|
|
|
Архитектура Астрономия Аудит Биология Ботаника Бухгалтерский учёт Войное дело Генетика География Геология Дизайн Искусство История Кино Кулинария Культура Литература Математика Медицина Металлургия Мифология Музыка Психология Религия Спорт Строительство Техника Транспорт Туризм Усадьба Физика Фотография Химия Экология Электричество Электроника Энергетика |
Что называть «слишком много», а что - «слишком мало»? ⇐ ПредыдущаяСтр 2 из 2
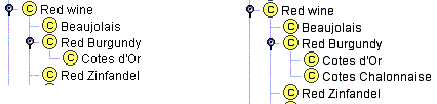
Не существует жестких правил относительно того, сколько прямых подклассов должен иметь класс. Тем не менее, во многих онтологиях с четкой структурой имеется от двух до дюжины прямых подклассов. Отсюда два руководящих принципа: Если класс имеет только один прямой подкласс, то, возможно, при моделировании допущена ошибка или онтология неполная. Если у данного класса есть более дюжины подклассов, то, возможно, необходимы дополнительные промежуточные категории. Первое правило похоже на правило набора текста, которое гласит, что у маркированного текста никогда не должна быть лишь одна маркированная точка. Например, большинство красных бургундских вин – это вина Cфtes d’Or. Предположим, что мы хотели представить только этот основной тип бургундских вин. Мы могли создать класс Red Burgundy и затем единственный подкласс Cotes d’Or (рис. 6а). Тем не менее, если в нашем представлении красные бургундские вина и вина Cфtes d’Or, по существу, эквивалентны (все красные бургундские вина являются винами Cфtes d’Or и все вина Cфtes d’Or – это красные бургундские вина), то нет необходимости создавать класс Cotes d’Or, и он не добавит в представление новую информацию. Если бы нам нужно было включить вина Cфtes Chalonnaise (более дешевые бургундские вина из области к югу от Cфtes d’Or), то мы бы создали два подкласса класса Burgundy: Cotes d’Or и Cotes Chalonnaise (рис. 6б).
Рис. 6. Подклассы класса Red Burgundy. Наличие у класса только одного подкласса указывает на ошибку при моделировании.
Теперь предположим, что мы перечислили все вина как прямые подклассы класса Вино. Тогда этот список будет включать такие более общие сорта, как Beaujolais и Bordeaux, так же как и более конкретные вина, как Paulliac и Margaux (рис. 7а). У класса Вино слишком много прямых подклассов и, действительно, для того чтобы онтология отражала различные сорта вин более четко, Medoc должно быть подклассом Bordeaux, а Cotes d’Or должно быть подклассом Burgundy. Кроме того, наличие таких промежуточных категорий как Красное вино и Белое Вино также будет отражать ту понятийную модель предметной области вин, которая есть у многих людей (рис. 7б). Тем не менее, если не существует естественных классов для группировки понятий в длинный список узлов-братьев, то не нужно создавать искусственные классы – оставьте все, как есть. В конце концов, онтология – это отражение реального мира, и если в действительности категоризации нет, то онтология должна это отражать.
Рис. 7. Категоризация вин. Простое перечисление всех вин против нескольких уровней категоризации.
4.3. Множественное наследование. Большинство систем представления знаний позволяют осуществлять множественное наследование в иерархии классов: класс может быть подклассом нескольких классов. Предположим, что мы хотим создать отдельный класс десертных вин - класс Десертное вино. Вино Port является и красным, и десертным вином [4]. Следовательно, мы определяем, что у класса Port есть 2 надкласса: Красное вино и Десертное вино. Все экземпляры класса Port будут экземплярами как класса Красное вино, так и класса Десертное вино. Класс Port унаследует слоты и фацеты от обоих родителей. Таким образом, он унаследует значение СЛАДКОЕ из слота Сахар класса Десертное вино, а также слот уровень танина и значение слота цвета класса Красное вино.
