|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Особенности работы с Интернет-ресурсами
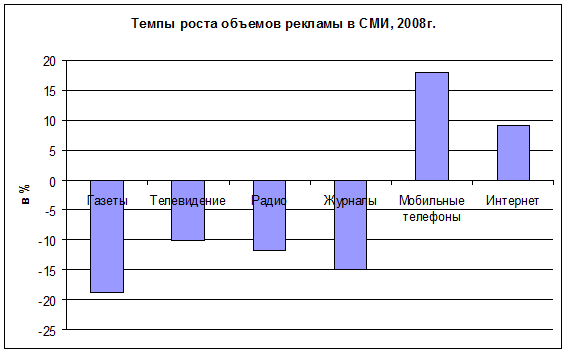
Глобальная сеть Интернет обладает огромным потенциалом, который специалисты компании Google оценивают в 1 трлн веб-страниц. Структура Интернета такова, что пользователь может воспользоваться веб-ресурсами, адрес которых ему известен, или поисковыми системами для поиска неизвестных ему веб-сайтов. По сути, единственным средством доступа к деловым ресурсам Интернета являются поисковые системы. Задача эффективной работы с ресурсами Интернета во многом определяется эффективностью поиска информации. Поиском информации в Интернете занимаются поисковые машины и каталоги. Задача поисковых систем – опознать веб-страницы с помощью поиска по ключевым словам в базе данных, которая состоит из индексов и ссылок на веб-страницы. Каталоги представляют собой иерархически организованную тематическую структуру, в которую в отличие от поисковых машин информация заносится по инициативе пользователей. Добавляемая страница должна быть жестко привязана к принятым в каталоге категориям. Каталоги не столь популярны у пользователей, как поисковые машины поскольку представленный объем информации в несколько десятков тысяч раз меньше, а также из-за трудностей в навигации по разделам. Практически каждый из 700 каталогов, представленных в Интернете, предлагает собственное видение структуры разделов и рубрик. Неоспоримым преимуществом каталогов перед поисковыми машинами является более высокая эффективность результатов поиска, поскольку веб-сайты выбираются из соответствующих разделов. Поисковые системы состоят из трех основных частей: 1. Спайдеры (Spider, Crawler, Robot) – программа, которая систематически посещает веб-сайты, считывает и индексирует полностью или частично их содержимое и далее следует по ссылкам, найденным на сайте. 2. Поисковая база данных (так называемый индекс) представляет собой гигантское хранилище информации – индексов, ссылок на веб-страницы и другой разнообразной информации. 3. Поисковая программа, которая в соответствии с запросом пользователя перебирает индексы в поисках соответствующей информации и выдает результаты поиска в виде ранжированного списка найденных веб-документов. Место в списке определяется тем, насколько полно тот или иной документ отвечает критериям, указанным в запросе пользователя. В каждой поисковой системе работает собственный спайдер; каждая система индексирует страницы своим особым способом, и приоритеты при поиске по индексам тоже различны. Поэтому запрос по ключевым словам или выражениям в разных поисковых системах обычно дает разные результаты. Программа поиска отыскивает страницы, которые соответствуют формальным требованиям запроса. Для того чтобы определить последовательность, в которой отобранные страницы будут представлены пользователю, применяется, как правило, уникальный для каждой поисковой системы алгоритм ранжирования. В интересах пользователя документы, наиболее соответствующие потребностям пользователя, должны быть помещены первыми в списке. Различные поисковые системы используют свои алгоритмы ранжирования. Основными принципами определения соответствия документов запросу являются следующие: · количество слов запроса в текстовом содержимом документа; · местоположение искомых слов в документе; · удельный вес ключевых слов в общем количестве слов документа; · дата – как долго страница находится в базе поискового сервера; · индекс цитируемости – как много ссылок на данную страницу ведет с других страниц, зарегистрированных в базе поисковика. Поисковые машины оказывают услуги пользователям бесплатно. Между тем поиск информации в Интернет является большим бизнесом, в котором участвует около 2000 поисковиков, поскольку проблема поиска актуальна не столько для пользователей, сколько для создателей веб-сайтов, заинтересованных в привлечении внимания пользователей Интернета. Для огромного количества интернет-магазинов, веб-сайтов других коммерческих компаний поисковые машины становятся практически единственным инструментом привлечения пользователей. Таким образом, поиск информации в Интернете становится эффективным инструментом рекламы по привлечению новых клиентов. Динамика темпов роста рынка рекламы по средствам массовой информации отображена на рис 5.3.
