|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Нормализация базы данныхСтр 1 из 8Следующая ⇒
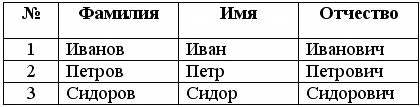
Теория проектирования баз данных Аннотация:Эта лекция знакомит с терминологией, принятой в программировании БД. Вы узнаете, какие бывают связи между таблицами, что такое ссылочная целостность баз данных, а также познакомитесь с проектированием и нормализацией таблиц и тремя нормальными формами. Введение Программирование баз данных - очень большой и серьезный раздел самого что ни на есть практического программирования. Между тем, многие программисты большую часть своего времени тратят именно на проектирование баз данных и разработку приложений, работающих с ними. Это неудивительно - в настоящее время каждая государственная организация, каждая фирма или крупная корпорация имеют рабочие места с компьютерами. Имеется масса данных, которые нужно не только сохранить, но и обработать, получить комплексные отчеты. Без баз данных сегодня не обойтись. А завтра они будут еще нужней. Недостаточно просто написать программу, взаимодействующую с БД. Нужно уметь правильно спроектировать эту базу данных. Проектирование баз данных, в общем, является первым шагом разработки приложения. Только когда база данных спроектирована, программист приступает непосредственно к проекту приложения. На этой лекции мы коротко определимся с терминологией БД , затем изучим вопросы проектирования баз данных. Этот курс лекций целиком и полностью посвящен базам данных и разработке приложений, обслуживающих их. Типы баз данных: локальные, файл-серверные, клиент-серверные ираспределенные БД. Мы продолжим знакомство с локальными БД. Мы познакомимся с различными механизмами доступа к базам данных. Изучим архитектуру клиент-сервер, которая является наиболее востребованной сегодня архитектурой программирования БД. Также рассмотрим механизмы создания распределенных (или многоуровневых) баз данных. Файл-серверные БД имеют очень ограниченные возможности, и в настоящий момент практически не используются, поэтому мы не будем касаться этой темы. Вместо этого гораздо удобней использовать распределенную архитектуру совместно с применением локальных технологий. Обо всем этом и о многом другом мы поговорим на этом курсе. Терминология Базой данных (БД) называется электронное хранилище информации, доступ к которому имеет один или несколько компьютеров. В былые времена под базой данных понимали файл, где данные хранились в табличном виде. Сейчас под базой данных обычно подразумевают папку, в которой хранится один или несколько файлов с таблицами. Эти таблицы, вместе или по отдельности, взаимодействуют с пользовательским приложением. Существуют базы данных, в которых таблицы, индексы и другие служебные данные хранятся в одном файле. К таким БД можно отнести, например, MS Access и InterBase. В этом случае базой данных будет созданный файл. Таблицы имеющие связи между собой, называют реляционными, и базы данных, в которых имеются взаимосвязанные таблицы, также называются реляционными. Реляционные базы данных в настоящее время наиболее распространены. Часто пользовательские приложения не работают с базами данных напрямую. Имеются специальные программы, называемые Системы Управления Базами Данных( СУБД ), которые служат посредниками между базой данных и пользовательским приложением. Такой подход называют архитектурой клиент-сервер, а такие СУБД часто называют серверами баз данных. Иногда еще добавляют букву Р (РСУБД - Реляционная СУБД ). Однако не все СУБД предназначены для архитектуры клиент-сервер. Например, программа Access из пакета MS Office - это СУБД, предназначенная для локального или файл-серверного использования. Основой любой БД является таблица. Таблица - это файл определенного формата с данными, представленными в табличном виде, например:
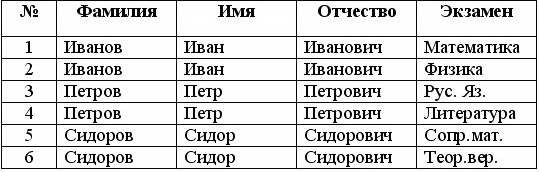
