|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Архитектура и стандартизация сетей 7 страница
Кадры этого подуровня могут использоваться в различных целях, но пока в стандартах Ethernet для них определена только одна задача — приостановка передачи кадров другими узлами на определенное время.
Рис. 13.14. Подуровень управления уровня MAC
Кадр подуровня управления отличается от кадров пользовательских данных тем, что в поле типа всегда содержится шестнадцатеричное значение 88-08. Формат кадра подуровня управления рассчитан на универсальное применение, поэтому он достаточно сложен (рис. 13.15).
Рис. 13.15. Формат кадра подуровня управления
В качестве адреса назначения можно указывать зарезервированное для этой цели значения группового адреса 01-80-С2-00-00-01. Это удобно, когда соседний узел также являете коммутатором (так как порты коммутатора не имеют уникальных МАС-адресов). Если сосед — конечный узел, можно также использовать уникальный МАС-адрес. В поле кода операции подуровня управления указывается шестнадцатеричный код 00-01, поскольку, как уже было отмечено, пока определена только одна операция подуровня управления — она называется PAUSE (пауза) и имеет шестнадцатеричный код 00-01. В поле параметров подуровня управления указывается время, на которое узел, получивший такой код, должен прекратить передачу кадров узлу, отправившему кадр с операцией PAUSE. Время измеряется в 512 битовых интервалах конкретной реализации Ethernet, диапазон возможных вариантов приостановки равен 0-65535. Как видно из описания, этот механизм обратной связи относится к типу 2 в соответствии с классификацией, приведенной в главе 7. Специфика его состоит в том, что в нем предусмотрена только одна операция — приостановка на определенное время. Обычно же в механизмах этого типа используются две операции — приостановка и возобновление передачи кадров. Проблема, иллюстрируемая рис. 13.13, может быть решена и другим способом: применением так называемого магистрального, или восходящего (uplink), порта. Магистральные порты в коммутаторах Ethernet это порты следующего уровня иерархии скорости по сравнению с портами, предназначенными для подключения пользователей. Например, если коммутатор имеет 12 портов Ethernet стандарта 10 Мбит/с, то магистральный порт должен быть портом Fast Ethernet, чтобы его скорость была достаточна для передачи до 10 потоков от входных портов. Обычно низкоскоростные порты коммутатора служат для соединения с пользовательскими компьютерами, а магистральные порты — для подключения либо сервера, к которому обращаются пользователи, либо коммутатора более I высокого уровня иерархии. На рис. 13.16 показан пример коммутатора, имеющего 24 порта стандарта Fast Ethernet со скоростью 100 Мбит/с, к которым подключены пользовательские компьютеры, и один порт стандарта Gigabit Ethernet со скоростью 1000 Мбит/с, к которому подключен сервер. При такой конфигурации коммутатора вероятность перегрузки портов существенно снижается по сравнению с вариантом, когда все порты поддерживают одинаковую скорость. Хотя возможность перегрузки по-прежнему существует, для этого необходимо, чтобы более чем 10 пользователей одновременно обменивались с сервером данными со средней скоростью, близкой к максимальной скорости их соединений — а такое событие достаточно маловероятно.
Рис. 13.16. Коммутатор рабочей группы
Из приведенного примера видно, что вероятность перегрузки портов коммутаторов зависит от распределения трафика между его портами, кроме того, понятно, что даже при хорошем соответствии скорости портов наиболее вероятному распределению трафика полностью исключить перегрузки невозможно. Поэтому в общем случае для уменьшения потерь кадров из-за перегрузок нужно применять оба средства: подбор скорости портов для наиболее вероятного распределения трафика в сети и протокол 802.3х для снижения скорости источника трафика в тех случаях, когда перегрузки все-таки возникают.
