|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Регистры отладки и тестирования. 3 страница
В К10 предсказание переходов (Branch Prediction Unit) существенно улучшено. Во-первых, появился механизм предсказания косвенных переходов, т. е. переходов, которые производятся по указателю, динамически вычисляемому при выполнении кода программы. Во-вторых, предсказание выполняется на основе анализа 12 предыдущих переходов, что повышает точность предсказаний. В-третьих, вдвое (с 12 до 24 элементов) увеличена глубина стека возврата. Как большинство современных х86-процессоров, имеющих внутреннюю RISC-архитектуру, в процессоре К10 внешние х86-команды декодируются во внутренние RISC-инструкции, для чего используется декодер команд. Процесс декодирования состоит из двух этапов. На первом этапе выбранные из кэша L1 блоки инструкций длиной 32 байта (256 бит) помещаются в специальный буфер преддекодирования (Predecode/Pick Buffer), где происходит выделение инструкций из блоков, определение их типов и отсылка в соответствующие каналы декодера. Декодер транслирует х86-инструкции в простейшие машинные команды (микрооперации), называемые micro-ops (µOp). Сами х86-команды могут быть переменной длины, а вот длина микроопераций уже фиксированная. Инструкции х86 разделяются на простые и сложные. Простые инструкции при декодировании представляются с помощью одной-двух микроопераций, а сложные команды – тремя и более микрооперациями. Простые инструкции отсылаются в аппаратный декодер, построенный на логических схемах и называемый Direct Path, а сложные – в микропрограммный декодер, называемый Vector Path. Он содержит память микрокода, в которой хранятся последовательности микроопераций. Аппаратный декодер Direct Path является трехканальным и может декодировать за один такт: три простые инструкции, если каждая из них транслируется в одну микрооперацию; либо одну простую инструкцию, транслируемую в две микрооперации, и одну простую инструкцию, транслируемую в одну микрооперацию; либо две простые инструкции за два такта, если каждая инструкция транслируется в две микрооперации (полторы инструкции за такт). Таким образом, за каждый такт аппаратный декодер выдает три микрооперации. Микропрограммный декодер Vector Path также способен выдавать по три микрооперации за такт при декодировании сложных инструкций. При этом сложные инструкции не могут декодироваться одновременно с простыми, т. е. при работе трехканального аппаратного декодера микропрограммный декодер не используется, а при декодировании сложных инструкций, наоборот, бездействует аппаратный декодер. Микрооперации, полученные в результате декодирования инструкций в декодерах Vector Path и Direct Path поступают в буфер Pack Buffer, где они объединяются в группы по три микрооперации. В том случае, когда за один такт в буфер поступает не три, а одна или две микрооперации (в результате задержек с выбором инструкций), группы заполняются пустыми микрооперациями, но так, чтобы в каждой группе было ровно три микрооперации. Далее группы микроинструкций отправляются на исполнение. Если посмотреть на схему декодера в микроархитектурах К8 и К10, то видимых различий казалось бы нет. Действительно, схема работы декодера осталась без изменений. Разница в данном случае заключается в том, какие инструкции считаются сложными, а какие простыми, а также в том, как декодируются различные инструкции. Так, в микроархитектуре К8 128-битные SSE-инструкции разбиваются на две микрооперации, а в микроархитектуре К10 большинство SSE-инструкций декодируется в аппаратном декодере как одна микрооперация. Кроме того, часть SSE-инструкций, которые в микроархитектуре К8 декодировались через микропрограммный декодер, в микроархитектуре К10 декодируются через аппаратный декодер. Кроме того в микроархитектуре К10 в декодер добавлен специальный блок, называемый Sideband Stack Optimizer. Не вникая в подробности, отметим, что он повышает эффективность декодирования инструкций работы со стеком и, таким образом, позволяет переупорядочивать