|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Внепроцессорный прямой доступ к памяти
Обмен данными с медленнодействующими периферийными устройствами, например, с посимвольным принтером, организуется по прерываниям, инициирующим передачу каждого слова или байта. Если подпрограмма обслуживания запроса длится около 50 мкс, а скорость передачи не превышает 100 символов/с, то на ввод-вывод расходуется не более 0.5% времени процессора. Существуют устройства, ориентированные на передачу отдельных слов или байтов, но требующие более высокой скорости обмена. К таким устройствам можно отнести измерительную и управляющую аппаратуру, и аппаратуру связи с другими ЭВМ (сетевые средства). Рассмотрим простейший случай, когда коды, поступающие из измерительной аппаратуры, просто накапливаются в оперативной памяти, без всякого анализа и обработки. Скорость работы измерительной установки может достигать нескольких тысяч измерений в секунду и более. Программа обработки прерываний для процессора 8086, обслуживающая этот процесс, будет состоять из следующих команд. Сохранить указательный регистр процессора в стеке. Сохранить регистр - аккумулятор в стеке. Поместить в указательный регистр адрес ячейки памяти. Прочитать данные из порта в аккумулятор. Сохранить содержимое аккумулятора в памяти. Увеличить адрес в указательном регистре. Сохранить адрес в памяти. Восстановить из стека содержимое аккумулятора. Восстановить указательный регистр. Время выполнения такой программы составит приблизительно 50 мкс. Добавим сюда аппаратные издержки механизма прерываний - около 40 мкс. В результате получается, что для пересылки в память одной порции данных затрачивается 90 мкс. Если скорость поступления регистрируемых событий высока, значительная доля процессорного времени (в приведенном примере около 45%, а с учетом постоянно повторяющегося сохранения - восстановления указательного регистра и аккумулятора около 70%) будет расходоваться на непроизводительную работу - организацию переходов на подпрограмму обработки прерываний и обратно. С учетом возможных системных издержек эта цифра может существенно возрасти. В таких условиях сама идея прерываний теряет смысл, т.к. фактически у центрального процессора не остается времени на выполнение основной программы. Более эффективным может оказаться программно - управляемый обмен, если в конкретной ситуации можно смириться с его недостатками - обслуживанием только одного устройства и невозможностью организовать параллельное выполнение основной программы. Аналогичные проблемы возникают при передаче между основной и внешней памятью ЭВМ больших блоков данных. В этом случае производительности (или пропускной способности) процессора в режиме прерываний также недостаточно. Многие устройства внешней памяти (в частности, накопители на магнитных дисках) имеют блочную структуру, т.е. их программная модель представляет собой последовательность логических блоков размером 128 4096 байт. При выполнении операций записи или считывания на таких устройствах необходимо локализовать требуемые данные (дать устройству команду на поиск требуемого блока) и затем произвести пересылку между контроллером устройства и оперативной памятью целого блока. Пусть при пересылке блока из устройства в память отдельные байты, составляющие блок, считываются из порта внешнего устройства и последовательно размещаются в выделенной для этого области памяти. Никакой проверки и обработки байтов не производится. Не производится также никаких проверок во внешнем устройстве. Пусть один из регистров процессора содержит счетчик байтов, подлежащих пересылке, другой содержит указатель на выделенную область памяти. Тогда программа пересылки байтов данных под управлением процессора должна состоять из следующих шагов. 