Характеристики производительности коммутаторов
Скорости фильтрации и продвижения кадров — две основные характеристики производительности коммутатора. Эти характеристики являются интегральными, они не зависят от того, каким образом технически реализован коммутатор. Скорость фильтрации — это скорость, с которой коммутатор выполняет следующие этапы обработки кадров: 1. Прием кадра в свой буфер. 2. Просмотр адресной таблицы с целью нахождения порта для адреса назначения кадра. 3. Уничтожение кадра, так как его порт назначения и порт источника принадлежат одному логическому сегменту. Скорость фильтрации практически у всех коммутаторов блокирующим фактором не является — коммутатор успевает отбрасывать кадры в темпе их поступления. Скорость продвижения — это скорость, с которой коммутатор выполняет следующие этапы обработки кадров. 1. Прием кадра в свой буфер. 2. Просмотр адресной таблицы с целью нахождения порта для адреса назначения кадра. 3. Передача кадра в сеть через найденный по адресной таблице порт назначения. Как скорость фильтрации, так и скорость продвижения измеряются обычно в кадрах в секунду. Если в характеристиках коммутатора не уточняется, для какого протокола и для какого размера кадра приведены значения скоростей фильтрации и продвижения, то по умолчанию считается, что эти показатели даются для протокола Ethernet и кадров минимального размера, то есть кадров длинной 64 байт. Как мы уже обсуждали, режим передачи кадров минимальной длины используется как наиболее сложный тест, который должен подтвердить способность коммутатора работать при наихудшем сочетании параметров трафика. Задержка передачи кадра измеряется как время, прошедшее с момента прихода первого байта кадра на входной порт коммутатора до момента появления этого байта на его выходном порту. Задержка складывается из времени, затрачиваемого на буферизацию байтов кадра, и времени, затрачиваемого на обработку кадра коммутатором – просмотр адресной таблицы, принятие решения о фильтрации или продвижении, получение доступа к среде выходного порта. Величина вносимой коммутатором задержки зависит от режима его работы. Если коммутация осуществляется «на лету», то задержки обычно невелики и составляют от 5 до 40 мкс, а при полной буферизации кадров — от 50 до 200 мкс для кадров минимальной длины при передаче со скоростью 10 Мбит/с. Коммутаторы, поддерживающие более скоростные версии Ethernet, вносят меньшие задержки в процесс продвижения кадров. Производительность коммутатора определяется количеством пользовательских данных, переданных в единицу времени через его порты, и измеряется в мегабитах в секунду (Мбит/с). Так как коммутатор работает на канальном уровне, для него пользовательскими данными являются те данные, которые переносятся в поле данных кадров Ethernet Максимальное значение производительности коммутатора всегда достигается на кадрах максимальной длины, так как при этом доля накладных расходов на служебную информацию кадра минимальна. Коммутатор — это многопортовое устройство, поэтому для него в качестве характеристики принято давать максимальную суммарную производительность при одновременной передаче трафика по всем его портам. Для выполнения операций каждого порта в коммутаторах чаще всего используется выделенный процессорный блок со своей памятью для хранения собственного экземпляра адресной таблицы. Каждый порт хранит только те наборы адресов, с которыми он работал в последнее время, поэтому экземпляры адресной таблицы разных процессорных модулей, как правило, не совпадают. Значение максимального числа МАС-адресов, которое может запомнить процессор порта, зависит от области применения коммутатора. Коммутаторы рабочих групп обычно поддерживают всего несколько адресов на порт, так как они предназначены для образования микросегментов. Коммутаторы отделов должны поддерживать несколько сотен адресов, а коммутаторы магистралей сетей — до нескольких тысяч (обычно 4000-8000 адресов). Недостаточная емкость адресной таблицы может служить причиной замедления работы коммутатора и засорения сети избыточным трафиком. Если адресная таблица процессора порта полностью заполнена, а он встречает новый адрес источника в поступившем кадре, процессор должен удалить из таблицы какой-либо старый адрес и поместить на его место новый. Эта операция сама по себе отнимает у процессора часть времени, но главные потери производительности наблюдаются при поступлении кадра с адресом назначения, который пришлось удалить из адресной таблицы. Так как адрес назначения кадра неизвестен, коммутатору приходится передавать этот кадр на все остальные порты. Некоторые производители коммутаторов решают эту проблему за счет изменения алгоритма обработки кадров с неизвестным адресом назначения. Один из портов коммутатора конфигурируется как магистральный порт, на который по умолчанию передаются все кадры с неизвестным адресом. Передача кадра на магистральный порт производится в расчете на то, что этот порт подключен к вышестоящему коммутатору (при иерархическом соединении коммутаторов в крупной сети), который имеет достаточную емкость адресной таблицы и «знает», куда можно передать любой кадр.
