|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Семінарське заняття по темі 4: Видатні пам’ятники історії, археології, містобудування і архітектури.
Самостійна робота студента полягає у підготовці відповіді на семінарському занятті згідно з обраною темою написання контрольної роботи (область України) за таким планом: 1. Загальна характеристика кількості об’єктів історико-культурного характеру на території відповідної області, порівняння з загальноукраїнським показником. 2. Структура історико-культурного туристського потенціалу відповідної області. 3. Характеристика найбільш актрактивних об’єктів, зокрема Національних музеїв, Історико-культурних заповідників, крупних історичних центрів та центрів паломництва. 4. Включення пам’ятників історії, археології, містобудування і архітектури до сучасних туристських маршрутів. Перелік рекомендованих об’єктів по областям наведений в табл. Д.М. 14. Рекомендована література: 2, 16, 18
Семінарське заняття по темі 4: Етнографічні особливості регіонів України. Самостійна робота студента полягає у підготовці відповіді на семінарському занятті по одній з наведених етнографічних областей України (бажано обирати ту область до якої входить область визначена для написання контрольної роботи): 1. Полісся. 2. Закарпаття. 3. Галичина. 4. Буковина. 5. Волинь. 6. Поділля. 7. Наддніпрянщина. 8. Сіверщина. 9. Слобожанщина. 10. Запоріжжя. 11. Донщина. 12. Таврія. Розміення етнографічних областей наведено на рис. Д.М. 5.
Рекомендована література: 2 – 4, 10, 12 Практичне заняття на тему 4: Характеристика розвитку туристської інфраструктури: регіональний аспект. Завдання: 1. На основі наданих дидактичних матеріалів (табл. Д.М. 15) та з використанням комп’ютерної програми Статистика провести кластерний аналіз регіонів України за розвитком туристичної інфраструктури за такими складовими: - Кількість готелів та іншіх місць для тимчасового проживання; - Кількість санаторіїв та пансіонатів з лікуванням; - Кількість санаторіїв-профілакторіїв; - Кількість будинків і пансіонатів відпочинку; - Кількість баз та інші закладів відпочинку; - Кількість дитячих оздоровчих таборів; 2. Охарактеризуйте розподіл за кластерами, чим характеризуються виділені кластери, що в них спільного. 3. Перевірте коректність шуканої конфігурації об'єктів наступними методами: 1. Joining (tree clustering) (ієрархічні агломератівние методи або деревоподібна кластеризація) 2. K - means clustering (метод До середніх) 3. Two-way joining (двувходовое об'єднання). Для методу К-середніх проаналізувати отримані результати.
Рекомендації до виконання завдання: Розглянемо процедуру вирішення практичної задачі методом кластерного аналізу в системі STATISTICA. Завданням кластерного аналізу є організація спостережуваних даних в наочні структури. Для вирішення даної задачі у кластерному аналізі використовуються наступні методи: Joining (tree clustering) (ієрархічні агломератівние методи або деревоподібна кластеризація), K - means clustering (метод К -середніх), Two-way joining (покрокове об'єднання). Розберемо принцип проведення кластерного аналізу на основі даних представлених в таблиці 1. У файлі містяться дані за показником рівня життя населення та показники-аргументи, які беруть участь у класифікації. Розглянемо процес формування вибірок в системі STATISTICA. 1. З перемикача модулів STATISTICA відкрийте модуль Cluster Analysis (Кластерний аналіз). Висвітити назва модуля і далі натисніть кнопку Switch to (Переключитися в) або просто двічі клацніть мишею за назвою модуля Cluster Analysis. 2. На екрані з'явиться стартова панель модуля (рис.1) Clustering Method (методи кластерного аналізу): Joining (tree clustering) (ієрархічні агломератівние методи або деревоподібна кластеризація), K - means clustering (метод К- середніх), Two-way joining (покрокове об'єднання ). Розберемо кожен з цих методів.