1.Прочитать байт из порта периферийного устройства в регистр процессора. 2.Переслать прочитанный байт из регистра процессора в память. 3.Увеличить указатель данных, чтобы он указывал на следующую ячейку памяти. 4.Уменьшить на 1 счетчик пересланных байтов. 5.Если счетчик не равен нулю, перейти к шагу 1 Фрагмент программы, реализующий эти действия в ЭВМ с процессором 8086 при тактовой частоте 4 МГц, будет состоять из пяти команд, и время выполнения этого фрагмента (соответственно, время пересылки одного байта) составит около 15 мкс. Таким образом, скорость обмена данными составит приблизительно 65 Кбайт/с. Вместе с тем, время доступа к оперативной памяти составляет всего 0.1 - 2 мкс и, следовательно, скорость передачи ограничивается только процессором. Обратим внимание на то, что описанные действия по пересылке блока информации и описанные выше действия по пересылке отдельных слов похожи друг на друга и довольно просты. Они легко могут быть реализованы аппаратно. А если заставить выполнять эти простые действия не сам центральный процессор, а некоторую внешнюю по отношению к процессору схему и организовать канал передачи данных между внешними устройствами и памятью напрямую, минуя процессор? Пусть эта схема сама увеличивает адреса, уменьшает счетчики, формирует управляющие сигналы шины, в общем, является задатчиком на шине. Такой метод обмена данными получил название прямого доступа к памяти (ПДП). Аппаратные средства реализации канала ПДП называются контроллером прямого доступа к памяти. Контроллер может быть реализован в виде отдельного устройства, доступного всем периферийным устройствам (централизованная система ПДП). Возможно также, что каждое внешнее устройство, нуждающееся в реализации ПДП, может иметь в своем контроллере свои средства организации ПДП. Второй случай приводит к узкоспециализированным средствам ПДП, однако позволяет учитывать специфические потребности каждого устройства.
В идеальном случае ПДП совершенно не должен влиять на действия процессора, но для этого потребуется дополнительный, сложный и дорогой тракт доступа к оперативной памяти. Такие средства имеются в дорогих больших ЭВМ, и далее мы рассмотрим их при описании схемы ЭВМ с каналами. Для мини- и микроЭВМ такие средства неприемлемы из-за их высокой стоимости. Поэтому в них используется более простой (но, конечно, менее производительный) прием временного разделения (мультиплексирования) общей системной шины между процессором и контроллером ПДП. В обычных условиях системной шиной “распоряжается” центральный процессор, он является задатчиком при большинстве операций на шине. При подготовке операции обмена с использованием ПДП процессор программирует контроллер ПДП, т.е. “указывает” ему сколько нужно переслать данных и по какому адресу эти данные необходимо поместить. Когда режим ПДП инициируется, задатчиком становится контроллер ПДП. Он “распоряжается” шиной, управляя передачей данных непосредственно между основной и внешней памятью, а действия процессора приостанавливаются, и он отключается от системной шины (рис. 10). Возможны две разновидности ПДП. В режиме идентификации состояния процессора (или “прозрачном” ПДП) контроллер ПДП занимает шину тогда, когда процессор выполняет внутренние действия по преобразованию данных и не обращается к шине. Процессор (или дополнительная схема) идентифицирует такие промежутки времени для контроллера ПДП специальным сигналом, означающим доступность шины. Производительность процессора в таком режиме не уменьшается, (процессор “не замечает” что происходит ПДП, ПДП “прозрачный”), но контроллер ПДП оказывается жестко “привязанным” к схеме процессора, а сами передачи носят нерегулярный характер, что ведет к уменьшению скорости передачи данных.
