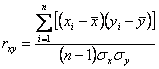К методам обработки количественных данных относятся статистические приемы подведения итогов исследования, выявления определенных связей между ними, проверки достоверности выдвинутой гипотезы. Математическая обработка результатов обеспечивает доказательность (репрезентативность) исследований. В сочетании с качественными показателями количественная обработка значительно повышает объективность психологического исследования. Достоверность выводов исследования не только определяется совершенством примененного математического аппарата, но также зависит от того, насколько адекватно величины, которыми мы оперируем, отражают реальные количественные характеристики изученных явлений и объектов. Несоблюдение этого требования превращает математическую обработку в пустое манипулирование формулами. Нахождение состоятельных количественных критериев для оценки тех или иных факторов и сторон обучения или воспитания не является математической проблемой. Это задача, которая решается психологическими исследованиями. Однако, чтобы ее решать, надо правильно измерять психологические явления, учитывая условия и границы применимости способов измерения. Измерение — это приписывание чисел объектам и событиям в соответствии с определенными правилами. Простейший способ приписывания числовых характеристик предметам и явлениям — их регистрация. Она заключается в том, что выделяют какой-нибудь признак и отмечают каждый случай, когда в наблюдении или эксперименте появляется предмет или явление с этим признаком. Так, например, при изучении мотивов учения на основе анкетного опроса определяют число студентов, выбравших тот или иной вариант ответа. Статистическая обработка результатов регистрирующего изучения позволяет сделать некоторые важные обобщения и выводы относительно всей совокупности изучаемых явлений в целом. Важная особенность регистрации состоит в том, что она позволяет применять количественное изучение даже там, где невозможно определить сами свойства изучаемых явлений, что очень часто встречается в психолого-педагогических исследованиях. Так, например, невозможно прямо измерить уровень знаний и умений студентов, развития тех или иных нравственных качеств, степень эффективности данного метода обучения и т.д. Но, регистрируя соответствующие события1 — ошибки, поступки, проявления и т.д., можно получать определенные количественные характеристики всех этих признаков, устанавливать их частотность, а значит, определять возможные закономерности их проявления. Для определения границы применимости регистрации нужно как можно точнее сформировать критерий, позволяющий однозначно отличить объект с регистрируемым признаком от объекта без него. Так, например, прежде чем количественно определить профессиональную направленность студентов, нужно дать ее четкую формулировку и определить критерии, которые должны быть научно обоснованы. Иначе трудно будет судить о репрезентативности выводов. Следующий способ количественной характеристики данных — операция упорядочения. Сущность ее заключается в том, что изучаемые явления распределяются в порядке возрастания или убывания величины определенного признака. Затем каждой группе объектов присваивается число, соответствующее месту этой группы в нарастающем или убывающем ряду. Это число, показывающее порядок изучаемого признака у данных объектов, называется их рангом. После упорядочения данных часто осуществляют их группировку. Для этого определенный интервал значений изучаемого признака принимается за единицу меры. Значение признака в исследуемых явлениях будет определяться числом, показывающим, сколько раз данная единица меры укладывается в наблюдаемой величине. Условия, налагаемые на «интервальное» измерение, значительно строже, чем при регистрации или упорядочении: • наличие объективного эталона величины признака, принятого за единицу меры; • возможность прямо или косвенно сопоставлять любое измеряемое явление с этим эталоном; • неизменность измеряемых признаков в течение нужного периода времени. Выполнение этих трех условий не всегда удается в психологических исследованиях, отсюда трудности измерений и сложности применения аппарата математики. Полученные в результате измерения количественные характеристики обрабатываются методами математической статистики, позволяющими обобщить эмпирические результаты, объяснить причины «случайного» результата, дать ему определенное вероятностное толкование. Наиболее распространенными методами обработки количественных данных в прикладной психологии являются дисперсионный, корреляционный и факторный анализ. Дисперсионный анализ (от лат. dispersio — рассеивание) — статистический метод, позволяющий анализировать влияние различных факторов (признаков) на исследуемую (зависимую) переменную. Суть дисперсионного анализа заключается в разложении (дисперсии) измеряемого признака на независимые слагаемые, каждое из которых характеризует влияние того или иного фактора или их взаимодействия. Последующее сравнение таких слагаемых позволяет оценить значимость каждого изучаемого фактора, а также их комбинации. При этом особую роль играет анализ средних значений (отклонение от которых и называют дисперсией). При осуществлении дисперсионного анализа результаты наблюдений группируются с учетом градаций каждого учитываемого фактора (возраста, уровня образования, отдельных психологических особенностей и т.