микрооперации, получаемые в результате декодирования, чтобы они могли выполняться параллельно. После прохождения декодера микрооперации (по три за каждый такт) поступают в блок управления командами, называемый Instruction Control Unit (ICU). Главная задача ICU заключается в диспетчеризации трех микроопераций за такт по функциональным устройствам, т. е. ICU распределяет инструкции в зависимости от их назначения. Для этого используется буфер переупорядочивания Reorder Buffer (ROB), который рассчитан на хранение 72 микроопераций. Из буфера переупорядочивания микрооперации поступают в очереди планировщиков целочисленных (Int Scheduler) и вещественных (FP Mapper) исполнительных устройств в том порядке, в котором они вышли из декодера. Планировщик для работы с вещественными числами образован тремя станциями резервирования (RS), каждая из которых рассчитана на 12 инструкций. Его основная задача заключается в том, чтобы распределять команды по исполнительным блокам по мере их готовности. Просматривая все 36 поступающих инструкций, FP-Renamer переупорядочивает следование команд, строя спекулятивные предположения о дальнейшем ходе программы, чтобы создать несколько полностью независимых друг от друга очередей инструкций, которые можно выполнять параллельно. В микроархитектурах К8 и К10 имеется 3 исполнительных блока для работы с вещественными числами, поэтому FP-планировщик должен формировать по три инструкции за такт, направляя их на исполнительные блоки. Планировщик инструкций для работы с целыми числами (Int Scheduler) образован тремя станциями резервирования, каждая из которых рассчитана на 8 инструкций. Все три станции таким образом образуют планировщик на 24 инструкции. Этот планировщик выполняет те же, функции, что и FP-планировщик. Различие между ними заключается в том, что в процессоре имеется 7 функциональных исполнительных блоков для работы с целыми числами (три устройства ALU, три устройства AGU и одно устройство IMUL). После того, как все микрооперации прошли диспетчеризацию и переупорядочивание, они могут быть выполнены в соответствующих исполнительных устройствах. Блок операций с целыми числами состоит из трех распараллеленных частей. По мере готовности данных планировщик может запускать на исполнение из каждой очереди одну целочисленную операцию в устройстве ALU и одну адресную операцию в устройстве AGU (устройство генерации адреса). Количество одновременных обращений к памяти ограничено двумя. Таким образом, за каждый такт может запускаться на исполнение три целочисленных операции, обрабатываемых в устройствах ALU, и две операции с памятью, обрабатываемых в устройствах AGU. В процессоре К8 после вычисления на AGU адресов обращения к памяти операции загрузки и сохранения направляются в LSU (Load/Store Unit) – устройство загрузки/сохранения. В LSU находятся две очереди LS1 и LS2. Сначала операции загрузки и сохранения попадают в очередь LS1 глубиной 12 элементов. Из очереди LS1 в программном порядке по две операции за такт производятся обращения к кэш-памяти первого уровня. В случае кэш-промаха операции перемещаются во вторую очередь LS2 глубиной 32 элемента, откуда выполняются обращения к кэш-памяти второго уровня и оперативной памяти. В процессоре К10 в LSU были внесены изменения. Теперь в очередь LS1 попадают только операции загрузки, а операции сохранения направляются в очередь LS2. Операции загрузки из LS1 теперь могут исполняться во внеочередном порядке с учетом адресов операций сохранения в очереди LS2. 