4.4. Когда вводить (или не вводить) новый класс Одно из самых сложных решений, которое нужно принять во время моделирования, - это определить, когда ввести новый класс или когда сформулировать различие с помощью разных значений свойств. Сложно ориентироваться как в иерархии с очень большой степенью вложенности и множеством посторонних классов, так и в очень плоской иерархии, где очень мало классов, но в их слотах закодировано слишком много информации. Найти подходящий баланс нелегко. Существует несколько практических способов определения того, когда в иерархию следует ввести новые классы: Обычно подклассы класса (1) имеют дополнительные свойства, которых нет у надкласса, или (2) ограничения, отличные от тех, которые есть у надкласса, или (3) состоят в других отношениях, нежели надклассы. У красных вин разные уровни танина, тогда как это свойство не используется для описания вин в общем. Слот сахар класса Десертное вино имеет значение СЛАДКОЕ, тогда как для надкласса класса Десертное вино это не так. Вина Pinot Noir могут хорошо сочетаться с морскими продуктами, тогда как другие красные вина – нет. Другими словами, мы обычно вводим в иерархию новый класс только тогда, когда мы можем сказать про этот класс что-то такое, чего мы не можем сказать о надклассе. На практике к каждому подклассу нужно добавить новые слоты или определить у него новые значения слотов и переопределить некоторые фацеты наследованных слотов. Однако иногда может быть полезно создать новые классы, даже если они не вводят никаких новых свойств. Классы в иерархиях терминов не обязаны новые свойства. Например, некоторые онтологии включают большие иерархии ссылок обычных терминов, используемых в предметной области. К примеру, онтология, которая лежит в основе электронной системы записи медицинской информации, может включать классификацию различных болезней. Эта классификация может быть как раз такой - иерархией терминов, без свойств (или с одним и тем же набором свойств). В этом случае по-прежнему полезно организовать термины в иерархию, а не в линейный список, потому что она (1) облегчит изучение и навигацию и (2) позволит врачу легко выбрать подходящий уровень общности термина. Другая причина введения новых классов без новых свойств – это моделирование понятий, среди которых эксперты в предметной области обычно проводят разграничение, даже несмотря на то, что мы могли принять решение не моделировать само разграничение. Так как мы используем онтологии для содействия коммуникации между экспертами в предметной области, а также между экспертами и системами, основанными на знаниях, то в онтологии мы бы хотели отразить точку зрения эксперта на предметную область. В конце концов, нам не следует создавать подклассы класса для каждого дополнительного ограничения. К примеру, мы ввели классы Красное вино, Белое вино и Розовое вино, так как это разделение является естественным в мире вин. Мы не ввели классы для изысканного вина, для вин с умеренным вкусом и т.д. Когда мы определяем иерархию классов, наша цель – добиться равновесия между созданием классов, которые полезны для организации классов, и созданием слишком большого числа классов.
4.5. Новый класс или значение свойства? При моделировании предметной области нам часто нужно решать, моделировать ли определенное разграничение (такое как белое, красное или розовое вино) как значение свойства или как набор классов, что опять же зависит от масштаба предметной области и от решаемой задачи. Создать ли нам класс Белое вино или просто создать класс Вино и ввести различные значения слота цвет? Ответ всегда зависит от того масштаба, который мы определили для онтологии. Насколько важно понятие Белое вино в нашей предметной области? Если важность вин в предметной области незначительна и то, белое это вино или нет, не особо влияет на его отношения с другими объектами, то нам не нужно вводить отдельный класс белых вин. Для модели предметной области, используемой на предприятии, где производятся винные этикетки, правила для этикеток вин различных цветов одни и те же и разделение не столь важно. И наоборот, для представления вина, еды и их подходящих сочетаний, красное вино сильно отличается от белого: оно сочетается с другой едой, у него другие свойства и т.