Скоростные версии Ethernet
Скорость 10 Мбит/с первой стандартной версии Ethernet долгое время удовлетворяла потребности пользователей локальных сетей. Однако в начале 90-х годов начала ощущаться недостаточная пропускная способность Ethernet, так как скорость обмена с сетью стала существенно меньше скорости внутренней шины компьютера. Кроме того, начали появляться новые мультимедийные приложения, гораздо более требовательные к скорости сети, чем их текстовые предшественники. В поисках решения проблемы ведущие производители сетевого оборудования начали интенсивные работы по повышению скорости Ethernet при сохранении главного достоинства этой технологии - простоты и низкой стоимости оборудования. Результатом стало появление новых скоростных стандартов Ethernet: Fast Ethernet (скорость 100 Мбит/с), Gigabit Ethernet (1000 Мбит/с, или 1 Гбит/с) и 10G Ethernet (10 Гбит/с). На время написания этой книги два новых стандарта — 40G Ethernet и 100G Ethernet — находились в стадии разработки, обещая следующее десятикратное превышение верхней границы производительности Ethernet. Разработчикам новых скоростных стандартов Ethernet удалось сохранить основные черты классической технологии Ethernet и, прежде всего, простой способ обмена кадрами без встроенных в технологию сложных контрольных процедур. Этот фактор оказался решающим в соревновании технологий локальных сетей, так как выбор пользователей всегда склонялся в пользу простого наращивания скорости сети, а не в пользу решений, связанных с более эффективным расходованием той же самой пропускной способности с помощью более сложной и дорогой технологии. Примером такого подхода служит переход с оборудования Fast Ethernet на Gigabit Ethernet вместо перехода на оборудование ATM со скоростью 155 Мбит/с. Несмотря на значительную разницу в пропускной способности (1000 Мбит/с против 155 Мбит/с), оба варианта обновления сети примерно равны по степени положительного влияния на «самочувствие» приложений, так как Gigabit Ethernet достигает нужного эффекта за счет равного повышения доли пропускной способности для всех приложений, a ATM перераспределяет меньшую пропускную способность более тонко, дифференцируя ее в соответствии с потребностями приложений. Тем не менее, пользователи предпочли не вдаваться в детали и тонкости настройки сложное оборудования, когда можно просто применить знакомое и простое, но более скоростное оборудование Ethernet. Значительный вклад в «победу» Ethernet внесли также коммутаторы локальных сетей, так как их успех привел к отказу от разделяемой среды, где технология Ethernet всегда была уязвимой из-за случайного характера метода доступа. Начиная с версии 10G Ethernet, разработчики перестали включать вариант работы на разделяемой среде в описание стандарта. Коммутаторы с портами Fast Ethernet, Gigabit Ethernet и 10G Ethernet работают по одному и тому же алгоритму, описанному в стандарте IEEE 802.1D. Возможность, комбинировав порты с различными скоростями в диапазоне от 10 Мбит/с до 10 Гбит/с делает коммун торы Ethernet гибкими и эффективными сетевыми устройствами, позволяющими строив разнообразные сети. Повышение скорости работы Ethernet было достигнуто за счет улучшения качества кабелей, применяемых в компьютерных сетях, а также совершенствования методов кодирования данных при их передаче по кабелям, то есть за счет совершенствования физического уровня технологии.
Архитектура коммутаторов
Для ускорения операций коммутации сегодня во всех коммутаторах используются заказные специализированные БИС — ASIC, которые оптимизированы для выполнения основных операций коммутации. Часто в одном коммутаторе имеется несколько специализированных БИС, каждая из которых выполняет функционально законченную часть операций. Важную роль в построении коммутаторов играют также программируемые микросхемы FPGA (Field-Programmable Gate Array — программируемый в условиях эксплуатации массив вентилей). Эти микросхемы могут выполнять все функции, которые выполняют микросхемы ASIC, но в отличие от последних эти функции могут программироваться и перепрограммироваться производителями коммутаторов {и даже пользователями). Это свойство позволило резко удешевить процессоры портов коммутаторов, выполняющих сложные операции, например, профилирование трафика, так как производитель FPGA выпускает свои микросхемы массово, а не по заказу того или иного производителя оборудования. Кроме того, применение микросхем FPGA позволяет производителям коммутаторов оперативно вносить изменения в логику работы порта при появлении новых стандарте или изменении действующих. Помимо процессорных микросхем для успешной неблокирующей работы коммутатора нужно иметь быстродействующий узел обмена, предназначенный для передачи кадра между процессорными микросхемами портов. В настоящее время в коммутаторах узел обмена строится на основе одной из трех cxем.
