|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Алгоритм построения дерева Хаффмана
1. Символы входного алфавита образуют список свободных узлов. Каждый имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в ожидаемое сообщение. 2. Выбираются два свободных узла дерева с наименьшими весами. 3. Создаётся их родитель с весом, равным их суммарному весу. 4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка. 5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой – бит 0. 6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева. Например, у нас есть следующая таблица частот:
15 7 6 6 5 А Б В Г Д
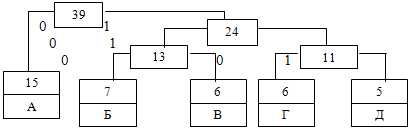
На первом шаге из листьев дерева выбираются два с наименьшими весами – Г и Д. Они присоединяются к новому узлу-родителю, вес которого устанавливается 5 + 6 = 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д – ветви 1. На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создаётся новый узел с весом 13, а узлы Б и В удаляются из списка свободных. После всего этого дерево кодирования выглядит так, как показано на рис. 1.
Рис. 1. Дерево кодирования Хаффмана после второго шага
На следующем шаге «наилегчайшей» парой оказываются узлы Б/В и Г/Д. Для них ещё раз создаётся родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д–ветви 1. На последнем шаге в списке свободных осталось только два узла – это узел А и узел Б (Б/В)/(Г/Д). В очередной раз создаётся родитель с весом 39 и бывшие свободными узлы присоединяются к разным его ветвям. Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается. Н-дерево представлено на рис. 2.
Каждый символ, входящий в сообщение, определяется как конкатенация нулей и единиц, сопоставленных рёбрам дерева Хаффмана, на пути от корня к соответствующему листу. Для данной таблицы символов коды Хаффмана будут выглядеть следующим образом:
А 0 Б 100 В 101 Г 110 Д 111
Наиболее частый символ сообщения А закодирован наименьшим количеством битов, а наиболее редкий символ Д – наибольшим. Стоимость хранения кодированного потока, определенная как сумма длин взвешенных путей, определится выражением: 15*1+7*3+6*3+6*3+5*3 =87, что существенно меньше стоимости хранения входного потока (312). Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока. Алгоритм декодирования предполагает просмотр потока битов и синхронное перемещение от корня вниз по дереву Хаффмана в соответствии со считанным значением до тех пор, пока не будет достигнут лист, то есть декодировано очередное кодовое слово, после чего распознавание следующего слова вновь начинается с вершины дерева. Классический алгоритм Хаффмана имеет один существенный недостаток. Для восстановления содержимого сжатого сообщения декодер должен знать модель кодирования, которой пользовался кодер. Следовательно, длина сжатого сообщения увеличивается на размер модели кодирования, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного – для построения модели сообщения (таблицы частот и дерева Хаффмана), другого – для собственно кодирования.
Детали реализации Главной проблемой статического алгоритма Хаффмана является запись в файл модели кодирования. В данной программе мы записываем модель кодирования таким образом: сначала идёт сам байт, а затем его количество появлений в исходном тексте(4 байта – стандартный тип int): итого 1 + 4 = 5 байт, т.е. в худшем случае – 256 * 5 = 1280 примерно 1 кб.
Поиск по сайту: |