д. Также, цвет вина важен для базы знаний по винам, которую мы можем использовать для определения последовательности дегустации вин. Поэтому мы создаем отдельный класс Белое вино. Если понятия с разными значениями слота становятся ограничениями для различных слотов в других классах, то для разделения нам следует создать новый класс. В противном случае разделение представляется в значении слота. Подобным образом, в нашей онтологии вин есть такие классы как Красное Merlot и Белое Merlot, а не единый класс для всех вин Merlot: красные Merlot и белые Merlot – это действительно разные вина (сделанные из одного винограда), и если мы разрабатываем подробную онтологию, то это разделение представляет важность. Если в предметной области разграничение представляет важность и объекты с другими значениями разграничения мы считаем другими типами объектов, то для осуществления разграничения нам нужно создать новый класс. При принятии решения о том, вводить новый класс или нет, также может быть полезно рассмотреть потенциальные отдельные экземпляры класса. Класс, к которому принадлежит отдельный экземпляр, не должен часто меняться. Обычно, когда для определения различий между классами мы используем внешние, а не внутренние свойства понятий, экземпляры этих классов должны часто будут перемещаться из одного класса в другой. Например, Охлажденное вино не должно являться классом в онтологии, описывающей бутылки вин в ресторане. Свойство охлажденное должно быть просто атрибутом вина в бутылке, так как экземпляр класса Охлажденное вино может легко перестать быть экземпляром этого класса, а затем снова стать его экземпляром. Обычно числа, цвета, местоположения являются значениями слотов и не приводят к созданию новых классов. Тем не менее, вино – особое исключение, так как цвет вина имеет первостепенную важность для его описания. В качестве другого примера рассмотрим онтологию человеческой анатомии. Когда мы представляем ребра, создаем ли мы класс для «1-го левого ребра», потом класс для «2-го левого ребра» и т.д.? Или у нас есть класс Ребро со слотами для последовательности и стороны (левое - правое)?[5] Если информация о каждом из ребер, которые мы представляем в онтологии, существенно отличается, то нам, действительно, нужно создать класс для каждого ребра. То есть, если мы хотим подробно представить информацию о смежности и положении (которые различны для всех ребер), а также особые функции, которые выполняет каждое ребро, и какие органы оно защищает, то нам нужно создать классы. Если мы моделируем анатомию на чуть более низком уровне обобщения и для наших потенциальных приложений все ребра очень похожи (мы говорим всего лишь о том, какое ребро сломано, судя по рентгеновскому снимку, безотносительно к другим частям тела), то нам потребуется упростить иерархию и оставить только класс Ребро с двумя слотами: сторона и порядковый номер.
4. 6. Экземпляр или класс? Определение того, чем является определенное понятие - классом в онтологии или отдельным экземпляром - зависит от потенциальных приложений онтологии. Определение того, где заканчиваются классы и начинаются отдельные экземпляры, начинается с определения нужной глубины детализации в представлении. Глубина детализации, в свою очередь, определяется потенциальным приложением онтологии. Другими словами, какие самые конкретные элементы будут представлены в базе знаний? Если возвратиться к вопросам для проверки компетентности, которые мы определили в Шаге 1 Главы 3, самые конкретные понятия, которые будут ответами на эти вопросы, лучше всего подойдут на роль индивидных концептов в базе знаний. Отдельные экземпляры - самые конкретные понятия, представленные в базе знаний. Например, если мы собираемся говорить только о подборе сочетаний вина и еды, то нас не будут интересовать конкретные материальные бутылки вина. Поэтому такие термины как Sterling Vineyards Merlot, вероятно, будут самыми конкретными используемыми нами терминами. Следовательно, Sterling Vineyards Merlot будет экземпляром в базе знаний. С другой стороны, если бы мы хотели поддерживать в ресторане ассортимент вин в дополнение к базе знаний хороших сочетаний «вино-еда», то отдельными экземплярами в нашей базе знаний могли бы стать отдельные бутылки каждого вина. Аналогично, если бы мы хотели записать различные качества для каждого конкретного урожая Sterling Vineyards Merlot, то экземпляром в базе знаний стал бы конкретный урожай вина, а Sterling Vineyards Merlot стал бы классом, содержащим экземпляры всех его урожаев. Другое правило может «переместить» некоторые отдельные экземпляры в разряд классов: Если понятия формируют естественную иерархию, то нам нужно представить их, как классы. Рассмотрим винные области. В начале мы можем определить основные винные регионы, такие как Франция, США, Германия и т.д. как классы, а конкретные винные области внутри этих регионов как экземпляры. Например, область Bourgogne – это экземпляр класса регион Франция. Однако мы бы также хотели отметить, что область Cotes d’Or – это область Bourgogne. Поэтому область Bourgogne должна быть классом (чтобы иметь подклассы или экземпляры). Однако представление области Bourgogne как класса, а области Cotes d’Or как экземпляра области Bourgogne кажется произвольным: очень сложно четко разграничить, какие области являются классами, а какие – экземплярами. Поэтому мы определяем все винные области как классы. Protege-2000 дает возможность пользователю определить некоторые классы как Абстрактные, показывая, что у класса не может быть прямых экземпляров. В нашем случае, все классы областей являются абстрактными (рис. 8).