Часто эти три схемы комбинируются в одном коммутаторе. Коммутационная матрица обеспечивает наиболее простой способ взаимодействия процессоров портов, и именно этот способ был реализован в первом промышленном коммутаторе локальных сетей. Однако реализация матрицы возможна только для определенного числа портов, причем сложность схемы возрастает пропорционально квадрату количества портов коммутатора (рис. 13.23).
Рис. 13.23. Коммутационная матрица
Более детальное представление одного из возможных вариантов реализации коммутационной матрицы для восьми портов дано на рис, 13.24. Входные блоки процессоров портов на основании просмотра адресной таблицы коммутатора определяют по адресу назначения номер выходного порта. Эту информацию они добавляют к байтам исходного кадра в виде специального ярлыка — тега. Для данного примера тег представляет собой просто 3-разрядное двоичное число, соответствующее номеру выходного порта.
Рис. 13.24. Реализация коммутационной матрицы 8 х 8 с помощью двоичных переключателей
Матрица состоит из трех уровней двоичных переключателей, которые соединяют свой вход с одним из двух выходов в зависимости от значения бита тега. Переключатели первого уровня управляются первым битом тега, второго — вторым, а третьего — третьим. Матрица может быть реализована и иначе, на основании комбинационных схем другого типа, но ее особенностью все равно остается технология коммутации физических каналов, Известным недостатком этой технологии является отсутствие буферизации данных внутри коммутационной матрицы — если составной канал невозможно построить из-за занятости выходного порта или промежуточного коммутационного элемента, то данные должны накапливаться в их источнике, в данном случае — во входном блоке порта, принявшего кадр. Основные достоинства таких матриц — высокая скорость коммутации и регулярная структура, которую удобно реализовывать в интегральных микросхемах. Зато после реализации матрицы N*N в составе БИС проявляется еще один ее недостаток — сложность наращивания числа коммутируемых портов. В коммутаторах с общей шиной процессоры портов связывают высокоскоростной шиной, используемой в режиме разделения времени. Пример такой архитектуры приведен на рис. 13.25. Чтобы шина не блокировала работу коммутатора, се производительность должна равняться, по крайней мере, сумме производительностей всех портов коммутатора. Для модульных коммутаторов характерно то, что путем удачного подбора модулей с низкоскоростными портами можно обеспечить неблокирующий режим работы, но в то же время некоторые сочетания модулей с высокоскоростными портами могут приводить к структурам, у которых узким местом является общая шина.
Рис. 13.25. Архитектура коммутатора с общей шиной
Кадр должен передаваться по шине небольшими частями, по несколько байтов, чтобы передача кадров между портами происходила в псевдопараллельном режиме, не вносят задержек в передачу кадра в целом. Размер такой ячейки данных определяется производителем коммутатора. Некоторые производители выбирают в качестве порции данным переносимых по шине за одну операцию, ячейку ATM с ее полем данных в 48 байт. Такой подход облегчает трансляцию протоколов локальных сетей в протокол ATM, если коммутатор поддерживает эти технологии. Кроме того, небольшой размер ячейки (ее формат может быть и фирменным, так как перенос данных между портами является сугубо внутренне операцией) уменьшает задержки доступа порта к общей шине. Входной блок процессора помещает в ячейку, переносимую по шине, тег, в котором указывает номер порта назначения. Каждый выходной блок процессора порта содержит фильтр тегов, который выбирает теги, предназначенные данному порту. Шина, так же как и коммутационная матрица, не может осуществлять промежуточную буферизацию, но поскольку данные кадра разбиваются на небольшие ячейки, задержек с начальным ожиданием доступности выходного порта в такой схеме нет — здесь работает принцип коммутации пакетов, а не каналов. Разделяемая многовходовая память представляет собой третью базовую архитектуру взаимодействия портов. Пример такой архитектуры приведен на рис. 13.26.