128-,битные операции сохранения обрабатываются в процессоре К10 как две 64-битные, поэтому в очереди LS2 они занимают по две позиции. Для работы с вещественными числами реализовано три функциональных устройства FPU: FADD – для вещественного сложения, FMUL – для вещественного умножения и FMISC (он же FSTORE) – для команд сохранения в памяти и вспомогательных операций преобразования. В микроархитектурах К8 и К10 планировщик для работы с вещественными числами каждый такт может запускать на исполнение по одной операции в каждом функциональном устройстве FPU. Подобная реализация блока FPU теоретически позволяет выполнять до трех вещественных операций за такт. В микроархитектуре К10 устройства FPU являются 128-битными. Соответственно 128-битные SSE-команды обрабатываются с помощью одной микрооперации, что теоретически увеличивает темп выполнения векторных SSE-команд в два раза, по сравнению с микроархитектурой К8. Одной из основных составляющих микроархитектур К8, К10 является интегрированный в процессор контроллер памяти. В последних процессорах К10 (2010 г.) используется двухканальный контроллер памяти DDR3 – 1333 МГц. Вместе с внесением изменений в архитектуру процессорных ядер инженеры AMD уделили пристальное внимание модернизации интерфейсов, по которым процессоры К10 общаются с внешним миром. В первую очередь необходимо отметить увеличенную скорость шины Hyper Transport (высокоскоростная шина передачи данных между «точка-точка», разработанная AMD), которая в новых CPU приведена в соответствие со спецификацией версии 3.0. В то время, как процессоры Athlon 64 использовали шину Hyper Transport с пропускной способностью 8 GB/сек процессоры Phenom могут обмениваться данными с чипсетом уже на скорости, достигающей 14,4–16,0 GB/сек. При этом спецификация Hyper Transport 3.0 позволяет дополнительно нарастить пропускную способность шины до 20,8 GB/сек. В то же время версии протоколов Hyper Transport 3.0 обратно совместимы, что позволяет без каких бы то ни было проблем использовать процессоры Phenom в старых материнских платах, построенных на наборах логики, поддерживающих только предыдущую версию шины Hyper Transport 2.0. В спецификацию Hyper Transport 3.0 введена поддержка частот 1,8 ГГц, 2,0 ГГц, 2,4 ГГц, 2,6 ГГц; функции «горячего подключения»; динамического изменения частоты шины и энергопотребления и других инновационных решений. Улучшена поддержка многопроцессорных конфигураций, добавлена возможность автоматического конфигурирования для достижения наибольшей производительности. Сравнивая процессоры корпораций AMD и Intel, можно сказать, что первые потеряли свою былую привлекательность для продвинутых пользователей. Компания Intel, разработав успешную микроархитектуру Core, а затем Nehalem, поставила AMD в крайне трудное положение. В результате все процессоры AMD при сопоставлении с продуктами Intel оказываются менее производительными, более прожорливыми в энергетическом плане и совершенно не интересными для оверклокеров. И все это, естественно, не могло не отразиться на рыночной доле, которая на протяжении нескольких последних лет демонстрирует устойчивую тенденцию к уменьшению. Фактически на данный момент AMD удается удерживаться на рынке только за счет ценовой политики: торговые марки Athlon и Phenom уже стали символами дешевизны, но не высокой производительности. Новое поколение процессоров с микроархитектурой К11, кодовое название которых Bulldozer, AMD планирует запустить в 2010 г., а если не получится, то в 2011 г. Эти процессоры по заверениям представителей AMD должны иметь полностью переработанную микроархитектуру по сравнению с предыдущими поколениями AMD К8 и AMD K10. Известно, что процессоры Bulldozer впервые поддержат выполнение набора команд SSE5, а также будут включать модели с интегрированным в кристалл графическим ядром. Bulldozer будет содержать до 16 ядер и обладать совместимостью с модульной процессорной архитектурой M-SPACE. Будет введена поддержка новой версии технологии AMD Direct Connect и четырех каналов Hyper Transport 3.0 на каждый процессор. Возможность работы с памятью DDR3 и технологией расширения памяти AMD G3MX позволит увеличить пропускную способность памяти. Первый процессор из семейства Bulldozer будет, как утверждают представители AMD, четырехъядерным, произведенным по 32-нм технологическому процессу, в нем будет использована технология многопоточности и общие для всех ядер кэш-памяти L2 и L3. 