Рис. 8. Иерархия винных областей. Иконка «А» рядом с именами классов указывает на то, что это абстрактные классы и у них не может быть прямых экземпляров.
Так же иерархия классов была бы неправильной, если бы мы пропустили в имени класса слово «область». Мы не можем сказать, что класс Alsace – это подкласс класса Франция: Alsace – это не разновидность Франции. Тем не менее, область Alsace – разновидность региона Франция. В виде иерархии можно представить только классы – в системах представления знаний нет категории «подэкземпляр». Поэтому, если среди терминов существует естественная иерархия, такая как в иерархиях терминов в Разделе 4.2, то нам нужно охарактеризовать эти термины как классы, даже если они могут и не иметь своих экземпляров.
4.7. Ограничение масштаба В качестве последнего замечания по составлению иерархии классов, следующий набор правил всегда поможет при ответе на вопрос, закончено ли определение онтологии: Онтология не должна содержать всю возможную информацию о предметной области: вам не нужно конкретизировать или обобщать больше, чем вам нужно для вашего приложения (не более 1 дополнительного уровня в каждую сторону). Для нашего примера с вином и едой нам не требуется знать, из какой бумаги делаются этикетки, или как готовятся блюда из креветок. Также онтология не должна содержать все возможные свойства классов и различия между классами в иерархии. В нашу онтологию мы, естественно, не включаем все свойства, которые могли бы иметь вино или еда. В нашей онтологии мы представили самые значимые свойства классов элементов. Даже несмотря на то, что в книгах по винам можно узнать о размере виноградин, мы не включили эту информацию. Так же, в нашу систему мы не включили все возможные отношения между всеми терминами. К примеру, мы не включаем в онтологию такие отношения, как любимое вино или любимая еда, просто для того, чтобы сделать более полное представление обо всех взаимосвязях между определенными нами терминами более полным. Последние правила также применимы для установления отношений между понятиями, которые мы уже включили в онтологию. Рассмотрим онтологию, описывающую биологические эксперименты. Эта онтология, вероятно, будет содержать понятие Биологические организмы. Она также будет содержать понятие Экспериментатор (включающее имя, место работы и т.д.), который проводит эксперимент. Верно то, что экспериментатор как человек также является биологическим организмом. Тем не менее, мы, наверное, не должны отражать эту особенность в онтологии: в целях этого представления экспериментатор не является биологическим организмом, и мы, наверное, никогда не будем проводить эксперименты на самих экспериментаторах. Если бы в онтологии мы делали представление всего того, что мы можем сказать о классах, то Экспериментатор бы стал подклассом класса Биологический организм. Однако нет необходимости включать это знание для возможных приложений. Фактически, включение этой дополнительной классификации существующих классов действительно мешает: теперь у экземпляра Экспериментатора будут слоты для веса, возраста, вида и других данных, которые относятся к биологическому организму, но совершенно неуместны в контексте описания эксперимента. Тем не менее, для пользователей, которые будут иметь дело с этой онтологией и которые могут не знать о задуманном нами приложении, нам нужно отразить это проектное решение в документации.
4.8. Дизъюнктивные подклассы Многие системы позволяют нам явным образом задать, что несколько классов являются дизъюнктивными. Классы дизъюнктивные, если у них не может быть общих экземпляров. Например, в нашей онтологии классы Десертное вино и Белое вино не являются дизъюнктивными: существует множество вин, являющих экземплярами обоих классов. Одним из таких примеров является Rothermel Trochenbierenauslese Riesling, экземпляр класса Сладкое Riesling. В то же время, классы Красное вино и Белое вино дизъюнктивны: ни одно вино не может быть одновременно и белым, и красным. Определение классов как дизъюнктивных позволяет системе лучше проверять правильность онтологии. Если мы объявим классы Красное вино и Белое вино дизъюнктивными и затем создадим класс, который будет подклассом и Riesling (подкласс Белого вина) и Port (подкласс Красного вина), то система может показать, что имеется ошибка в моделировании.
