангов связанных объектов, заключается в усреднении рангов, которые они имели бы, если были различимы. Например, если связывают третий и четвертый объекты, то каждому приписывают ранг, равный 3,5, если же связывают объекты от второго до седьмого, то получаемый ранг равен 4,5. Иногда такой подход называется “методом средних рангов”. Когда нет основания для выбора между объектами, то ясно, что в этом случае нужно приписать всем одинаковые ранги. Преимуществом данного метода является то, что сумма рангов для всех объектов остается точно такой же как и при ранжировании без связей. В анализе социально – экономических явлений часто приходится прибегать к различным, условным оценкам с помощью рангов, а взаимосвязь между отдельными признаками измерять с помощью непараметрических коэффициентов связи.
3 Коэффициент конкордации рангов Кендалла
Для определения тесноты связи между произвольным числом ранжированных признаков применяется множественный коэффициент корреляции (коэффициент конкордации). В практике статистических исследований встречаются случаи, когда совокупность объектов характеризуется не двумя, а несколькими последовательностями рангов, необходимо установить статистическую связь между несколькими переменными. В качестве такого измерителя используют множественный коэффициент корреляции (коэффициент конкордации) рангов Кендалла, определяемой по следующей формуле:
где W – коэффициент конкордации; D – сумма квадратов рангов рассчитывается по формуле (2); n – число объектов ранжируемого признака (число экспертов); m – число анализируемых порядковых переменных. В некотором смысле W служит мерой общности.
где rij – расставленные ранги суждений группы экспертов; n – число объектов(число экспертов). Значения коэффициентов конкордации заключены на отрезке [0;1]. Увеличение коэффициента от 0 к 1 означает проявление большей согласованности суждений. Если все эти суждения совпадают, то W=1.
Поиск по сайту: |
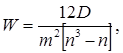 (1)
(1)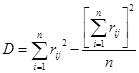 , (2)
, (2) Проверка значимости коэффициента основана на том, что в случае справедливости нулевой гипотезы об отсутствии корреляционной связи при n>7 статистика m(n-1)* W имеет приближенно
Проверка значимости коэффициента основана на том, что в случае справедливости нулевой гипотезы об отсутствии корреляционной связи при n>7 статистика m(n-1)* W имеет приближенно  – распределение с k=n-1 степенями свободы. Поэтому коэффициент конкордации значим на уровне
– распределение с k=n-1 степенями свободы. Поэтому коэффициент конкордации значим на уровне 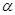 =0,05, если m(n-1)W>
=0,05, если m(n-1)W>