Аппаратная реализация каналов ПДП определяется особенностями ЭВМ и устройств внешней памяти, но можно сформулировать и общие принципы работы большинства каналов ПДП. На рис.12 показаны основные этапы передачи одного элемента данных в режиме ПДП, называемой также циклом ПДП. Перед началом обмена данными производится программирование контроллера ПДП, в него помещаются адреса памяти и информация о количестве передаваемых данных. Последовательность передачи инициируется сигналом от внешнего устройства, например, накопителя на гибком диске. Контроллер ПДП транслирует этот сигнал в запрос для процессора. Процессор реагирует сигналом подтверждения (разрешения), и отключается от системной шины (но может продолжать внутренние операции). Для осуществления передачи контроллер ПДП выдает на системную шину адрес ячейки памяти, к которой производится обращение для записи или считывания. После этого на шине данных производится собственно передача данных, для чего контроллер ПДП генерирует необходимые управляющие сигналы для памяти и портов ввода - вывода. Затем устройство внешней памяти снимает запрос ПДП, что приводит к снятию соответствующего запроса в процессор, и он возобновляет прерванную работу. Если в ЭВМ имеется несколько устройств, которые могут формировать запросы ПДП, описанная последовательность должна включать в себя этап выборки устройства, инициировавшего запрос ПДП, и блокировки остальных устройств. Если в ЭВМ используется централизованная система ПДП, эту блокировку производит общесистемный контроллер ПДП, если устройство производит ПДП самостоятельно, для блокировки других устройств используется сигнал “занято” на шине управления, который уже упоминался выше. При передаче блока данных последовательность действий при передаче (рис. 12) необходимо дополнить модификацией адреса основной памяти и проверки окончания передачи блока. Для этого в контроллер ПДП загружается адрес основной памяти и число передаваемых байт или слов. После каждой передачи в контроллере ПДП производится увеличение адреса, выдаваемого на шину адреса, и уменьшение счетчика байт или слов. Передача блока завершается, когда счетчик достигает нуля. Подведем некоторые итоги.Несмотря на многообразие задач, решаемых ЭВМ, процессы, происходящие на системной шине, ограничены небольшим числом основных действий. К таким действиям можно отнести операции записи, чтения, прерывания и прямого доступа в память (рис. 13).
Операция чтения позволяет процессору получить необходимую для выполнения программы информацию: из памяти – код очередной команды или данные, из порта внешнего устройства – информацию о состоянии устройства или очередную порцию данных. В процессе операции записи процессор передает в память результат вычислений, а в порт внешнего устройства - управляющие слова или очередную порцию данных (заметим, что при этих операциях задатчиком на шине является процессор и направление передачи определяется относительно процессора: чтение - в процессор, запись - из процессора). С помощью операции прерывания внешнее устройство оповещает процессор о своей готовности к передаче очередной порции данных. Эта операция позволяет внешнему устройству выполнять активную роль и создает предпосылки для обработки внешних событий, регистрируемых ЭВМ. Операция прямого доступа в память служит для массовой передачи данных в память или из нее под управлением не процессора, как обычно, а контроллера прямого доступа к памяти. Использование прямого доступа к памяти требует наличия общесистемного контроллера ПДП, либо существенного усложнения аппаратуры внешних устройств. Однако он может существенно повысить скорость обмена информацией (по сравнению с режимом прерываний в десятки и сотни раз). С помощью перечисленных операций реализуется все многообразие действий, выполняемых ЭВМ. Редактирование текста, трансляция программ, вычисления, управление автоматизированной установкой - все это раскладывается на простейшие операции, прежде всего чтения и записи, а также в случае необходимости прерываний и прямого доступа. Быстродействие ЭВМ, в конечном счете, определяется скоростью выполнения этих элементарных операций. Организационные и схемотехнические решения, закладываемые разработчиками системной шины и способов обмена данными, во многом определяют всю дальнейшую судьбу ЭВМ. И ЕЩЕ О ПРЕРЫВАНИЯХ Описанный выше механизм прерываний, или аппаратные прерывания, является эффективным способом организации взаимодействия процессора с медленными внешними устройствами и начал применяться еще в ЭВМ второго поколения. Однако использование механизма прерываний в современных ЭВМ этим не ограничивается. При работе процессора возможны ситуации, когда по некоторой