5. Определение свойств – боле подробно В этой главе мы затронем еще несколько деталей, которые нужно иметь при определении слотов в онтологии (Шаги 5 и 6 в Главе 3). В основном, мы обсуждаем обратные слоты и значения слота по умолчанию.
5.1. Обратные слоты Значение слота может зависеть от значения другого слота. Например, если вино было произведено на винном заводе, то винный завод производит это вино. Эти два отношения, производитель и производит, называются обратными отношениями. Излишне хранить информацию и о том, и о другом. Когда мы знаем, что вино производится на винном заводе, то приложение, которое использует базу знаний, всегда может вывести значение для обратного отношения: винный завод производит вино. Тем не менее, с точки зрения приобретения знаний удобно иметь оба блока информации доступными в явном виде. Этот подход позволяет пользователям указать вино в одном случае и винный завод в другом. После это система приобретения знаний может автоматически заполнить значение для обратного отношения, обеспечивая согласованность базы знаний. В нашем примере есть пара обратных слотов: слот производитель класса Вино и слот производит класса Винный завод. Когда пользователь создает экземпляр класса Вино и заполняет значение слота производитель, система автоматически добавляет вновь созданный экземпляр к слоту производит соответствующего экземпляра класса Винный завод. Например, когда мы говорим, что Sterling Merlot производится на заводе Sterling Vineyard, система автоматически добавляет Sterling Merlot к списку вин, которые производит завод Sterling Vineyard (рис. 9).
Рис. 9. Экземпляры с обратными слотами. Слот производит класса Винный завод является обратным для слота производитель класса Вино. Заполнение одного из слотов приводит к автоматическому обновлению другого.
5.2. Значения по умолчанию Многие фреймовые системы позволяют определить для слотов значения по умолчанию. Если значение определенного слота одинаково для большинства экземпляров класса, то мы можем определить это значение как значение слота по умолчанию. Затем, когда создается каждый экземпляр класса, имеющего этот слот, система автоматически заполняет значение по умолчанию. После этого мы можем изменить это значение на любое другое, которое позволят фацеты. То есть, значения по умолчанию созданы для удобства: в любом случае они не накладывают какие-либо ограничения на модель или никак ее не меняют. Например, если большинство вин, о которых мы собираемся говорить, являются крепкими, то значение крепости вина мы можем сделать «крепкое» по умолчанию. Тогда все вина, которые мы определяем, будут крепкими, если мы не укажем иное. Обратите внимание, что это отличается от значений слота. Значения слота не могут быть изменены. Например, мы можем сказать, что слот сахар класса Десертное вино имеет значение «СЛАДКОЕ». Тогда у всех подклассов и экземпляров класса Десертное вино значение слота сахар будет «СЛАДКОЕ». Для всех подклассов или экземпляров этого класса это значение изменить нельзя.
Об именах Определение единых правил присваивания имен понятиям в онтологии, а затем строгое соблюдение этих правил не только делает онтологию более простой для понимания, но также помогает избежать некоторых общих ошибок при моделировании. Существует много вариантов присваивания имен понятиям. Обычно нет особой причины для выбора того или иного варианта. Тем не менее, нам нужно Определить единые правила присваивания имен классам и слотам и придерживаться их. На выбор правил присваивания имен влияют следующие особенности системы представления знаний: - Имеет ли система одно и то же пространство имен классов, слотов и экземпляров? То есть, позволяет ли система иметь класс и слот с одинаковым именем (как, например, класс винный завод и слот винный завод)? - Различает ли система регистр букв? То есть, считает ли система разными имена, которые отличаются только регистром (как Винный завод и винный завод)? - Какие разделители в именах позволяет использовать данная система? То есть, могут ли имена содержать пробелы, запятые, звездочки и т.д.? К примеру, Protеgе-2000 имеет единое пространство имен для всех своих фреймов. Она различает регистр букв. Таким образом, у нас не может быть класса винный завод и слота винный завод. Однако у нас может быть класс Винный завод (не прописные буквы) и слот винный завод. С другой стороны, CLASSIC не различает регистр букв и имеет разные пространства имен для классов, слотов и индивидных концептов. Таким образом, с точки зрения системы, мы можем с легкостью присвоить имя Винный завод и классу, и слоту.