Рис.5.1. Стартова панель модуля Clustering Method(методи кластерного анализу)
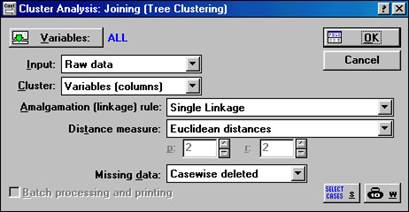
Joining (tree clustering) (ієрархічні агломеративні методи). 1. Відкриємо файл (Open Data) date_1.sta. Після вибору Joining (tree clustering) і натискання кн. ОК з'являється вікно Cluster Analysis: Joing (Tree Clustering) (вікно введення режимів роботи для ієрархічних агломератівних методів) (рис. 5.2), в якому кн. Variables дозволяє вибрати змінні беруть участь у класифікації. Натиснемо на кн. Variables і виберемо всі змінні Select All. Після відповідного вибору і натиснемо кн. OK.
Рис.5.2. Cluster Analysis: Joing (Tree Clustering) (окно вводу режимів работи для ієрархічних агломеративних методів) Також можна задати Input (тип вхідної інформації) і Cluster (режим класифікації (за ознаками або об'єктів)). Можна вказати Amalgamation (linkage) rule (правило об'єднання) і Distance measure (метрика відстаней). Codes for grouping variable (коди для груп змінної) будуть вказувати кількість аналізованих груп об'єктів. Missing data (пропущені змінні) дозволяє вибрати або прогресивне видалення змінних зі списку, або замінити їх на середні значення. Open Data-дозволяє відкрити файл з даними. Причому можна вказати умови вибору спостережень з бази даних-кн. Select Cases. Можна задавати ваги змінним, вибравши їх зі списку-кн. W. Проставте значення, як показано на рисунку 5.2
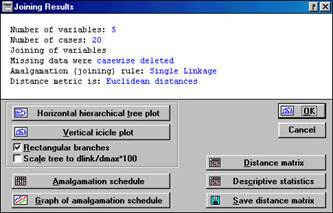
2. Після завдання всіх необхідних параметрів і натискання кн. ОК будуть проведені обчислення, а на екрані з'явиться вікно, що містить результати кластерного аналізу "Joining Results" рис.5.3.
Рис. 5.3. Окно, результатів кластерного аналізу "Joining Results"
Висновок результатів та їх аналіз
Інформаційна частина діалогового вікна Joining Results Discriminant Function Analisis Results (результати аналізу кластерних функцій) повідомляє, що • Number of variables-число змінних; • Number of cases - число спостережень; • Missing data were casewise deleted - здійснено класифікацію спостережень або змінних (залежить від рівня параметра в рядку Cluster в попередньому вікні настройки.) • Amalgation (joing) rule - правило об'єднання кластерів (назва ієрархічного агломератівного методу, заданого в рядку Amalgation rules, а в попередньому вікні настрйки); • Distanse.metric is - Метрика відстані (залежить від установки в рядку Distance measure в попередньому вікні налаштування. Користувач може викликати на екран горизонтальну і вертикальну діаграму (Horizontal hierachical plot або Vertical icicle plot). Найбільш традиційне - вертикальне подання. (Рис. 5.4).
Рис.5.4. Vertical icicle plot
Тепер уявімо собі, що поступово (дуже малими кроками) ви "послаблює" ваш критерій про те, які об'єкти є унікальними, а які ні. Іншими словами, ви знижується поріг, що відноситься до рішення про об'єднання двох або більше об'єктів в один кластер. В результаті, ви пов'язуєте разом все більше і більше число об'єктів і агрегіруете (об'єднуєте) все більше і більше кластерів, що складаються з все сильніше розрізняються елементи. Остаточно, на останньому кроці всі об'єкти об'єднуються разом. Коли дані мають ясну "структуру" в термінах кластерів об'єктів, схожих між собою, тоді ця структура, швидше за все, повинна бути відображена в ієрархічному дереві різними гілками. В результаті успішного аналізу методом об'єднання з'являється можливість виявити кластери (гілки) і інтерпретувати їх. Щоб повернутися у вікно, що містить інші результати кластерного аналізу, необхідно клацнути по Continue. Клацанням миші можна розкрити рядок Amalgamation schedule, що містить протокол об'єднання кластерів. Рис. 5.5.
Рис. 5.5. Amalgamation schedule
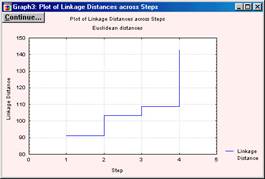
У заголовку зазначено ієрархічний агломератівний метод і метрика відстані. Таблиця може займати кілька вікон. Наступною у вікні результатів йде кнопка Graph of amalgamation schedule. Після клацання, розкривається вікно, що містить ступеневу, графічне зображення змін відстаней при об'єднанні кластерів рис. 5.6.