причине нормальная работа центрального процессора по выполнению программы становится невозможной. Примерами таких ситуаций могут быть деление на ноль, обращение к несуществующей ячейке памяти или к несуществующему порту внешнего устройства, неверное указание операнда команды (например, попытка извлечь квадратный корень из отрицательного числа), попытка выполнить команду с неправильным кодом операции и так далее. Такие ситуации принято называть особыми случаямиили исключениями. Для обработки особых случаев также используется механизм прерываний. Для этого в памяти вместе с обработчиками прерываний от внешних устройств размещаются подпрограммы обработки нештатных ситуаций в процессоре, или обработчики особых случаев. Под особые случаи зарезервирована часть прерываний, возможных в данной ЭВМ. Такие зарезервированные для особых случаев прерывания иногда называют ловушками (trap). При этом, если возникнет некоторый особый случай, источником сигнала прерывания становится сам процессор. Он прерывает выполнение программы и переходит к выполнению подпрограммы обработки нештатной ситуации. Как и в случае аппаратного прерывания действия, выполняемые подпрограммой обработки особого случая, ограничены только программными возможностями процессора. Неверно было бы думать, что нештатные ситуации могут возникать только из-за ошибок в программе или сбоев процессора. Так, например, во многих моделях микро- и миниЭВМ предусмотрена возможность выполнения операций над числами с плавающей точкой особым блоком центрального процессора, который называется арифметическим сопроцессором. Причем отметим, что с целью уменьшения стоимости отдельные ЭВМ данной модели могут не комплектоваться сопроцессором. Пусть, например, в процессоре некоторой ЭВМ отсутствует блок, выполняющий операции над числами с плавающей точкой. Если в программе встретится команда, выполняющая операцию над числами с плавающей точкой, центральный процессор не сможет ее выполнить и сгенерирует прерывание из-за неправильной команды. Подпрограмма обработки этого прерывания может выяснить, какая команда стала причиной прерывания и выполнить операцию над числами с плавающей точкой программным способом. Конечно, программная обработка операций над числами с плавающей точкой будет выполняться существенно медленнее аппаратной обработки. Но с точки зрения пользователя поведение программы не будет зависеть от того, имеется на ЭВМ арифметический сопроцессор или нет. Таким образом, программные прерывания могут позволить имитировать (или эмулировать) отсутствующий сопроцессор. Еще одним примером полезного использования особых случаев может служить отладка программы. Многие процессоры в своем флаговом регистре содержат флаг отладки или трассировки. Этот флаг можно установить или очистить программно. Если флаг трассировки установлен, то после выполнения каждой команды процессор генерирует прерывание особого случая отладки и передает управление специальной программе - отладчику. Отладчик позволяет выполнять программы по шагам, просматривать содержимое регистров процессора, содержимое памяти и т.д. и, тем самым, может существенно облегчить поиск ошибки в сложной программе. Из анализа действий процессора при восприятии прерывания следует, что они очень похожи на действия при вызове подпрограммы. Основное отличие состоит в том, что вызов подпрограммы полностью запрограммирован и предсказуем, а переход к обслуживанию прерывания инициируется внешним сигналом, момент появления которого предсказать невозможно. Тем не менее, внешняя аналогия реакции на прерывание и вызова подпрограммы позволяет считать прерывание аппаратным вызовом подпрограммы. Отметим одно отличие обработки прерывания от вызова подпрограммы. При обращении к подпрограмме необходимо так или иначе указать адрес ячейки памяти, в которой находится первая из команд подпрограммы. В ЭВМ с векторной системой прерываний совершенно необязательно знать, в каком месте памяти находится обработчик прерывания. Для обращения к подпрограмме обработки прерывания достаточно знать только номер элемента вектора прерываний, который содержит адрес обработчика. При этом действия, которые может выполнять подпрограмма обслуживания прерывания, ограничиваются только программными возможностями процессора. Эти свойства позволяют использовать механизм прерываний с еще одной целью. В системе команд многих ЭВМ имеются команды, которые позволяют программно запускать механизм прерываний (команда INT процессора 8086, команды TRAP и EMT процессора PDP - 11, команда SVC в машинах IBM 360). Прерывания, генерируемые командами программы, носят название программных прерываний. По существу, программные прерывания являются просто изощренным