6.1. Заглавные буквы и разделители Во-первых, мы можем значительно улучшить читаемость онтологии, если мы все время будем писать названия понятий с большой буквы. Например, общепринято начинать имена классов с большой буквы, а имена слотов – с маленькой (предполагая, что система различает регистр букв). Когда имя понятия содержит больше одного слова (как в Винный завод), нам нужно разделить слова. Вот возможные варианты: - Использовать пробел: Винный завод (многие системы, включая Protеgе, позволяют использовать пробелы в именах понятий). - Соединить слова вместе и каждое слово написать с большой буквы: ВинныйЗавод. - Использовать в имени подчеркивание или тире, или другой разделитель: Винный_Завод, Винный_завод, Винный-Завод, Винный-завод (если вы используете разделитель, вам также нужно решить, писать каждое слово с большой буквы или нет). Если система представления знаний позволяет использовать пробелы в именах, то для многих разработчиков онтологий пробелы могут быть самым естественным решением. Однако важно учитывать другие системы, с которыми может взаимодействовать ваша система. Если в этих системах не используются пробелы или ваше средство представления не очень хорошо обрабатывает пробелы, то может быть лучше использовать другой метод.
6.2. Единственное или множественное число Имя класса представляет набор объектов. Например, класс Вино в действительности представляет все вина. Поэтому для многих разработчиков было бы естественнее дать классу имя Вина, а не Вино. Ни один из вариантов не лучше и не хуже другого (хотя на практике для имен классов чаще используется единственное число). Тем не менее, каким бы ни был выбор, его следует придерживаться на протяжении всей онтологии. Некоторые системы даже требуют от своих пользователей заранее объявить, какое число (единственное или множественное) они будут использовать в именах классов, и не дают им отклоняться от своего выбора. Использование все время одной и той же формы также предотвращает такие ошибки разработчика при моделировании, как создание класса Вина, а затем создание класса Вино как его подкласса (см. Раздел 4.1).
6.3. Договоренность в отношении использования префиксов и суффиксов Некоторые методологии по базам знаний советуют придерживаться договоренности в отношении использования префиксов и суффиксов в именах для того, чтобы различать классы и слоты. Существует две распространенных традиции: добавлять к именам слотов has-[6] или предлог –of[7]. Таким образом, наши слоты меняются на его-производитель и его-винный_завод, если мы выберем использование его-. Слоты меняются на maker-of и winery-of[8], если мы выберем использование of-. Этот подход позволяет любому, кто посмотрит на термин, сразу же определить, что это: класс или слот. Однако имена терминов становятся немного длиннее.
6.4. Другие соображения по присваиванию имен Еще несколько моментов, которые нужно иметь в виду при определении правил присваивания имен: - Не добавляйте к именам понятий такие строки как «класс», «свойство», «слот» и т.д. Из контекста всегда ясно, что это, к примеру, класс или слот. В дополнение к тому, что для классов и слотов вы используете разные правила присваивания имен (скажем, пишете их с большой и с маленькой буквы соответственно), само имя будет показывать, чем является это понятие. - Обычно лучше не сокращать имена понятий (то есть, используйте Cabernet Sauvignon, а не Cab). - Имя надкласса должно входить или во все имена прямых подклассов, или ни в одно из них. Например, если мы создаем два подкласса класса Вино для представления красных и белых вин, то подклассы должны называться или Красное Вино и Белое Вино, или Красное и Белое, но не Красное Вино и Белое.
7. Другие ресурсы В наших примерах в качестве среды разработки онтологий мы использовали Protege-2000. Duineveld с коллегами (Duineveld et al. 2000) описывает и сравнивает ряд других сред для разработки онтологий. Мы постарались рассказать о самом основном о разработке онтологий и не коснулись многих углубленных тем или альтернативных методологий разработки онтологий. Gуmez-Pйrez (Gуmez-Pйrez 1998) и Uschold (Uschold and Gruninger 1996) представляют альтернативные методологии разработки онтологий. В руководстве по Ontolingua (Farquhar 1997) говорится о некоторых формальных аспектах моделирования знаний. В настоящее время исследователи придают особое значение не только разработке онтологий, но также и анализу онтологий. Чем больше онтологий будет создаваться и повторно использоваться, тем больше будет инструментальных средств для анализа онтологий. К примеру, Chimaera (McGuinness et al. 2000) предоставляет диагностические инструментальные средства для анализа онтологий. Анализ, который осуществляет Chimaera, включает как проверку логической верности онтологии, так и диагностику типичных ошибок при проектировании онтологий. Разработчик онтологий может провести диагностику разрабатываемой онтологии с помощью Chimaera, чтобы определить соответствие общим способам моделирования онтологий.