3.5. Современное состояние и перспективы развития микропроцессоров для Unix-серверов 3.5.1. Микропроцессоры семейства Ultra SPARC Руководство Oracle неоднократно заявляло о намерении продолжить развитие Unix-серверов на базе процессоров Ultra SPARC и вложить в эту технологию, доставшуюся ей после недавнего поглощения компании Sun Microsystems, более 1 млрд. долл. Однако до сих пор оно не опубликовало четких планов выпуска будущих поколений SPARC-серверов, а также не стало делать заявлений относительно дальнейшей судьбы известного под кодовым названием Rock многоядерного процессора Ultra SPARC для серверов старшего класса, который первоначально Sun планировала выпустить ещё в 2007 г. Такие неопределённые перспективы SPARC-серверов заставляют корпоративных заказчиков, использующих эти системы для обслуживания критичных для бизнеса приложений, в качестве возможного решения рассматривать миграцию приложений на Unix-системы других производителей, поэтому конкуренты Sun сейчас активно пытаются привлечь на свою сторону заказчиков этой компании, предлагая им серверы на базе новых многоядерных процессоров. Стоит отметить, что хотя позиции Sun на рынке Unix-систем за последние годы существенно ослабли, тем не менее её операционная система Solaris остаётся самым распространённым коммерческим вариантом Unix, что не в последнюю очередь объясняется популярностью варианта этой ОС для серверов на базе процессоров х86 (другие коммерческие варианты Unix не поддерживают архитектуру х86). 3.5.2. Микропроцессор IBM POWER 7 В феврале 2010 г. IBM представила седьмое поколение своих RISC-процессоров POWER, которые используются в её Unix-серверах Power Systems. Если три предыдущие поколения POWER были двухъядерными, то новый POWER7 содержит восемь процессорных ядер, хотя его максимальная частота несколько снизилась по сравнению с шестым поколением (с 5 до 4,1 ГГц). Каждое ядро процессора имеет кэш второго уровня 256 Мбайт, а общий кэш третьего уровня 32 Мб на базе модулей встраиваемой в процессор динамической памяти eDRAM, которая потребляет значительно меньше электроэнергии, чем память SDRAM. Как утверждает IBM, по сравнению с POWER6 новый процессор обеспечивает удвоение мощности и четырехкратное повышение производительности при обслуживании инфраструктуры виртуальных машин. Каждое ядро POWER7 поддерживает четыре потока команд, поэтому один процессор способен выполнять до 32 потоков инструкций. Кроме того, технология Intelligent Threads позволяет в зависимости от специфики приложения выбрать оптимальный режим многопоточности – ядро POWER7 может помимо стандартного четырехпоточного режима работать в двухпоточном или однопоточном режиме. Если при выходе предыдущих поколений POWER перевод на них Unix-серверов IBM начинался с младших либо старших моделей, то на этот раз первыми серверами на базе POWER7 стали Power Systems среднего класса. Серверы Power 770 и 780 поддерживают до 8 процессоров и 64 процессорных ядер, а Power 755 и 750 Express – 4 процессора и 32 ядра. Корпорация IBM обещает до конца 2010 г. выпустить 64-процессорную систему старшего класса на базе POWER7, которая, по-видимому, будет представлять собой модернизированный вариант сервера Power 595 на базе POWER5, и перевести на новый процессор младшие модели Power Systems 520. Пока Power Systems на базе POWER7 может работать только под управлением AIX (варианта Unix от IBM) и не поддерживает Linux, но IBM надеется устранить этот недостаток. 3.5.3. Микропроцессор Intel Itanium 9300 (Tukwila) В феврале 2010 г. корпорация Intel представила новую версию процессора Itanium 9300, известную под кодовым названием Tukwila. Этот процессор с архитектурой EPIC, выход которого первоначально был запланирован на второе полугодие 2008 г., но дважды переносился, будет использоваться в новых Unix-серверах НР Integrity (эти серверы, построенные на основе технологии лезвий Blade System и использующие ОС HP-UX, Hewlett-Packard представила в марте). По сравнению с его предшественником Itanium 9100 число ядер увеличилось с двух до четырех, но в отличие от POWER7 одно ядро Itanium 9300 поддерживает восемь потоков, так что по многопоточности Tukwila