способом обращения к подпрограммам. В отличие от “обычных” подпрограмм, программные прерывания позволяют не указывать в команде адрес подпрограммы, а используют аппаратный механизм прерываний. Чаще всего программные прерывания используются в программах для обращения к операционной системе. Помимо более короткой записи (не нужно указывать адрес подпрограммы) использование программных прерываний дает возможность обратиться к подпрограмме, не зная адреса, по которому подпрограмма операционной системы расположена в памяти. Есть еще одна причина применения программных прерываний для обращения к операционной системе. Во многих ЭВМ существуют механизмы защиты памяти. Эти механизмы позволяют защитить операционную систему и другие программы от некорректных или злонамеренных действий пользователя. Защита предполагает запрет доступа к защищаемым участкам памяти и, кроме того, запрет на выполнение некоторых команд пользователем. К числу таких “особых”, привилегированных команд могут относиться команды останова процессора, управление механизмом формирования адреса памяти и т.д. При этом процессор имеет два режима работы: пользовательский, с включенным механизмом защиты и системный, с более широкими возможностями. Из-за наличия ограничений, накладываемых защитой памяти, становится невозможным обратиться к операционной системе “напрямую” как к подпрограмме. Программные прерывания в таких ЭВМ позволяют переключить процессор из пользовательского режима в системный при обращении к операционной системе и обратно после выполнения запроса и тем самым корректно преодолеть ограничения, накладываемые защитой. Суммируя все сказанное о прерываниях, можно сказать, что в современной вычислительной технике различают три основных вида прерываний: аппаратные прерывания, когда сигналом о прерывании внешнее устройство информирует процессор о своей готовности к обмену данными; прерывания обработки особых случаев процессора, когда сам процессор прерывает выполнение программы при возникновении нештатной ситуации; программные прерывания, которые являются способом обращения к подпрограмме и причиной которых является команда программы. РЕЖИМЫ АДРЕСАЦИИ При выполнении программы многим командам требуется доступ к памяти для выборки данных, записи промежуточных и окончательных результатов вычислений. Для любого такого обращения, что уже отмечалось выше, в команде необходимо как-то указать адрес операнда. Поэтому способ формирования адресов операндов в значительной степени определяет способность ЭВМ эффективно осуществлять обработку информации. Объем памяти в ЭВМ постоянно растет и поэтому существенной становится проблема сокращения длины команды. Для преодоления ограничений по длине команды и повышения эффективности обработки информации в ЭВМ имеется множество режимов адресации, которые позволяют a)определять полный адрес памяти меньшим числом бит, тем самым, сокращая длину команды; b)обращаться к ячейкам памяти, адреса которых вычисляются во время выполнения программы, что обеспечивает удобный доступ к данным различной структуры; c)вычислять адрес памяти относительно позиции команды или относительно другого объекта таким образом, что программу можно загружать в любую область памяти без всяких изменений адресов в программе. Рассмотрим основные способы формирования адресов операндов в современных ЭВМ и опишем их основные особенности. Непосредственная адресация.В этом самом простом режиме адресации операнд, подлежащий обработке, размещается непосредственно в самой команде и передается в процессор следом за выборкой кода операции команды. Данный режим адресации применяется тогда, когда операндом является константа, не изменяющаяся во время выполнения программы. Примером применения такого режима адресации может служить загрузка некоторого адреса в регистр процессора. Абсолютная или прямая адресация.Этот режим адресации также достаточно прост. Часть команды является адресом операнда в памяти. Из-за своей простоты этот режим используется во многих ЭВМ. Этот способ адресации достаточно быстр, так как при поиске адреса не требуется никаких дополнительных вычислений. Однако указание полного прямого адреса операнда в команде требует много бит, особенно в ЭВМ с большим объемом адресного пространства. Кроме этого стоит отметить, что если в командах программы указаны полные адреса ее операндов, программа оказывается “жестко привязанной” к конкретным адресам памяти. Это не всегда оправдано, так как часто желательно иметь возможность размещать программы в произвольных участках памяти достаточного размера, к тому же иногда возникает необходимость переместить программу на другое место в памяти. Поэтому для устранения этих недостатков многие ЭВМ используют короткие разновидности прямой адресации (см. ниже относительную адресацию). Такие методы адресации обеспечивают доступ к ограниченной части адресного пространства. Регистровая адресация.