Рис. 5.6. Graph of amalgamation schedule
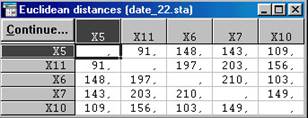
Повернувшись в основне вікно результатів та класифікації. Для перегляду ж матриці відстаней необхідно здійснити клацання на рядку Distance matrix (рис. 5.7).
Рис. 5.7 Матриця відстаней
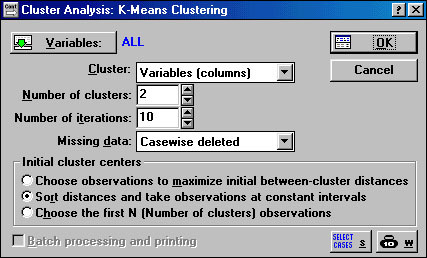
В основному вікні результатів класифікації є рядок Save distance matrix as: (Зберегти матрицю відстаней як:), що дозволяє задати ім'я файлу, в якому буде збережена матриця відстаней, яка в подальшому буде піддана обробці. Рядок Discriptive statistics містить такі найважливіші описові статистики, як середнє (means) і середньоквадратичне відхилення (standart deviations) для кожного спостереження. При проведенні класифікації n об'єктів по k ознаками, для користувача представляють великий інтерес значення цих показників для кожної ознаки. Для того щоб ці характеристики розраховувалися саме за ознаками необхідно повернуться в основний вікно налаштування параметрів і задати в рядку Cluster значення "variables (columns)". K - means clustering (метод К-середніх). Суть цього методу полягає в наступному: дослідник заздалегідь визначає кількість класів (k) на які необхідно розбити наявні спостереження, і перші k - спостережень стають центрами цих класів. Для кожного наступного спостереження розраховуються відстані до центрів кластерів і дане спостереження ставиться до того кластеру, відстань до якого була мінімальною. Після чого для цього кластеру (у якому збільшилася кількість спостережень) розраховується новий центр ваги (як середнє по кожному показнику) по всіх включеним у кластер спостереженнями. Припустимо, ви вже маєте гіпотези щодо числа кластерів (за спостереженнями або за змінним). Ви можете вказати системі утворити рівно три кластери так, щоб вони були настільки різні, наскільки це можливо. Це саме той тип завдань, які вирішує алгоритм методу K середніх. У загальному випадку метод K середніх будує рівно K різних кластерів, розташованих на якомога великих відстанях один від одного. 1. З стартової панелі модуля (рис. 5.1) Clustering Method (методи кластерного аналізу) виберемо K - means clustering (метод К- середніх). Відкриємо файл (Open Data) date_2.sta. 2. Після натискання кн. ОК з'являється вікно Cluster Analysis: K - means clustering (метод К- середніх) (рис. 5.8), в якому кн. Variables дозволяє вибрати змінні, які беруть участь у класифікації. Натиснемо на кн. Variables і виберемо всі змінні Select All. У рядку Cluster вказується як ведеться класифікація: при запуску встановлено режим Variables (colums) - класифікуються змінні на підставі їхніх спостережень, однак у переважній більшості випадків використовується режим Cases (rows) - класифікуються спостереження. Для того щоб включити режим Cases (rows) треба натиснути на кнопку у кінці рядка, після чого в віконці, що відкрилося підвести курсор на напис Cases (rows) та натиснути ліву кнопку.
Рис.5.8. Cluster Analysis: K - means clustering (метод К середніх)
У рядку Number of iterations вказується кількість ітерацій в розрахунках кластерів. Як правило, встановлених за замовчуванням 10 ітерацій цілком достатньо. У рядку Missing data встановлюється режим роботи з тими спостереженнями (або змінними, якщо встановлено режим Variables (columns) у рядку Cluster) в яких пропущені дані. Якщо встановити режим Subsituted by means (Замінювати на середню), то замість пропущеного числа буде використано середнє по цій змінній (або спостереження). Вхід у режим Subsitituted by means виконується аналогічно перемикання в рядку Cluster. Після відповідного вибору натиснемо кн. OK. Будуть зроблені обчислення і з'явиться нове вікно: "K - Means Clustering Results" (рис. 5.9).
Рис. 5.9 K - Means Clustering Results
Поиск по сайту: |