Рис. 13.26. Архитектура коммутаторов с разделяемой памятью
Входные блоки процессоров портов соединяются с переключаемым входом разделяемой памяти, а выходные блоки этих же процессоров - с ее переключаемым выходом. Переключением входа и выхода разделяемой памяти управляет менеджер очередей выходных портов. В разделяемой памяти менеджер организует несколько очередей данных, по одной для каждого выходного порта. Входные блоки процессоров передают менеджеру портов запросы на запись данных в очередь того порта, который соответствует адресу назначения кадра. Менеджер по очереди подключает вход памяти к одному из входных блоков процессоров, и тот переписывает часть данных кадра в очередь определенною выходного порта. По мере заполнения очередей менеджер производит также поочередное подключение выхода разделяемой памяти к выходным блокам процессоров портов, и данные из очереди переписываются в выходной буфер процессора. Применение общей буферной памяти, гибко распределяемой менеджером между отдельными портами, снижает требования к размеру буферной памяти процессора порта. Однако буферная память должна быть достаточно быстродействующей для поддержания необходимой скорости обмена данными между N портами коммутатора. Комбинированные коммутаторы. У каждой из описанных архитектур есть свои достоинства и недостатки, поэтому часто в сложных коммутаторах эти архитектуры применяются в комбинации друг с другом. Пример такого комбинирования приведен на рис. 13.27. Коммутатор состоит из модулей с фиксированным количеством портов (2-12), выполненных на основе специализированной БИС, реализующей архитектуру коммутационной матрицы. Если порты, между которыми нужно передать кадр данных, принадлежат одному модулю, то передача кадра осуществляется процессорами модуля на основе имеющейся модуле коммутационной матрицы. Если же порты принадлежат разным модулям, то процессоры общаются по общей шине. В такой архитектуре передача кадров внутри модуля будет происходить быстрее, чем при межмодульной передаче, так как коммутационная матрица — это наиболее быстрое, хотя и наименее масштабируемое средство взаимодействия портов. Скорость внутренней шины коммутаторов может достигать нескольких гигабит в секунду, а у наиболее мощных моделей — до нескольких десятков гигабит в секунду.
Рис. 13.27. Комбинирование архитектур коммутационной матрицы и общей шины
Виртуальные локальные сети
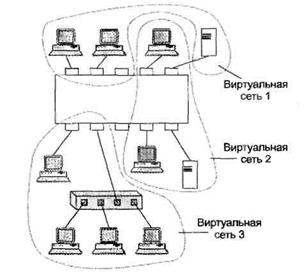
Важным свойством коммутатора локальной сети является способность контролировать передачу кадров между сегментами сети. По различным причинам (соблюдение нрав доступа, политика безопасности и т. д.) некоторые кадры не следует передавать по адресу назначения, Как мы выяснили в предыдущем разделе, ограничения такого типа можно реализовать с помощью пользовательских фильтров. Однако пользовательский фильтр может запретить коммутатору передачу кадров только по конкретным адресам, а широковещательный трафик он обязан передать всем сегментам сети. Так требует алгоритм его работы. Поэтому, как уже отмечалось, сети, созданные на основе коммутаторов, иногда называют плоскими — из-за отсутствия барьеров на пути широковещательного трафика. Технология виртуальных локальных сетей позволяет преодолеть указанное ограничение. Виртуальной локальной сетью (Virtual Local Area Network, VLAN) называется группа узлов сети, трафик которой, в том числе широковещательный, на канальном уровне полностью изолирован от трафика других узлов сети.
Рис. 14.10. Виртуальные локальные сети.
Это означает, что передача кадров между разными виртуальными сетями на основании адреса канального уровня невозможна независимо от типа адреса (уникального, группового или широковещательного). В то же время внутри виртуальной сети кадры передаются по технологии коммутации, то если только на тот порт, который связан с адресом назначения кадра. Виртуальные локальные сети могут перекрываться, если один или несколько компьютеров входят в состав более чем одной виртуальной сети. На рис. 14.10 сервер электронной почты входит в состав виртуальных сетей 3 и 4. Это означает, что его кадры передаются коммутаторами всем компьютерам, входящим в эти сети. Если же какой-то компьютер входит в состав только виртуальной сети 3, то его кадры до сети 4 доходить не будут, но он может взаимодействовать с компьютерами сети 4 через общий почтовый сервер. Такая схема защищает виртуальные сети друг от друга не полностью, например, широковещательный шторм, возникший на сервере электронной почты, затопит и сеть 3, и сеть 4. Говорят, что виртуальная сеть образует домен широковещательного трафика по аналогии с доменом коллизий, который образуется повторителями сетей Ethernet.