В данном режиме операнд находится в одном из регистров процессора и в команде просто указывается номер требуемого регистра. Команда с регистровой адресацией будет достаточно короткой. Кроме того, для выборки операндов процессору не требуется достаточно длительная операция обращения к памяти, поскольку регистры встроены в сам процессор. По этим причинам команды с регистровой адресацией являются самыми “быстрыми” командами. Для увеличения скорости работы программ необходимо стремиться к тому, чтобы часто используемые данные по возможности постоянно находились в регистрах центрального процессора. Регистровая косвенная адресация.В этом режиме адресации регистр или пара регистров процессора содержат адрес операнда, и в команде указывается номер регистра с адресом. Адрес может храниться в специализированном указательном регистре или регистре общего назначения. Этот способ адресации получил очень широкое распространение и по быстродействию приближается к прямой адресации, так как адрес содержится внутри регистра процессора и для его выборки не требуется производить сравнительно длительную операцию обращения к памяти. Загрузка указательных регистров производится либо с использованием непосредственной адресации, либо адрес вычисляется в процессе работы программы, что требуется при просмотре массивов, в процедурах передачи данных и т.д. Адресация с автоуменьшением или автоувеличением.При адресации с автоувеличением адрес операнда вычисляется практически так же, как и при косвенной регистровой адресации. После выборки операнда, адрес, находящийся в регистре процессора автоматически увеличивается на 1 для указания следующего байта, на 2 - для указания поля из двух байт и т.д., при этом размер операнда определяется кодом операции. Отличие адресации с автоуменьшением состоит в том, что перед выборкой операнда содержимое регистра уменьшается на 1, 2 и т.д. в соответствии с размером операнда. Эти два типа адресации позволяют эффективно обрабатывать массивы однотипных данных. Примерами такой адресации являются цепочечная адресация в процессоре 8086 или автоинкрементная и автодекрементная адресация в процессорах СМ. По существу разновидностью этого метода адресации является также стековая адресация. В процессорах СМ использование автоинкрементного режима по отношению к программному счетчику (который обладает там теми же свойствами, что и любой регистр общего назначения) позволяет получить абсолютный режим адресации. Неявная или подразумеваемая адресация.При таком способе адресации в команде явно не указывается адрес одного или нескольких операндов. Операнды в командах с неявной адресацией могут находиться, например, в выделенных для этой команды регистрах процессора, или некоторый выделенный и заранее известный регистр процессора может содержать адрес операнда. Примерами команд с неявной адресацией могут служить многие команды микропроцессоров семейства 8086. Рассмотрим команду организации цикла со счетчиком повторения. В этой команде не указывается явно, какой из регистров содержит счетчик цикла и предполагается, что перед выполнением команды счетчик цикла размещен в регистре - счетчике процессора (регистре CX). Другой пример - команды пересылки блоков данных, которые имеются у многих процессоров (например, REP MOVSBв 8086). Адреса операндов в этой команде явно не указываются и определяются двумя индексными регистрами процессора, куда они должны быть предварительно загружены. При выборке операндов неявно используется адресация с автоувеличением или автоуменьшением. Индексная адресацияудобна для обращения к массивам и таблицам. Для образования исполнительного адреса к адресной Относительная адресация.Основное назначение относительной адресации - преодолеть недостатки прямой адресации, сохранив при этом ее внешнюю простоту и эффективность. При относительной адресации в команде указывается не полный адрес операнда, а сокращенный адрес, обычно называемый смещением. В процессе выполнения команды полный адрес операнда вычисляется путем суммирования смещения, указанного в команде с некоторой величиной, которая называется базовым адресом. Существует два способа расширения адреса, указанного в короткой форме. Первый способ называется самоопределяющейся относительной адресацией.