не уступает новому RISC-процессору IBM. Помимо перехода на четырехъядерную архитектуру у нового Itanium восьмикратно выросла скорость обмена данными между процессорами за счет применения архитектуры Quick Path Interconnect, а производительность чтения/записи данных в память улучшилась в шесть раз благодаря технологии Scalable Memory Interconnect. В Itanium 9300 расширены функции защиты от ошибок и обеспечения отказоустойчивости – архитектура Advanced Machine Check Architecture обеспечивает координированное устранение ошибок на уровне аппаратуры, микрокода и операционной системы, а функция Dynamic Hard Partitioning позволяет внутри сервера организовать электрически изолированные аппаратные разделы, конфигурацию которых можно менять в онлайновом режиме. Чтобы успокоить потенциальных заказчиков систем на базе нового Itanium, у многих из которых из-за хронического срыва сроков выпуска очередного поколения процессора появились сомнения в дальнейших перспективах EPIC, Intel заявила, что сейчас ведёт разработку двух следующих поколений Itanium, которые будут совместимы с Tukwila как на уровне процессорных разъёмов, так и прикладного ПО. Помимо Hewlett-Packard о планах вывода на рынок серверов на базе нового Itanium уже объявили Bull, Hitachi и NEC, однако Fujitsu и SGI, которые до сих пор выпускали системы на базе процессоров EPIC, пока не подтвердили своей заинтересованности в использовании Tukwila. Но даже если эти две компании свернут производство серверов с Itanium, это мало повлияет на позиции систем с процессорами EPIC на серверном рынке, поскольку более 90 % их продаж приходится на Hewlett-Packard. 3.5.4. Микропроцессор Intel Nehalem EX Весной 2010 г. компания Intel представила новое поколение Intel Xeon, известного как Nehalem EX. В этом восьмиядерном процессоре впервые применены функции отказоустойчивости и поддержки многопроцессорных систем (насчитывающих восемь и более процессорных разъёмов), которые необходимы для серверов, обслуживающих критически важные приложения, в том числе упоминавшиеся выше технологии Advanced Machine Check Architecture, Quick Path Interconnect и Scalable Memory Interconnect. Серверы стандартной архитектуры на базе Nehalem EX, которые должны представить основные вендоры серверов стандартной архитектуры, смогут масштабироваться до 32 процессоров и 256 процессорных ядер, что примерно соответствует мощности SPARC-серверов старшего класса. Поддержка в них ОС Solaris х86 значительно упрощает перенос приложений Solaris по сравнению с миграцией их на ОС AIX или HP-UX. Преимуществом таких серверов в качестве платформы для миграции с SPARC/Solaris будут и более низкие цены, чем IBM Power Systems и HP Integrity, а также свобода выбора их серверного оборудования разных вендоров и возможность стандартизации всей серверной инфраструктуры заказчика, обслуживающей как приложения Solaris, так и Windows. 4. ПРИНЦИПЫ ОРГАНИЗАЦИИ ПОДСИСТЕМЫ ПАМЯТИ ЭВМ И ВС 4.1. Иерархическая структура памяти ЭВМ Памятью ЭВМ называется совокупность устройств, предназначенных для запоминания, хранения и выдачи информации. Основными характеристиками отдельных устройств памяти (запоминающих устройств) являются емкость памяти, быстродействие и стоимость хранения единицы информации (бита). Емкость памяти определяется максимальным количеством данных, которые могут в ней храниться. Ёмкость измеряется в двоичных единицах (битах), машинных словах, но большей частью в байтах (1 байт = 8 бит). Часто емкость памяти выражают через число К = 210 = 1024, например, 1024 бит = Кбит (килобит), 1024 байт = Кбайт (килобайт), 1024 Кбайт = 1 Мбайт (мегабайт), 1024 Мбайт = 1 Гбайт (гигабайт), 1024 Гбайт = 1 Тбайт (терабайт). Быстродействие (задержка) памяти определяется временем доступа и длительностью цикла памяти. Время доступа представляет собой промежуток времени между выдачей запроса на чтение и моментом поступления запрошенного слова из памяти. Длительность цикла памяти определяется минимальным временем между двумя последовательными обращениями к памяти.