8. Заключение В этом руководстве мы описали методологию разработки онтологии для декларативных фреймовых систем. Мы перечислили шаги при разработке онтологии и затронули сложные вопросы определения иерархий классов и свойств классов и экземпляров. Тем не менее, помимо всех правил и советов, следует помнить одну из важнейших вещей: для любой предметной области не существует единственно правильной онтологии. Проектирование онтологии – это творческий процесс и две онтологии, разработанные разными людьми, никогда не будут одинаковыми. Потенциальные приложения онтологии, а также понимание разработчиком предметной области и его точка зрения на нее будут, несомненно, влиять на принятие решений при проектировании онтологии. “Цыплят по осени считают” – мы можем оценить качество нашей онтологии, только используя ее в приложениях, для которых мы ее разработали.
Благодарности Protege-2000 (http://protege.stanford.edu/) была разработана группой Марка Мьюсена (Mark Musen) в Stanford Medical Informatics[9]. Некоторые рисунки мы сделали с помощью OntoViz – плагина[10] к Protege-2000. Исходную версию онтологии вин мы импортировали из библиотеки онтологий Ontolingua (http://www.ksl.stanford.edu/software/ontolingua/), в которой, в свою очередь, использовалась версия, опубликованная Brachman и коллегами (Brachman et al. 1991) и распространяемая с системой представления знаний CLASSIC. Затем мы модифицировали онтологию, чтобы представить принципы концептуального моделирования для декларативных фреймовых онтологий. Подробные комментарии Рэя Фергесона (Ray Fergerson) и Мор Пелег (Mor Peleg) к ранним черновым вариантам значительно улучшили эту статью. Литература Booch, G., Rumbaugh, J. and Jacobson, I. (1997).The Unified Modeling Language userguide: Addison-Wesley. Brachman, R.J., McGuinness, D.L., Patel-Schneider, P.F.,Resnick, L.A. and Borgida, A. (1991). Living with CLASSIC: When and how to useKL-ONE-like language.Principles ofSemantic Networks. J. F. Sowa, editor, Morgan Kaufmann:401-456. Brickley, D. and Guha, R.V. (1999). Resource DescriptionFramework (RDF) Schema Specification. Proposed Recommendation, World Wide WebConsortium:http://www.w3.org/TR/PR-rdf-schema. Chimaera (2000). Chimaera Ontology Environment.www.ksl.stanford.edu/software/chimaera Duineveld, A.J., Stoter, R., Weiden, M.R., Kenepa, B. andBenjamins, V.R. (2000). WonderTools? A comparative study of ontologicalengineering tools.International Journalof Human-Computer Studies52(6):1111-1133. Farquhar, A. (1997). Ontolingua tutorial.http://ksl-web.stanford.edu/people/axf/tutorial.pdf Gуmez-Pйrez, A. (1998). Knowledge sharing and reuse.Handbook of Applied Expert Systems.Liebowitz, editor, CRC Press. Gruber, T.R. (1993). A Translation Approach to PortableOntology Specification.KnowledgeAcquisition5: 199-220. Gruninger, M. and Fox, M.S. (1995). Methodology for theDesign and Evaluation of Ontologies. In:Proceedings of the Workshop on BasicOntological Issues in Knowledge Sharing, IJCAI-95, Montreal. Hendler, J. and McGuinness, D.L. (2000). The DARPA AgentMarkup Language.IEEE IntelligentSystems16(6): 67-73. Humphreys, B.L. and Lindberg, D.A.B. (1993). The UMLSproject: making the conceptual connection between users and the information theyneed.Bulletin of the Medical LibraryAssociation81(2): 170. McGuinness, D.L., Abrahams, M.K., Resnick, L.A.,Patel-Schneider, P.F., Thomason, R.H., Cavalli-Sforza, V. and Conati, C. (1994).Classic Knowledge Representation System Tutorial.http://www.bell-labs.com/project/classic/papers/ClassTut/ClassTut.html McGuinness, D.L., Fikes, R., Rice, J. and Wilder, S. (2000).An Environment for Merging and Testing Large Ontologies.Principles of Knowledge Representation andReasoning: Proceedings of the Seventh International Conference (KR2000). A.G. Cohn, F. Giunchiglia and