В этом случае смещение, указанное в команде, складывается с адресом самой команды (обычно это текущее содержимое программного счетчика). Такой способ широко используется в командах условной передачи управления многих процессоров. Анализ программ показывает, что команды условной передачи управления чаще всего осуществляют переход на небольшое расстояние (до плюс - минус 100 - 200 байт). Поэтому во многих ЭВМ адрес перехода хранится в виде числа со знаком - короткого (8 бит) смещения целевого адреса относительно адреса команды ветвления (программного счетчика). При выполнении команды смещение просто суммируется с программным счетчиком. Применение относительной адресации в данном случае сокращает длину команды и повышает скорость ее выполнения. Другим примером может служить относительная адресация в процессорах СМ. В командах с относительной адресацией содержится смещение, которое при вычислении адреса операнда суммируется с содержимым программного счетчика. Отметим, что при таком способе адресации не нужно явно указывать, откуда брать базовый адрес (в качестве него всегда выступает программный счетчик). Поэтому этот способ адресации иногда называют неявным базированием. Второй вид относительной адресации называется базовой адресацией.При базовой адресации смещение, указываемое в команде, складывается с базовым адресом, хранящимся в регистре базы процессора (см. рис. 15). Смещение обычно имеет длину меньше, чем длина базового адреса, которая, в свою очередь, должна быть такой, чтобы в качестве базового можно было указать любой из возможных адресов. В качестве регистра базы может использоваться специализированный регистр базы или один из
Разновидностью базовой адресации является сегментная адресация,применяемая в процессорах семейства 8086. Так как процессор 8086 может обрабатывать числа длиной 16 бит, все его адресные регистры являются 16-ти битными. Это обеспечивает доступ к адресному пространству размером 216 = 65536 байт или 64К байт (1К = 1024). Такой блок непосредственно адресуемой памяти называется сегментом. Любой исполнительный адрес формируется в виде суммы базового адреса начала сегмента (он всегда кратен 16) и смещения до нужной ячейки внутри сегмента. Базовый адрес сегмента задается 16-битной величиной, хранимой в сегментном регистре. Физический 20- разрядный адрес памяти (см. рис. 16) получается суммированием содержимого сегментного регистра умноженного на 16 (умножение двоичного числа на 16 эквивалентно сдвигу влево на 4 разряда) и 16-разрядного смещения относительно начала сегмента. Используя 20-разрядные адреса, процессор 8086 может адресовать память объемом 220 = 1024К = 1048576 = 1М байт. Сегменты жестко не привязываются к определенным адресам памяти и могут частично или полностью перекрываться. Термин сегментная адресация введен для того, чтобы подчеркнуть, что размер сегментного регистра хранящего базовый адрес сегмента меньше длины физического адреса, в то время как термин базовая адресация обычно подразумевает, что длина базового регистра равна или больше длины физического адреса памяти. Основными достоинствами относительной адресации и ее разновидностей является, во-первых, то, что длина указываемого в команде адреса меньше длины физического адреса, а это позволяет сократить длину команд, во-вторых, программа с относительной адресацией не зависит от конкретного места ее расположения в памяти. При изменении положения программы в памяти достаточно только правильно настроить регистры, содержащие базовые адреса.
Поиск по сайту: |

 В режиме с пропуском тактов (точнее с “займом” тактов) контроллер ПДП при необходимости сигналом запроса ПДП DMA REQ (Direct Memory Access REQuire) или HOLD заставляет процессор отключиться от системной шины на несколько тактов. После восприятия запроса ПДП процессор завершает выполнение текущего цикла доступа к памяти, приостанавливает свои действия и информирует об этом контроллер ПДП сигналом разрешения прямого доступа к памяти HLDA (HoLD Acnowlege). Задатчиком на системной шине становится контроллер ПДП, он передает между памятью и портом внешнего устройства один элемент данных - байт или слово. Внутренние операции процессора могут совмещаться с передачами ПДП. За одно инциирование ПДП может передаваться и блок данных, например, сектор диска. Таким образом, передачи ПДП осуществляются путем пропуска тактов в выполняемой программе. Иллюстрация данной разновидности ПДП приведена на рис. 11. В отличие запросов на прерывание сигналы запроса на ПДП всегда имеют наивысший приоритет, и эти запросы не могут быть запрещены. При выполнении передачи ПДП содержимое внутренних регистров процессора не модифицируется, поэтому его не нужно запоминать в памяти, а затем восстанавливать как при обработке прерываний. Выполнение программы возобновляется сразу после снятия запроса ПДП. Тем не менее в условиях интенсивных передач ПДП эффективная производительность процессора уменьшается.