Такая таблица состоит из полей и записей. Поле - столбец таблицы, имеющий название, тип данных и размер. Поле предназначено для описания отдельного атрибута записи. Например, поле "№" имеет целочисленный тип данных, а поле "Фамилия" - строковый. Запись - строка таблицы, описывающая какой-то объект, или иначе, набор атрибутов какого-то объекта. Например, строка под номером 1 описывает человека - Иванова Ивана Ивановича. Первичный ключ - это поле или набор полей, однозначно идентифицирующих запись. В ключевом поле не может быть двух записей с одинаковым значением. Например, поле "Фамилия" нельзя делать ключевым, ведь в таблице могут оказаться однофамильцы. Поле"№" больше подходит для того, чтобы сделать его ключевым. Первичные ключи помогают упорядочить записи и облегчают установку связей между таблицами. Каждая таблица может содержать только один первичный ключ. Индекс - это поле или набор полей, которые часто используются для сортировки или поиска данных. Индексные поля еще называют вторичными ключами. В отличие от первичных ключей, поля для индексов могут содержать как уникальные, так и повторяющие значения. Например, поле "Фамилия" можно сделать индексным - ведь поиск и сортировка записей часто может производиться по этому полю. Индексы могут быть уникальными, то есть, не допускающими совпадений в записях, как первичные ключи, и не уникальными, допускающими такие совпадения. Индексы могут быть как в восходящем порядке (А, Б, …, Я), так и в нисходящем (Я, Ю, …, А). Таблица может иметь множество индексов. Можно все поля сделать индексными, причем даже на каждое поле по два индекса - в восходящем и нисходящем порядке. Однако при этом следует иметь в виду, что база данных в этом случае будет непомерно раздута, и работа с ней значительно замедлится. Другими словами, нужно соблюдать меру, и делать индексными только те поля, по которым действительно часто придется сортировать или фильтровать данные. Связи (отношения) Реляционные связи (отношения) между таблицами предназначены для разбивки таблиц на самодостаточные части. Рассмотрим пример. Допустим, люди из предыдущей таблицы - студенты. Таблица предназначена для того, чтобы указать, какие экзамены были сданы конкретным студентом. Следовательно, в таблицу требуется добавить поле "Экзамен":
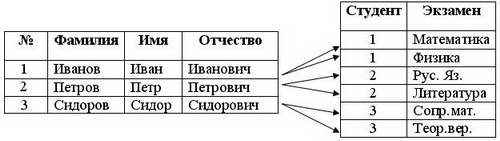
Сразу бросается в глаза недостаток такого проектирования: данные из полей "Фамилия", "Имя" и "Отчество" многократно повторяются. Пользователю придется вводить большое количество дублирующих данных, а таблица получается "распухшей", переполненной этими данными. Исправить положение несложно, нужно лишь разбить эту таблицу на две разных таблицы, имеющие релятивную связь:
Как вы можете заметить, избыточность данных исчезла - в одной таблице представлены только данные по студентам, в другой - данные по экзаменам. Связь между таблицами организована по ключевому полю "№" таблицы со студентами. В таблице с экзаменами, вместо полных данных о студенте вписывается только его номер. Студент может сдать сколько угодно много экзаменов, пользователь же просто выберет его из списка, и в таблицу попадет его номер. Такую таблицу легче заполнять, и размер ее будет тоже меньше. При создании связей, как правило, одна таблица называется главной (master), другая - подчиненной (details). В нашем случае главной является таблица со студентами. Таблица со списком сданных экзаменов - подчиненная. Связь, представленная в рисунке 1.3 называется отношением один-ко-многим. То есть, одна запись из одной таблицы может иметь связь с множеством записей из другой таблицы. Однако имеется возможность и того, что запись из первой таблицы не будет иметь никаких связей с другой таблицей - студент может еще не сдать ни одного экзамена. Отношение один-ко-многим встречается наиболее часто. Отношение один-к-одному подразумевает, что одной записи в главной таблице соответствует одна запись в подчиненной таблице. Взгляните на рисунок:
Данные о студентах, такие как фамилия, группа, могут часто использоваться для самых разных отчетов. Однако домашний адрес и телефон студентов нужны далеко не всегда, поэтому они вынесены в другую таблицу. Если бы мы объединили эти таблицы в одну, то получили бы таблицу с переизбытком данных. Связь один-к-одному используют для того, чтобы отделить главную информацию от второстепенных данных. Отношение многие-ко-многим встречается реже. Такое отношение подразумевает, что одна запись из главной таблицы может иметь связь со многими записями из подчиненной таблицы. А одна запись из подчиненной таблицы может иметь связь со многими записями главной таблицы. Рассмотрим следующий рисунок:
Как видно из рисунка, один покупатель может купить несколько товаров, в то же время как один товар может быть куплен несколькими покупателями. Считается, что базу данных можно спроектировать так, чтобы любая связь многие-ко-многим была бы заменена одной или более связями один-ко-многим. В самом деле, подобные отношения сложно отлаживать. Не все СУБД поддерживают индексацию и контроль над ссылочной целостностью в таких связях, поэтому старайтесь избегать отношений многие-ко-многим. Ссылочная целостность Ссылочной целостностью называют особый механизм, осуществляемый средствами СУБД или программистом, ответственный за поддержание непротиворечивых данных в связанных релятивными отношениями таблицах. Ссылочная целостность подразумевает, что в таблицах, имеющих релятивные связи, нет ссылок на несуществующие записи. Взгляните на рис. 1.3. Если мы удалим из списка студента Иванова И.И., и при этом не изменим таблицу со сданными экзаменами, ссылочная целостность будет нарушена, в таблице с экзаменами появится "мусор" - данные, на которые не ссылается ни одна запись из таблицы студентов. Ссылочная целостность будет нарушена. Таким образом, если мы удаляем из списка студента Иванова И.И., следует позаботиться о том, чтобы из таблицы со сданными экзаменами также были удалены все записи, на которые ранее ссылалась удаленная запись главной таблицы. Существует несколько видов изменений данных, которые могут привести к нарушению ссылочной целостности: 1. Удаляется запись в родительской таблице, но не удаляются соответствующие связанные записи в дочерней таблице. 2. Изменяется запись в родительской таблице, но не изменяются соответствующие ключи в дочерней таблице. 3. Изменяется ключ в дочерней таблице, но не изменяется значение связанного поля родительской таблицы. Многие СУБД блокируют действия пользователя, которые могут привести к нарушению связей. Нарушение хотя бы одной такой связи делает информацию в БД недостоверной. Если мы, например, удалили Иванова И.И., то теперь номер 1 принадлежит Петрову П.П.. Имеющиеся связи указывают, что он сдал экзамены по математике и физике, но не сдавал экзаменов по русскому языку и литературе. Достоверность данных нарушена. Конечно, в таких случаях в качестве ключа обычно используют счетчик - поле автоинкрементного типа. Если удалить запись со значением 1, то другие записи не изменят своего значения, значение 1 просто невозможно будет присвоить какой-то другой записи, оно будет отсутствовать в таблице. Путаницы в связях не случится, однако все равно подчиненная таблица будет иметь "потерянные" записи, не связанные ни с какой записью главной таблицы. Механизм ссылочной целостности должен запрещать удаление записи в главной таблице до того, как будут удалены все связанные с ней записи в дочерней таблице. Нормализация базы данных Каждый программист обычно по-своему проектирует базу данных для программы, над которой работает. У одних это получается лучше, у других - хуже. Качество спроектированной БД в немалой степени зависит от опыта и интуиции программиста, однако существуют некоторые правила, помогающие улучшить проектируемую БД. Такие правила носят рекомендательный характер, и называются нормализацией базы данных. Процесс нормализации данных заключается в устранении избыточности данных в таблицах. Существует несколько нормальных форм, но для практических целей интерес представляют только первые три нормальные формы. Первая нормальная форма ( 1НФ ) требует, чтобы каждое поле таблицы БД было неделимым (атомарным) и не содержало повторяющихся групп. Неделимость означает, что в таблице не должно быть полей, которые можно разбить на более мелкие поля. Например, если в одном поле мы объединим фамилию студента и группу, в которой он учится, требование неделимости соблюдаться не будет. Первая нормальная форма требует, чтобы мы разбили эти данные по двум полям. Под понятием повторяющиеся группы подразумевают поля, содержащие одинаковые по смыслу значения. Взгляните на рисунок:
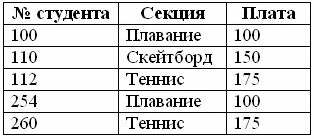
Верно, такую таблицу можно сделать, однако она нарушает правило первой нормальной формы. Поля "Студент 1", "Студент 2" и "Студент 3" содержат одинаковые по смыслу объекты, их требуется поместить в одно поле "Студент", как в рисунке 1.4. Ведь в группе не бывает по три студента, правда? Представляете, как будет выглядеть таблица, содержащая данные на тридцать студентов? Это тридцать одинаковых полей! В приведенном выше рисунке поля описывают студентов в формате "Фамилия И.О.". Однако если оператор будет вводить эти описания в формате "Фамилия Имя Отчество", то нарушается также правило неделимости. В этом случае каждое такое поле следует разбить на три отдельных поля, так как поиск может вестись не только по фамилии, но и по имени или по отчеству. Вторая нормальная форма ( 2НФ ) требует, чтобы таблица удовлетворяла всем требованиям первой нормальной формы, и чтобы любое не ключевое поле однозначно идентифицировалось полным набором ключевых полей. Рассмотрим пример: некоторые студенты посещают спортивные платные секции, и ВУЗ взял на себя оплату этих секций. Взгляните на рисунок:
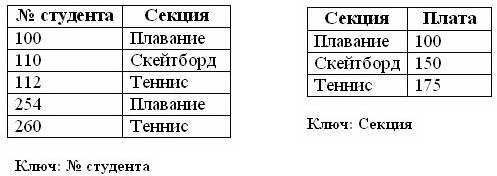
В чем здесь нарушение? Ключом этой таблицы служат поля "№ студента" - "Секция". Однако данная таблица также содержит отношение "Секция" - "Плата". Если мы удалим запись студента № 110, то потеряем данные о стоимости секции по скейтборду. А после этого мы не сможем ввести информацию об этой секции, пока в нее не запишется хотя бы один студент. Говорят, что такое отношение подвержено как аномалии удаления, так и аномалии вставки. В соответствие с требованиями второй нормальной формы, каждое не ключевое поле должно однозначно зависеть от ключа. Поле "Плата" в приведенном примере содержит сведения от стоимости данной секции, и ни коим образом не зависит от ключа - номера студента. Таким образом, чтобы удовлетворить требованию второй нормальной формы, данную таблицу следует разбить на две таблицы, каждая из которых зависит от своего ключа:
Мы получили две таблицы, в каждой из которых не ключевые данные однозначно зависят от своего ключа. Третья нормальная форма ( 3НФ ) требует, чтобы в таблице не имелось транзитивных зависимостей между не ключевыми полями, то есть, чтобы значение любого поля, не входящего в первичный ключ, не зависело от другого поля, также не входящего в первичный ключ. Допустим, в нашей студенческой базе данных есть таблица с расходами на спортивные секции:
Как нетрудно заметить, ключевым полем здесь является поле "Секция". Поля "Плата" и "Кол-во студентов" зависят от ключевого поля и не зависят друг от друга. Однако поле "Общая стоимость" зависит от полей "Плата" и "Кол-во студентов", которые не являются ключевыми, следовательно, нарушается правило третьей нормальной формы. Поле "Общая стоимость" в данном примере можно спокойно убрать из таблицы, ведь если потребуется вывести такие данные, нетрудно будет перемножить значения полей "Плата" и "Кол-во студентов", и создать для вывода вычисляемое поле. Таким образом, нормализация данных подразумевает, что вы вначале проектируете свою базу данных: планируете, какие таблицы у вас будут, какие в них будут поля, какого типа и размера. Затем вы приводите каждую таблицу к первой нормальной форме. После этого приводите полученные таблицы ко второй, затем к третьей нормальной форме, после чего можете утверждать, что ваша база данных нормализована. Однако такой подход имеет и недостатки: если вам требуется разработать программный комплекс для крупного предприятия, база данных будет довольно большой. При нормализации данных, вы можете получить сотни взаимосвязанных между собой таблиц. С увеличением числа нормализованных таблиц уменьшается восприятие программистом базы данных в целом, то есть вы можете потерять общее представление вашей базы данных, запутаетесь в связях. Кроме того, поиск в чересчур нормализованных данных может быть замедлен. Отсюда вывод: при работе с данными большого объема ищите компромисс между требованиями нормализации и собственным общим восприятием базы данных.
Лекция 2:
Поиск по сайту: |