B. Selman, editors. San Francisco, CA, MorganKaufmann Publishers. McGuinness, D.L. and Wright, J. (1998). Conceptual Modelingfor Configuration: A Description Logic-based Approach.Artificial Intelligence for EngineeringDesign, Analysis, and Manufacturing - special issue on Configuration. Musen, M.A. (1992). Dimensions of knowledge sharing andreuse.Computers and BiomedicalResearch25: 435-467. Ontolingua (1997). Ontolingua System Reference Manual.http://www-ksl-svc.stanford.edu:5915/doc/frame-editor/index.html Price, C. and Spackman, K. (2000). SNOMED clinical terms.BJHC&IM-British Journal of HealthcareComputing&Information Management17(3): 27-31. Protege (2000). The Protege Project.http://protege.stanford.edu Rosch, E. (1978). Principles of Categorization.Cognition and Categorization. R. E. andB. B. Lloyd, editors. Hillside, NJ, Lawrence Erlbaum Publishers:27-48. Rothenfluh, T.R., Gennari, J.H., Eriksson, H., Puerta, A.R.,Tu, S.W. and Musen, M.A. (1996). Reusable ontologies, knowledge-acquisitiontools, and performance systems: PROTEGE-II solutions to Sisyphus-2.International Journal of Human-ComputerStudies44: 303-332. Rumbaugh, J., Blaha, M., Premerlani, W., Eddy, F. andLorensen, W. (1991).Object-orientedmodeling and design. Englewood Cliffs, New Jersey: Prentice Hall. Uschold, M. and Gruninger, M. (1996). Ontologies: Principles,Methods and Applications.KnowledgeEngineering Review11(2).
[1] Имена классов мы начинаем с большой буквы, а имена слотов – с маленькой. Также для всех терминов из онтологии, приведенной в качестве примера, мы используем шрифт печатной машинки.
[2] Мы также можем рассматривать классы как унарные предикаты – вопросы с одним аргументом. Например, «Этот предмет является вином?» Унарные предикаты (или классы) противоположны бинарным предикатам (или слотам) – вопросам с двумя аргументами. Например, «Этот предмет имеет сильный вкус?» «Какой вкус у этого предмета?»
[3] Некоторые системы только определяют тип значения с помощью класса и не требуют специальной формулировки для слотов-экземпляров.
[4] В нашей онтологии мы решили представить только красные вина Port: белые вина Port существуют, но они очень редко встречаются.
[5] Здесь мы предполагаем, что каждый анатомический орган является классом, поскольку мы также хотели бы говорить о «1-м левом ребре Джона». В нашей онтологии отдельные органы реально существующих людей будут представлены как индивидные концепты.
[1] В большинстве американских колледжей вступительный курс любого предмета имеет номер «101»: «Химия 101», «Биология 101» и т.д. Следующие два более углубленных курса по химии назывались бы «Химия 102» и «Химия 103» соответственно. В США номер «101» означает «Введение». Т.е., название статьи нужно понимать как «Введение в разработку онтологий: Руководство по созданию Вашей первой онтологии». (Здесь и далее в тексте примечания переводчика. Авторские примечания вынесены в конец статьи самими авторами.) [2] Буквально «является». [3] Буквально «вид, разновидность [чего-то]». [4] «Shrimp» и «prawn» - это синонимы, которые переводятся одинаково – «креветка». [5] Также переводится как «креветка». [6] «has» в данном случае можно перевести как «его». [7] В английском языке предлог «of» используется для отношений, которые в русском языке передаются родительным падежом без предлога. Поэтому использование этого суффикса для русскоязычных пользователей теряет смысл. [8] maker-of – производитель [чего-то], а winery-of – винный завод [по производству чего-то] [9] Stanford Medical Informatics (SMI) – университетская исследовательская группа кафедры медицины Школы Медицины при Стэнфордском университете. [10] Плагин (модуль расширения, подключаемый модуль) – дополнительный программный модуль, способный функционировать как составная часть основной программы.
Поиск по сайту: |