Успешное или неуспешное обращение к более высокому уровню называется соответственно «попаданием» (hit) или «промахом» (miss). Попадание есть обращение к объекту в памяти, который найден на более высоком уровне в то время, как промах означает, что он не найден на этом уровне. Доля попаданий или коэффициент попаданий есть доля обращений, найденных на более высоком уровне. Иногда она представляется в процентах. Аналогично для промахов.
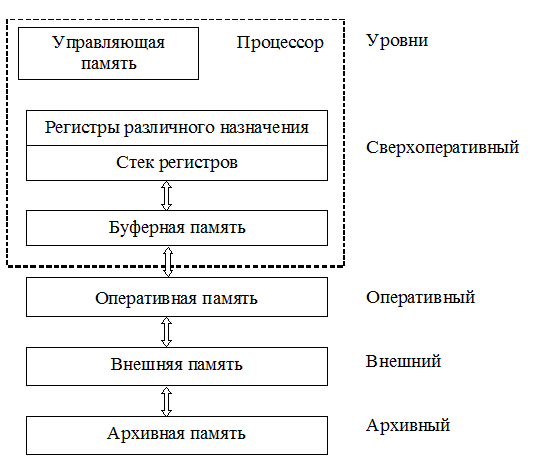
Рис. 4.1. Иерархическая структура памяти Сравнительно небольшая емкость оперативной памяти компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства работают намного медленнее, чем оперативная память. Время обращения за данными для магнитных дисков составляет десятки микросекунд. Для сравнения: цикл обращения к оперативной памяти (ОП) составляет несколько десятков наносекунд. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти. Память современных компьютеров реализуется на микросхемах статических и динамических запоминающих устройств с произвольной выборкой. Микросхемы статических ЗУ (SRAM) имеют меньшее время доступа и не требуют циклов регенерации (восстановления) информации. Микросхемы динамических ЗУ (DRAM) характеризуются большей емкостью и меньшей стоимостью, но требуют схем регенерации и имеют значительно большее время доступа. У статических ЗУ время доступа совпадает с длительностью цикла. По этим причинам в основной памяти практически любого компьютера, проданного после 1975 года, использовались полупроводниковые микросхемы DRAM (SDRAM, DDR SDRAM, RDRAM). Для построения кэш-памяти применяются SRAM. Непрерывный рост производительности ЭВМ проявляется, в первую очередь, в повышении скорости работы процессора. Быстродействие ОП также растет, но все время отстает от быстродействия аппаратных средств процессора в значительной степени потому, что одновременно происходит опережающий рост её емкости, что делает более трудным уменьшение времени цикла работы памяти. Вследствие этого быстродействие ОП часто оказывается недостаточным для обеспечения требуемой производительности ЭВМ. Это проявляется в несоответствии пропускных способностей процессора и ОП. Возникающая проблема выравнивания их пропускных способностей решается путем использования сверхоперативной буферной памяти небольшой емкости и повышенного быстродействия, хранящей команды и данные, относящиеся к обрабатываемому участку программы. При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память (СБП). Последующие обращения производятся к копии блока данных, находящейся в СБП. Поскольку время выборки из сверхоперативной буферной памяти tСБУ (несколько наносекунд) много меньше времени выборки из оперативной памяти tОП, введение в структуру памяти СБП приводит к уменьшению эквивалентного времени обращения tЭ по сравнению с tОП: tЭ = tСБП + atОП , где a = (1 – q) и q – вероятность нахождения блока в СБП в момент обращения к нему, т. е. вероятность «попадания». Очевидно, что при высокой вероятности попадания эквивалентное время обращения приближается к времени обращения к СБП. В основе такой организации взаимодействия ОП и СБП лежит принцип локальности обращений, согласно которому при выполнении какой-либо программы (практически для всех классов задач) большая часть обращений в пределах некоторого интервала времени приходится на ограниченную область адресного пространства ОП, причем обращения к командам и элементам данных этой области производятся многократно. Это позволяет копии наиболее часто используемых участков программ и некоторых данных загрузить в СБП и таким образом обеспечить высокую вероятность попадания q. Высокая эффективность