д.). Если учитываемый фактор оказывает влияние на признак, средние результирующего признака изменяются в соответствии с градациями фактора. Внутри каждой такой группы обнаруживается своя дисперсия, связанная с действиями других факторов. Суммарная дисперсия может быть выражена уравнением: Dy = Dx + D'z Где Dy — сумма квадратов отклонений отдельных вариант (xi) всего комплекса наблюдений от общей средней ( ), или ;Dх — сумма квадратов отклонений в комплексах (группах) частного среднего (xi) от общей средней, умноженная на число вариант в группах, или ; Dz — сумма из сумм квадратов отклонений отдельных вариант от их групповых средних, или Дисперсионный анализ допускает статистическое исследование признаков, выраженных не только в абсолютных количественных единицах, но и в относительных или условных баллах и индексах. Корреляционный анализ (от лат. соггеlatio — соотношение) — статистический метод оценки формы, знака и тесноты связи исследуемых признаков или факторов. При определении формы связи рассматривается ее линейность или нелинейность (т.е. как в среднем изменяется у в зависимости от изменения х, a X — ОТ У ). Одним из основных принципов определения количественных критериев корреляционной связи — коэффициентов корреляции — является сравнение величин отклонений от среднего значения по каждой группе в сопряженных парах сравниваемых рядов переменных. С целью достижения независимости меры корреляционной связи от числа сравниваемых пар и величин стандартных отклонений в двух группах произведение отклонений делится на число сравниваемых пар и стандартные отклонения в сопоставимых рядах. Такая мера носит название коэффициента корреляции — произведения моментов Пирсона: где хi и уi — сравниваемые количественные признаки, n — число сравниваемых наблюдений;бx и бy — стандартные отклонения в сопоставимых рядах. Расчетная формула rxy имеет следующий вид: Коэффициент корреляции — математический показатель силы связи между двумя сопоставляемыми статистическими признаками. Величина коэффициента колеблется в пределах от — 1 до +1. Смысл крайних значений коэффициента состоит в следующем: • коэффициент равен + 1, значит, связь между признаками однозначна по типу прямо пропорциональной зависимости; • коэффициент корреляции равен — 1, следовательно, связь также является функциональной, но по типу обратной пропорциональности; ш нулевая величина коэффициента свидетельствует об отсутствии связи между признаками. Статистическую значимость коэффициента корреляции определяют по таблицам. Факторный анализ (от лат. factor —действующий, производящий и греч. аnalysis — разложение, расчленение) — метод многомерной математической статистики, применяемый при исследовании статистически связанных признаков с целью выявления определенного числа скрытых от непосредственного наблюдения факторов. С помощью факторного анализа не просто устанавливается связь изменения одной переменной с изменением другой переменной, а определяется мера этой связи и обнаруживаются основные факторы, лежащие в основе указанных изменений. Факторный анализ особенно продуктивен на начальных этапах научных исследований, когда необходимо выделить какие-либо предварительные закономерности в исследуемой области. Поэтому факторный анализ представляет собой не только метод статистической обработки исходных данных для их обобщения, но и широкий научный метод подтверждения гипотез относительно природы процессов, присущих самому измеряемому свойству. Одной из наглядных моделей факторного анализа может служить схема, приведенная на рис.5. Области признаков (психологических особенностей, свойств, способностей и т.д.), измеряемых тестами А,В,С, представлены в виде прямоугольников. В зоне 1 находятся общие признаки для тестов Л и Б, в зоне 2 — для тестов В и С, а в зоне 3 — признаки, влияющие на успешность выполнения тестов А и С. В зоне 4 присутствуют признаки, объединенные общим для совокупности трех тестов фактором. Относительная площадь зон иллюстрирует факторный вес — меру выражения выявленной латентной переменной (признака) в результатах того или иного теста, т.е. представленность в результатах теста данных выделенного универсального фактора ХАвс
 ), или
), или  ;Dх — сумма квадратов отклонений в комплексах (группах) частного среднего (xi) от общей средней, умноженная на число вариант в группах, или
;Dх — сумма квадратов отклонений в комплексах (группах) частного среднего (xi) от общей средней, умноженная на число вариант в группах, или  ; Dz — сумма из сумм квадратов отклонений отдельных вариант от их групповых средних, или
; Dz — сумма из сумм квадратов отклонений отдельных вариант от их групповых средних, или