В режиме с пропуском тактов (точнее с “займом” тактов) контроллер ПДП при необходимости сигналом запроса ПДП DMA REQ (Direct Memory Access REQuire) или HOLD заставляет процессор отключиться от системной шины на несколько тактов. После восприятия запроса ПДП процессор завершает выполнение текущего цикла доступа к памяти, приостанавливает свои действия и информирует об этом контроллер ПДП сигналом разрешения прямого доступа к памяти HLDA (HoLD Acnowlege). Задатчиком на системной шине становится контроллер ПДП, он передает между памятью и портом внешнего устройства один элемент данных - байт или слово. Внутренние операции процессора могут совмещаться с передачами ПДП. За одно инциирование ПДП может передаваться и блок данных, например, сектор диска. Таким образом, передачи ПДП осуществляются путем пропуска тактов в выполняемой программе. Иллюстрация данной разновидности ПДП приведена на рис. 11. В отличие запросов на прерывание сигналы запроса на ПДП всегда имеют наивысший приоритет, и эти запросы не могут быть запрещены. При выполнении передачи ПДП содержимое внутренних регистров процессора не модифицируется, поэтому его не нужно запоминать в памяти, а затем восстанавливать как при обработке прерываний. Выполнение программы возобновляется сразу после снятия запроса ПДП. Тем не менее в условиях интенсивных передач ПДП эффективная производительность процессора уменьшается.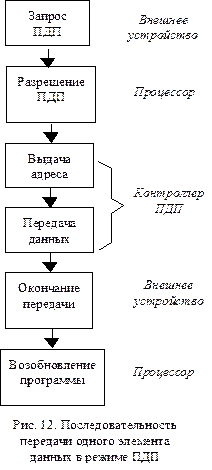

 части команды прибавляется смещение из индексного регистра, называемое индексом (см. рис. 14). Индексный регистр является программно - доступным, и его содержимое может изменяться, что позволяет изменять исполнительные адреса без модификации адресной части команды. В качестве индексных регистров используются один или несколько специализированных регистров, в некоторых ЭВМ их функции выполняют регистры общего назначения. Когда индексный режим используется для доступа к массиву, адрес в команде соответствует базовому адресу массива, а значение индексного регистра - индексу компоненты массива.
части команды прибавляется смещение из индексного регистра, называемое индексом (см. рис. 14). Индексный регистр является программно - доступным, и его содержимое может изменяться, что позволяет изменять исполнительные адреса без модификации адресной части команды. В качестве индексных регистров используются один или несколько специализированных регистров, в некоторых ЭВМ их функции выполняют регистры общего назначения. Когда индексный режим используется для доступа к массиву, адрес в команде соответствует базовому адресу массива, а значение индексного регистра - индексу компоненты массива. регистров общего назначения. В любом случае одна из команд программы должна явно загрузить в регистр базы значение базового адреса и, кроме того, программист должен тем или иным способом указать, какой из регистров выступает в качестве базового. Поэтому этот способ адресации часто называют адресацией с явным базированием.
регистров общего назначения. В любом случае одна из команд программы должна явно загрузить в регистр базы значение базового адреса и, кроме того, программист должен тем или иным способом указать, какой из регистров выступает в качестве базового. Поэтому этот способ адресации часто называют адресацией с явным базированием.