Назначение виртуальных сетей
Как мы видели на примере из предыдущего раздела, с помощью пользовательских фильтров можно вмешиваться в нормальную работу коммутаторов и ограничивать взаимодействие узлов локальной сети в соответствии с требуемыми правилами доступа. Однако механизм пользовательских фильтров коммутаторов имеет несколько недостатков:
Техника виртуальных локальных сетей решает задачу ограничения взаимодействия узлов сети другим способом. Основное назначение технологии VLAN состоит в облегчении процесса создания изолированных сетей, которые затем обычно связываются между собой с помощью маршрутизаторов. Такое построение сети создает мощные барьеры на пути нежелательного трафика из одной сети в другую. Сегодня считается очевидным, что любая крупная есть должна включать маршрутизаторы, иначе потоки ошибочных кадров, например широковещательных, будут периодически «затапливать» всю сеть через прозрачные для них коммутаторы, приводя ее в неработоспособное состояние. Достоинством технологии виртуальных сетей является то, что она позволяет создавать полностью изолированные сегменты сети, путем логического конфигурирования коммутаторов, не прибегая к изменению физической структуры. До появления технологии VLAN для создания отдельной сети использовались либо физически изолированные сегменты коаксиального кабеля, либо не связанные между собой сегменты, построенные на повторителях и мостах. Затем эти сети связывались маршрутизаторами в единую составную сеть (рис. 14.11). Изменение состава сегментов (переход пользователя в другую сеть, дробление крупных сегментов) при таком подходе подразумевает физическую перекоммутацию разъемов на передних панелях повторителей или на кроссовых панелях, что не очень удобно в больших сетях - много физической работы, к тому же высока вероятность ошибки.
Рис. 14.11. Составная сеть, состоящая из сетей, построенных на основе повторителей
Для связывания виртуальных сетей в общую сеть требуется привлечение средств сетевого уровня. Он может быть реализован в отдельном маршрутизаторе или в составе программного обеспечения коммутатора, который тогда становится комбинированным устройством - так называемым коммутатором 3-го уровня (см. главу 18). Технология виртуальных сетей долгое время не стандартизировалась, хотя и была реализована в очень широком спектре моделей коммутаторов разных производителей. Положение изменилось после принятия в 1998 году стандарта IEEE 802.1Q, который определяет базовые правила построения виртуальных локальных сетей, не зависящие от протокола канального уровня, поддерживаемого коммутатором.
Создание виртуальных сетей на базе одного коммутатора
При создании виртуальных сетей на основе одного коммутатора обычно используется механизм группирования портов коммутатора (рис. 14.12). При этом каждый порт приписывается той или иной виртуальной сети. Кадр, пришедший от порта, принадлежащего, например, виртуальной сети 1, никогда не будет передан порту, который не принадлежит этой виртуальной сети. Порт можно приписать нескольким виртуальным сетям, хотя на практике так делают редко — пропадает эффект полной изоляции сетей. Создание виртуальных сетей путем группирования портов не требует от администратора большого объема ручной работы — достаточно каждый порт приписать к одной из нескольких заранее поименованных виртуальных сетей. Обычно такая операция выполняется с помощью специальной программы, прилагаемой к коммутатору. Второй способ образования виртуальных сетей основан на группировании МАС-адресов. Каждый МАС-адрес, который изучен коммутатором, приписывается той или иной виртуальной сети. При существовании в сети множества узлов этот способ требует от администратора большого объема ручной работы. Однако при построении виртуальных сетей на основе нескольких коммутаторов он оказывается более гибким, чем группирование портов.
Рис. 14.12. Виртуальные сети, построенные на одном коммутаторе
Создание виртуальных сетей на базе нескольких коммутаторов
Рисунок 14.13 иллюстрирует проблему, возникающую при создании виртуальных сетей на основе нескольких коммутаторов, поддерживающих технику группирования портов.
Рис. 14.13. Построение виртуальных сетей на нескольких коммутаторах с группированием портов Если узлы какой-либо виртуальной сети подключены к разным коммутаторам, то для подключения каждой такой сети на коммутаторах должна быть выделена специальная пара портов. В противном случае, если коммутаторы будут связаны только одной парой портов информация о принадлежности кадра той или иной виртуальной сети при передаче из коммутатора в коммутатор будет утеряна. Таким образом, коммутаторы с группированием портов требуют для своего соединения столько портов, сколько виртуальных сетей они поддерживают. Порты и кабели используются в этом случае очень расточительно. Кроме того, при соединении виртуальных сетей через маршрутизатор для каждой виртуальной сети выделяется отдельный кабель и отдельный порт маршрутизатора, что также приводит к большим накладным расходам.
Поиск по сайту: |