применения СБП достигается при q і 0,9. Буферная память не является программно доступной. Это значит, что она влияет только на производительность ЭВМ, но не должна оказывать влияния на программирование прикладных задач. Поэтому она получила название кэш-памяти (в переводе с английского – тайник). В современных компьютерах применяют многоуровневую кэш-память (до трех уровней), которая еще больше способствует производительности ЭВМ. Как правило, на первом уровне используются раздельные кэш-памяти для команд и данных, а на других уровнях данные и команды хранятся в одних и тех же кэш-памятях. 4.2. Организация стека регистров Регистровая структура процессора была рассмотрена в разделе 3. Стек регистров, реализующий безадресное задание операндов, является эффективным элементом архитектуры ЭВМ. Стек представляет собой группу последовательно пронумерованных регистров, снабжённых указателем стека, в котором автоматически при записи устанавливается номер первого свободного регистра стека (вершина стека). Существует два основных способа организации стека регистров: LIFO (Last-in First-Out) – последний пришёл – первый ушёл; FIFO (First-in First-Out) – первый пришёл – первый ушёл. Механизм стековой адресации для первого способа поясняется на рис. 4.2. Для реализации адресации по способу LIFO используется счётчик адреса СЧА, который перед началом работы устанавливается в состояние ноль, и память (стек) считается пустой. Состояние СЧА определяет адрес первой свободной ячейки. Слово загружается в стек с входной шины Х в момент поступления сигнала записи ЗП. По сигналу ЗП слово Х записывается в регистр P[СЧА], номер которого определяется текущим состоянием счётчика адреса, после чего с задержкой D, достаточной для выполнения микрооперации записи P[СЧА]:=Х, состояние счетчика увеличивается на единицу. Таким образом, при последовательной загрузке слова А, В и С размещаются в регистрах с адресами P[S], P[S + 1] и P[S + 2], где S – состояние счётчика на момент начала загрузки. Операция чтения слова из ЗУ инициируется сигналом ЧТ, при поступлении которого состояние счётчика уменьшается на единицу, после чего на выходную шину Y поступает слово, записанное в стек последним. Если слова загружались в стек в порядке А, В, С, то они могут быть прочитаны только в обратном порядке С, В, А.

Рис. 4.2. Механизм стековой адресации по способу LIFO 4.3. Способы организации кэш-памяти Общие сведения В функциональном отношении кэш-память рассматривается как буферное ЗУ, размещённое между основной (оперативной) памятью и процессором. Основное назначение кэш-памяти – кратковременное хранение и выдача активной информации процессору, что сокращает число обращений к основной памяти, скорость работы которой меньше, чем кэш-памяти. За единицу информации при обмене между основной памятью и кэш-памятью принята строка (линейка), причём под строкой понимается набор слов, выбираемый из оперативной памяти при одном к ней обращении. Хранимая в оперативной памяти информация представляется, таким образом, совокупностью строк с последовательными адресами. В любой момент времени строки в кэш-памяти представляют собой копии строк из некоторого их набора в ОП, однако расположены они необязательно в такой же последовательности, как в ОП. Построение кэш-памяти может осуществляться по различным принципам, которые будут рассмотрены ниже. Но общим для всех способов построения кэш-памяти является использование так называемых адресных тегов. Адресный тег – это расширенный адрес, который объединяет адреса всех слов, принадлежащих данной строке. Он указывает, какую строку в ОП представляет данная строка в кэш-памяти.
Поиск по сайту: |