Рис. 3 Темпы роста рынка рекламы в СМИ, 2008г. Источник: Radio/Magazines/TVs: “Grown up digital” by Don Tapscott, 2009, McGraw-Hill. p. 30. Российский рынок интернет-рекламы в 2008 г. вырос на 55%, до 14,7 млрд руб., в том числе: сегмент контекстной рекламы (тематические ссылки в результатах поиска и на профильных ресурсах) вырос на 61% до 8,9 млрд руб.; сегмент медийной рекламы (баннеры, «всплывающие окна» и другие форматы) за год вырос на 45%, до 5,8 млрд руб[6]. На мировой арене поиска лидирующую позицию занимает компания Google, основанная в 1998 г., штат сотрудников составляет более 10 тыс., предлагает около 160 бесплатных сервисов на 114 языках мира. Другими крупными игроками являются компании Yahoo! и Microsoft. Поисковые машины должны находить компромисс между удовлетворением результатами поиска пользователей и рекламодателей. Однако говорить об эффективном поиске в Интернете невозможно. Эффективность работы поисковых машин ограничивается тремя существенными факторами: 1. Топология Интернета такова, что поисковые машины могут просматривать не больше 1/3 всех сайтов в Интернете. В 2000 г. специалисты компаний AltaVista, IBM и Compaq исследовали ресурсы и ссылки во Всемирной Паутине[7]. Просмотрев с помощью поисковых средств AltaVista свыше 600 млн веб-страниц и 1,5 млрд ссылок, размещенных на этих страницах, они пришли к выводу что исследуемое пространство состоит из следующих компонентов: · центральное ядро – это тесно связанные между собой веб-страницы, с каждой из которых можно попасть на любую другую (27%); · отправные страницы, в которых могут быть ссылки, ведущие к ядру, но из ядра к отправным страницам попасть нельзя (22%); · конечные веб-страницы, к которым можно прийти по ссылкам из ядра, но к ядру из них попасть нельзя (22%); · полностью изолированные от центрального ядра страницы (22%); · веб-страницы, не пересекающиеся с остальными ресурсами Интернета (7%). Исследования показали, что при увеличении общего объема информационных ресурсов Интернета, установленные отношения компонентов остаются прежними. Проведенный анализ позволяет сделать вывод о том, что информационное пространство Интернета является достаточно сложным и неоднородным. К отдельным ресурсам Интернета поисковые машины не имеют доступа. Для индексирования поисковым машинам доступны веб-страницы, составляющие центральное ядро, т.е. не более 30% всех веб-страниц. 2. «Глубинный Интернет» (скрытый или невидимый). В нем находятся базы данных информационных агентств, доступ к которым осуществляется на условиях подписки, т.е. оплаты, а также веб-ресурсы, доступ к которым осуществляется на условиях регистрации. Специалисты по поиску информации считают, что глубинный Интернет более чем в 500 раз превышает число документов, относящихся к «видимой» части. Таким образом, в доступной поисковым системам части Интернета содержится не более 0,5% информационных ресурсов, представленных в Интернете. 3. Поиск информации в Интернете, как правило, проводится по ключевым словам, поскольку информация, хранящаяся в Интернету, разрозненна и неструктурированна. В связи с тем, что в средствах поиска в Интернет не используются информационно-поисковые языки, на которых должны были бы описаны исходные документы и запросы, полнота поиска в Интернете с учетом описанных выше поисковых средств будет значительно ниже, чем в документальных системах, построенных на базе информационно-поисковых языков. Первые полнотекстовые информационно-поисковые системы (Full Retrieval System) появились в 1960-х гг.. Назначением этих систем был поиск в библиотечных каталогах, архивах, массивах документов, таких как статьи, нормативные акты, рефераты, диссертации, монографии. Первоначально информационно-поисковые системы применялись преимущественно в библиотечном деле и в системах научно-технической информации. В начале 1970-х гг. уже коммерческие компьютерные службы начали предоставлять возможность интерактивного поиска в тематических базах данных. Некоторые из тех служб существуют и сегодня – основанная в 1965 г. система Dialog обеспечивает своим клиентам доступ к 900 базам данных и является одной из наиболее эффективных информационных служб. Одними из наиболее важных показателей эффективности информационных систем, содержащих текстовую информацию, являются семантические показатели. Семантические показатели основаны на оценке релевантности между документами и запросами. При описании технологии обработки информации в Интернета часто употребляется термин «релевантность». Очевидно, что этот термин применительно к оценке эффективности поиска в деловых ресурсах Интернета использовать нельзя. Определение релевантности предполагает, что группа экспертов просматривает весь массив (в данном случае массив деловых ресурсов Интернета) и определяет, какие из документов, хранящихся в массиве, релевантны запросу. Учитывая объем деловых ресурсов Интернета – в середине 2008 г. Он превысил 1 трлн веб-страниц, – просмотр такого массива технически не реализуем. Под полнотой выдачи сведений из деловых ресурсов Интернета следует понимать произведение средней доли просматриваемых сайтов в поисковых системах на среднюю долю «видимой» части сайта в деловых ресурсах Интернета. Таким образом, средняя полнота выдачи документов из информационных ресурсов Интернет поисковыми машинами П∑ может быть выражена формулой: П∑=П1*П2, Где П1– средняя доля просматриваемых сайтов; П2 – средняя доля видимой части сайта. Проведенные ранее исследования показали, что полнота в вербальных информационно-поисковых системах (поисковых системах Интернета) не может быть выше 50%. Указанная полнота поиска в ресурсах Интернета была бы 50%, если бы просматривался весь массив информации, находящейся на сайтах. Это максимальное значение необходимо корректировать на долю просмотра веб-страниц поисковыми машинами. Учитывая, что, по данным исследований компетентных в этой области организаций, лучшие поисковые системы Интернета просматривают не более 30 % веб-сайтов и при этом на каждом сайте просматривают только «видимую» часть (1%-5% объема сайтов), полнота поиска в Интернете с помощью поисковых систем составит менее 1%. Отсутствие публикаций, посвященных результатам количественного анализа характеристик поиска информации в Интернете по полноте выдаваемой информации и информационному шуму, вводит потребителя в заблуждение. Потребитель, как правило, не представляет, что объем не выданной, но удовлетворяющей потребителя информации, на два порядка превышает объем выданной. Если вы получили в ответе на запрос 10 документов, вы должны знать, что 990 документов, удовлетворяющих условиям запросов, остались не выданными. Эти оценки представляются даже завышенными, так как половина документов в Интернете на английском языке, а остальные документы на языках других народов мира. Анализ содержимого профессиональных баз за последние 15 лет показывает неуклонный рост доли текстовой информации в общем объеме информации профессиональных баз. Если в 1985 г. доля текстовой информации составляла 47%, то в 2000 г. – уже 84%. Представляется, что основная информация в Интернете также является текстовой. Эти обстоятельства позволяют сделать вывод о том, что подходы к оценке эффективности поиска в документальных системах в полной мере распространяются и на профессиональные базы, и на информационные ресурсы Интернета. С появлением и развитием вычислительной техники в разных странах начались исследования, связанные с оценкой возможности выявить автоматически смысл из текста. Эти исследования велись в рамках направления, получившего название «машинный перевод» и в рамках направлений по автоматизированной обработке, если входной поток сообщений включал произвольные тексты. В 1975 г. известный специалист в области компьютерной лингвистики профессор Г.Г. Белоногов сформулировал концепцию фразеологического машинного перевода текстов, которую опубликовал в предисловии к книге Д.А. Жукова «Мы переводчики»[8]. Главным тезисом этой концепции является утверждение, что при переводе текстов в качестве основных единиц смысла следует рассматривать не отдельные слова, а фразеологические сочетания, выражающие понятия, отношения между понятиями и типовые ситуации. Отдельные слова также могут использоваться, но во вторую очередь. Целью передачи информации с помощью текста, как пишет Г.Г. Белоногов[9], является не столько исчерпывающее описание мыслительных образов его автора, сколько инициация процесса порождения соответствующих мыслительных образов у читателей. Поэтому текст не столько «выражает», сколько стимулирует и «намекает», и значительная часть его содержания оказывается «между строк». Воссоздание в сознании читателей мыслительных образов, подобных мыслительным образам автора текста, осуществляется постепенно, путем восприятия предложения за предложением и «монтажа» возникающих при этом частичных образов в целостный мыслительный образ, соответствующий содержанию текста. Теоретические положения лингвистики, компьютерной лингвистики и многолетние эксперименты, проведенные на реальных текстах, неопровержимо доказывают истинность таких выводов. Единственно-верное заключение, которое можно сделать, рассматривая процесс коммуникации между источником и потребителем информации с позиций теоретических положений лингвистики и компьютерной лингвистики состоит в том, что без участия человека выявить смысл из произвольного текста невозможно.
Поиск по сайту: |